概述
此教程的目標是讓你熟悉 Stackdriver 的一些特定的功能, 它讓可以監控 GKE 叢集基礎設施, Istio, 以及部署在這些基礎設施上的應用
你將會做什麼?
- 建立一個 GKE 叢集
- 部署微服務應用到這個叢集上
- 為這個應用定義延遲 (latency) 以及錯誤 SLIs (Service Level Indicator), 以及 SLOs (Service Level Objective)
- 設置 Stackdriver 來監控你的 SLIs
- 部署一個致命的錯誤到你的應用, 然後使用 Stackdriver 來分析以及解決問題
- 驗證你的解法是否有處理掉 SLO 的違反
你將會學到?
- 如何部署微服務到一個已經存在的 GKE 叢集
- 如何為一個應用選擇適當的 SLIs/SLOs
- 如何使用 Stackdriver Monitoring features 來實作 SLIs
- 如何使用 Stackdriver Trace, Profiler, 以及 Debugger 來發現程式的問題
先決條件
- Google Cloud Platform 帳戶以及啟用 billing 帳戶的專案
- Kubernetes 基礎知識
- Stackdriver Monitoring 基礎知識
- 錯誤分析排除的基礎知識
環境設定
在你按下 Start Lab 按鈕之前
詳讀所有的教學。Labs 是有時間限制的,而且你不可以停止時間倒數。倒數計時器在你按下 Start Lab 按鈕後開始倒數,上面顯示的時間為你還能使用 Cloud 資源的時間。
Qwiklabs 的手把手環境,讓你可以在真實環境中來操作進行 Qwiklabs 上提供的課程,而不是在一個模擬或是展示的環境。我們透過提供你一個全新的、暫時的帳號密碼,在計時器歸零之前,你可以用來登入並存取 Google Cloud Platform。
你需要什麼?
要完成這個 lab ,你需要:
- 一個一般的網路瀏覽器(推薦 Chrome)
- 完成這個 lab 的時間
備註: 如果你已經有你自己的個人 GCP 帳號或專案,請不要使用在這一個 lab
現在你已經開始你的 lab, 你將會登入 Google Cloud Shell 主控台,然後開啟命令列工具
如何開始你的 lab ,然後登入 Console?
- 按下 Start Lab 按鈕。如果你需要付費,會有一個彈出視窗來讓你選擇付費的方式。在左方你會看到一個面板,上面有暫時的帳號密碼,你必須使用這些帳號密碼在此次 lab

- 複製
username, 然後點擊Open Google Console。 Lab 會開啟另外一個視窗,顯示選擇帳號的頁面
tip: 開啟一個全新的視窗,然後跟原本的頁面並排
- 在
選擇帳號頁面, 點擊Use Another Account

- 登入頁面開啟,貼上之前複製的
username以及password,然後貼上
重要:必須使用之前於 Connection Details 面板 取得的帳號密碼,不要使用你自己的 Qwiklabs 帳號密碼。 如果你有自己的 GCP 帳號,請不要用在這裡(避免產生費用)
- 點擊並通過接下來的頁面:
- 接受
terms以及conditions - 不要增加
recovery optoins或two factor authentication(因為這只是一個臨時帳號) - 不要註冊免費體驗
- 接受
稍待一些時候, GCP 控制台將會在這個視窗開啟。
注意:按下左上方位於Google Cloud Platform 隔壁的 Navigation menu ,你可以瀏覽選單,裡面有一系列的 GCP 產品以及服務

啟動 Google Cloud Shell
Google Cloud Shell 是載有開發工具的虛擬機器。它提供了5GB的 home 資料夾,並且運行在 Google Cloud 上。 Google Cloud Shell 讓你可以利用 command-line 存取 GCP 資源
- 在
GCP 控制台,右上的工具列,點擊Open Cloud Shell按鈕

- 在打開的對話框裡,按下
START CLOUD SHELL:

你可以立即按下 START CLOUD SHELL 當對話視窗打開。
連結並提供環境會需要一點時間。當你連結成功,這代表你已成功獲得授權,且此專案已被設為你的專案ID,例如:

gcloud 是 Google Cloud Platform 的 command-line 工具,他已事先被安裝在 Cloud Shell 並且支援自動補齊
使用這個 command ,你可以列出有效帳戶名稱:
gcloud auth list |
輸出:
Credentialed accounts: |
範例輸出:
Credentialed accounts: |
你可以使用以下 command 來列出專案 ID
gcloud config list project |
輸出:
[core] |
範例輸出:
[core] |
gcloud 的完整文件可以參閱 Google Cloud gcloud Overview
基礎設施配置
在本教程中, 你將會連接到 Google Kubernetes Engine 叢集然後驗證它有被正確的建立
在 gcloud 中設定 zone:
gcloud config set compute/zone us-west1-b |
設定 project ID:
export PROJECT_ID=$(gcloud info --format='value(config.project)') |
確認叢集 shop-cluster 已經被建立了
gcloud container clusters list |
如果你的叢集狀態顯示 PROVISIONING, 稍待一些時候, 並再次執行上面的指令, 直到狀態為 RUNNING
當你等待的時候, 設定你的 Stackdriver 工作區來監控你叢集中的應用。
建立 Stackdriver 工作區
在 Navigation menu, 點擊 Monitoring
當你可以看到 Stackdriver 的主控台, 這代表工作區已準備就緒。
回到 Cloud Shell 再次確認叢集是否已準備完成:
gcloud container clusters list |
一旦你看到叢集狀態顯示為 RUNNING, 取得叢集憑證
gcloud container clusters get-credentials shop-clusters --zone us-west1-b |
(輸出)
Fetching cluster endpoint and auth data. |
確認 nodes 已被建立
kubectl get nodes |
輸出應如下:
NAME STATUS ROLES AGE VERSION |
部署應用
在本教程中, 你將部署一個名為 Hipster Shop 的微服務到叢集中以建立一個可被監控的工作範例
執行以下指令來複製代碼:
git clone -b APM-Troubleshooting-Demo-2 https://github.com/blipzimmerman/microservices-demo-1 |
下載並安裝 skaffold
curl -Lo skaffold https://storage.googleapis.com/skaffold/releases/v0.36.0/skaffold-linux-amd64 && chmod +x skaffold && sudo mv skaffold /usr/local/bin |
使用 skaffold 安裝應用
cd microservices-demo-1 |
確認一切都正確運行著:
kubectl get pods |
輸出應類似如下:
NAME READY STATUS RESTARTS AGE |
在進到下一步之前, 重複執行指令直到所有的 pods 都顯示 RUNNING
取得應用的 external IP:
export EXTERNAL_IP=$(kubectl get service frontend-external | awk 'BEGIN { cnt=0; } { cnt+=1; if (cnt > 1) print $4; }') |
最後, 確認應用已啟動且運行:
curl -o /dev/null -s -w "%{http_code}\n" http://$EXTERNAL_IP |
注意: 如果回應是 500 錯誤, 你可能需要再次執行指令
確認回應應如下:
200 |
下載原始碼就將程式碼置於 Cloud Source Repo:
./setup_csr.sh |
現在你的應用已經部署完畢, 接下來我們設定應用的監控。
資源
Microservices Demo Application
注意: 本教程使用此應用的一個 fork 來幫助除錯
開發範例 SLOs 以及 SLIs
在我們實作任何監控之前, 複習一下 SRE 一書 中, 章節名稱為 Service Level Objectives 的介紹
服務架構

在不理解應用是怎麼建立的情況下, 是不太可能開發出 SLIs 的。 細節如原本的倉庫, 但在本教程中, 理解以下幾點便已足夠:
- 使用者透過 Frontend 存取應用
- Purchases 由 CheckoutServer 所處理
- CheckoutService 依賴 CurrencyService 處理轉換
- 其他服務像是 RecommendationService, ProductCatalogService, 以及 Adservice 被使用來提供渲染頁面需要的內容給 frontend
Service Level Indicators 以及 Objectives

設置延遲 SLI
現在你有定義完成的 SLOs 以及 SLIs, 你可以在 Stackdriver 來實作監控了。 那些你有興趣的指標已經被收集了。 你將為每一個 SLOs 建立警告政策。
前端延遲 (Front End Latency)
在 Stackdriver 頁面選擇 Alerting > Create a Policy
點擊 Add Condition, 接下來你將指定用來觸發警告政策的指標以及條件。 當有影響使用者體驗的性能方面的問題產生時, 這些條件將讓你知道有這些事情。
如同在 Service Level Indicators and Objectives 表格內敘述的, 你將使用第 99 的百分位數前端延遲作為 SLI
在 Find resource type and metric 欄位中數入以下值, 並從下拉選單中選擇如下:
custom.googleapis.com/opencensus/grpc.io/client/roundtrip_latency |
在 Resource Type 選擇 global 選項
點擊 Filter 欄位並選擇 opencensus_task 項。 點擊第一個預設值, 然後點擊 Apply
接下來, 將 Aggregator 設定為 99th percentile

接下來, 在 Configuration 區塊, 設定選項如下:
- Any time series violates 時觸發
- Condition: is above
- Threshold: 500
- For: Most recent value

點擊 Save
在下一個頁面, 下拉到底, 並且將 policy 命名為 “Latency Policy”, 然後點擊 Save, 你已經完成在 Stackdriver 監控 frontend latency SLI 的設置
設置可用性 SLI (Availability SLI)
接下來, 設置 Stackdriver, 建立另一個警告政策來監控服務可用性
前端可用性 (Front End Availability)
先由監控 front end service 的 error rate 開始, 因為這是會帶給使用者體驗最直接影響的地方。 如上所述, 你將會把任何的錯誤都列入違反 SLO 。 建立一個警告政策, 當觀察到任何錯誤時, 事件就會被觸發。
觸發特定錯誤的簡單方法之一, 就是使用基於紀錄的指標 (log-based metrics)
在 Stackdriver UI 介面中, 左側面板打開 Logging
針對 filter 做如下設置:
- 在 Resource type (第一個下拉選單) 選擇 Kubernetes Container
- Log Level 選擇 ERROR
- 在篩選器欄位輸入
label:k8s-pod/app:"currencyservice"

備註: 在這個頁面, 你不會看到任何結果, 因為目前服務正常的運行中。 很快的, 你將做一些變更來改變這個結果。
點擊 Create Metric
將指標命名為 “Error_Rate_SLI”, 然後點擊 Create Metric 來儲存紀錄指標:

現在你可以看到這個指標列在記錄指標的頁面。 點擊行末三個點的小圖案, 並點擊 Create Alert from Metric 來使用該指標建立警告政策

注意到 resource type 以及 metric 已經被填好了
將 condition 命名為 “Error Rate SLI”
點擊 Show Advanced Options 連結, 然後做如下設定:
- Aligner: rate
在 Configuration 的地方, 使用 0.5 唯一分鐘的觸發門檻
然後點擊 Save
在下一個頁面, 將新的政策命名為 “Error Rate SLI” 然後點擊 Save
如預料的, 並沒有錯誤發生。 因為你的應用目前有達到可用性 SLO
部署新的發佈
現在你已經設置好 SLI 監控, 也已經準備好測量應用變更對使用者體驗造成的衝擊。 讓我們來看看當部署一個新的應用發佈時會發生什麼事。
接下來, 你將修改 Kubernetes 的設定檔使服務有新的發佈, 然後運行 skaffold 來再次部署應用。
更新 YAML 檔案

找到 microservices-demo-1 資料夾, 打開裡頭的 kubernetes-manifests 資料夾
在 kubernetes_manifests/remommendationservice.yaml 檔案, 第 28 行, 使用下面的程式碼取代
image: gcr.io./accl-19-dev/recommendationservice:rel013019 |
舉例來說, 下面是 recommendationservice.yaml 的原始版本:

然後下面的是更新之後的:

在以下這些檔案中都做同樣的事:
kubernetes_manifests/currencyservice.yamlkubernetes_manifests/frontend.yaml
儲存並關閉檔案, 現在你已經可以部署新的版本了。
部署新的版本
在 Cloud Shell, 更新 deployment 來部署新的容器鏡像:
skaffold run |
確認新版本的服務正在運行著:
kubectl get pods |
(輸出)
NAME READY STATUS RESTARTS AGE |
傳送一些資料
現在應用已經在運行著, 回去看看你部署了什麼。
在主控台, 到 Kubernetes Engine > Services & Ingress, 尋找 frontend-external 服務並點擊 Endpoint URL
到 Hipster Shop 網站, 點擊 Buy 以及/或 Add to Cart 幾次來傳送一些流量。 等待 60 秒左右來產生足夠的延遲資料
延遲 SLO 違反 - 找出問題
在這個練習中, 你將使用 Stackdriver Application Performance Management (APM) 工具來找出已經解決造成應用嚴重延遲的問題
首先, 讓我們看看在我們部署新版之後, 是不是一切都 OK
在 Stackdriver 中選擇 Monitoring Overview, 在上方點擊 autorefresh arrows, 所以你將可以看到最新的資訊
一個 Latency Policy 事件不久後會出現, 如果還沒出現的話, 等它幾分鐘

在 Incident 區塊中點擊 Latency Policy 來檢視更多資訊。 你可能需要點擊 Resolved 區塊來檢視已經發生的警告
分析延遲問題的最佳解, 就是使用 Trace, 在左手邊的選單點擊 Trace

現在你的位置在主控台。 一開始的總覽的資訊挺有幫助的, 但你需要更進一步的資訊, 打開 Trace List 頁面

點擊 Auto Reload, 注意到頁面商方的散點圖, 在時間警告處有大量的異常紀錄。
等 1 或 2 分鐘讓資料搜集, 然後點擊其中一個 outlier traces 來檢視發生的細節。

注意到 Span name (代表被呼叫的 service 或 function) 為 /char/ 或 /char/checkout/
在 Request filter 欄位輸入 “Recv./cart” 來篩選所有的 cart 運作以及類似的追蹤, 這有助於了解它是如何比較事件發生前的紀錄以及發生後的紀錄。

設定時間範圍為 1 hour, 所以顯示資料會包括事件發生前的資料

點擊事件發生前的一筆資料來看看

可以看到, 這個類似的紀錄 ListRecommendations 在此只被呼叫了一次。 然而, 在我們最新的部署之後, ListRecommendations 在每一次的請求都被呼叫了很多次, 造成了很嚴重的額外延遲
至此, 我們可以總結, 這些異常值造成的原因是因為 ListRecommendations 的多次呼叫。
部署變更來處理延遲
為了解決上一次部署所產生的延遲問題, 你需要部署另外一個版本來修復損壞的程式碼。 你將會修改 Kubernetes 的設定檔, 含有損壞程式碼服務的設定檔
要部署修復, 回到 Cloud Shell 頁面, Source Code Editor 應該還是開啟的。 你將會修改以下檔案:
kubernetes_manifests/recommendationservice.yamlkubernetes_manifests/frontend.yaml
將鏡像的標籤 rel013019 修改成 rel013019fix, 所以 鏡像 看起來應如下:
containers: |

儲存 檔案
回到 Cloud Shell 並執行以下指令重新部署修復過的鏡像:
skaffold run |
核對修復
現在你已經部署了修復的版本, 核對一下你的應用是否已回到健康的狀態
回到 Stackdriver* 並到 **Metrics Explorer (Resources > Metrics Explorer)
在搜尋欄位, 輸入 latency 並點擊 roundtrip_latency

將圖表類型變更為 Line, 你應該看到圖表中的 latency 數值有立即明顯的下降 (如果沒有的話, 可能要等個一分鐘)

現在, 回到 Monitoring Overview 看看事件是否已經解除了。
你應可發現兩件事 - 原本的 incident 也經不存在了, 且會有 event 通知說原本的 incident 已經被解除了。
同樣的, 如果你沒看到 incident 解除的訊息, 等個幾分鐘吧。

你的監控可以正確的辨識出造成使用者體驗下滑的變更 (如同我們上面的檢測, 是由延遲造成的), 你也可以辨識出真正產生問題的原因, 且你也回滾了這段損壞的變更。 在下一個章節, 看看 Stackdriver 是如何幫助我們解決可用性 (availability) 的問題。
錯誤率 SLO 違反 (Error Rate SLO Violation) - 找出問題
在這個練習中, 你將使用 Stackdriver Application Performance Management 工具 (APM) 來排查一些在你的應用之中造成錯誤, 並且超出了你設定的錯誤限制的問題
先到 Stackdriver 的 Monitoring Overview
尋找 Error Rate SLI incident, 然後點擊 incident 來了解發生了什麼事。 incidents 可能會需要幾分鐘的時間來被確認, 並且列在 incident 中。 如果還沒有看到有 incident, 你可以先跳過 incident 步驟, 然後在左手邊選單處點擊 Error Reporting
你可以看到 currencyservice pod 正紀錄比之前多很多的錯誤。
點擊 Acknowledge incident, 所以針對事件的通知不會持續累積
像這種類型的警告, 也很多方式可以達成, 但最簡單的方式是使用 Stackdriver Error Reporting, 在左手邊選單點擊 Error Reporting
可注意到 Open Error Reporting 顯示有一個最新的數據急遽上升。 點擊 Error: Conversion in Zero 來檢視更多錯誤問題
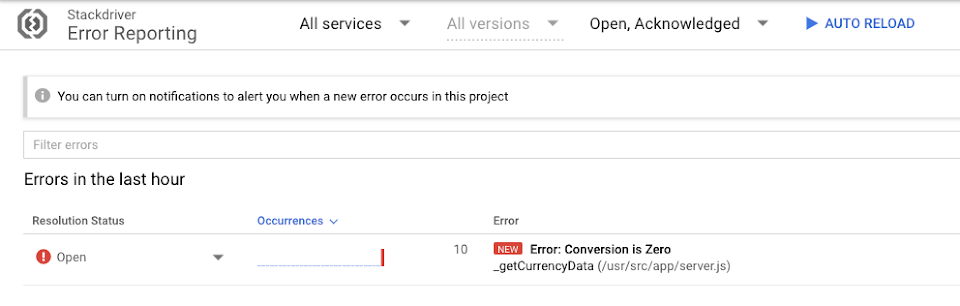
在右手邊可看到 Stack Trace 樣本, 你可以從這看到哪些特定的呼叫是跟錯誤相關的

點擊 最下面的呼叫, 如 /usr/src/app/server/js:131 顯示
這會將你導向 Stackdriver Debug, 在頂部的欄位確認 currency service 有被選擇

接下來, 從 Cloud Source Repositories 選擇正在運行的程式碼

依照以下條件選擇 source
- Repository: apm-qwiklabs-demo
- Tagged version or branch: APM-Troubleshooting-Demo-2
然後點擊 Select Source
在左手邊選單選擇 /src/currencyservice/server.js

往下捲動到 155 行左右, 這邊是 exception 被拋出的地方。 你可以看到錯誤回報功能正是回報 Conversion is Zero 這一個錯誤紀錄

從上面的程式碼可以看到, 當 result.units < 0 時會記錄這個 error, 而要排除這個問題, 你將使用 Snapshots 來檢查當應用運行中變數的值。
確認你已經在右上方選擇了 Snapshot

然後點擊你想要快照的地方, 行數 (155)

在此練習中, 在行數 155, 141, 以及 149 的地方快照, 你也可以在任何你覺得適當的地方加入快照。 系統將會在下一次程式碼運行時, 對變數進行快照。 當應用正在等待程式碼運行時, 你可以看到 “Waiting for snapshot to hit …” 提示。
當快照完成, 右手邊將顯示指定快照處的變數

可以看到 Variable 以及 Call Stack 資訊。 這些資訊可以讓你了解到你的程式碼執行的路線是怎麼走的, 以及在執行的路線上的程式碼結構以及變數, 我們完全不需要重啟應用或變更任何程式碼來獲得這些資訊。
點擊 result 來檢視在 155 行結束的 3 個快照。 根據上面的資訊我們知道當 result.units 不大於 0 時, 會觸發錯誤。 檢視一下變數你可以看到 result.units = NaN (代表 ‘不是一個 number’), 這就是造成錯誤的原因

現在你可以下結論, 這個錯誤是因為設定 result.units 為 0 的 convert function (或子 function) 出 bug, 你的錯誤排除程序依據快照所提供的資訊以及紀錄是一個很確實地針對問題的診斷。
所以造成問題的 bug 是什麼? 從程式碼可以看到, result.units 由 euros 在第 114 行設定, 而 euros 在第 136 行 from.units 被設定

檢視快照中的 euros.units 也是 NaN, 然而, from.units 是個合法的數字。 因此問題是在轉換 from.unit 到 euros 時發生的。

你可以歸納, 根本原因為 from.units 在 137 行是如何被轉換成 euros.units, 8 被帶入 Data[], 這事實上是一個 key value 的指向, currency units (像是 EUR) 到 exchange rates, 正確的 137 行應該要使用 from.to_currency (即 USD), 而非 from.units (即 8)

現在你已經確定產生 bug 的原因, 並且也可以做出相對應的修正。 根據警告的時間點, 這可能是在最近的部署上產生的。
看看之前的 “Master” 分支上, 在 137 行有沒有這個錯誤
回到主控台, 使用 Cloud Source Repositories (在主控台選單的 Tools 分類下) 來檢視程式碼
打開 apm-qwiklabs-demo repository, 選擇 master 分支
從左手邊至 *src > currencyservice > server.js, 注意到第 137 行有使用正確的被除數 data[from.currency_code]

現在你已經可以確定這個 bug 是由最新的 push 所造成。 當務之急, 我們先要回到前一個版本去。
部署變更來解決 Error Rate
要解決這個問題, 你需要部署一個修復到應用上。 為了做到這一點, 你將需要更改 Kubernetes 的設定檔中, 包含有錯誤程式碼的服務。
部署修復
回到 Cloud Shell, 然後在 Source Code Editor 打開 kubernetes_manifests 資料夾中的 currencyservice.yaml 檔案

將 image tag_re1013019_ 替換成 re1013019fix, 所以 image 應看起來如下:
containers: |
關閉 檔案並儲存, 回到 Cloud Shell 視窗
重新部署帶有修復代碼的鏡像:
skaffold run |
核對修復
現在你已經回滾了錯誤的代碼, 確認一下應用是否有回到健康的狀態。
如同上面的步驟, 先核對一下 incident 是否已經解決了。 到 Stackdriver UI Monitoring Overview 確認一下 error rate incident 是否已經解決了。 現在, 應該是沒有 open incident 了。

接下來, 回到 Error Reporting, 打開之前觀察的錯誤, 然後確認錯誤已經沒有再出現了 (時間軸應會顯示從上一次部署到現在已經都沒有錯誤發生了)

恭喜! 你的監控可以正確地發現造成使用者體驗下降的變更代碼 (經由量測應用錯誤而得來的數據), 且你可以找出根本的原因, 然後回滾錯誤的程式碼。
讓我們進到下一個章節, 學習怎麼樣使用 Stackdriver 來優化資源利用
使用 Stackdriver APM 來優化應用
在這個練習中, 你將使用 Stackdriver Application Performance Management 工具 (APM) 來尋找你的應用可能的改善空間, 讓它運行的更快速, 使用更少的資源。
在這個情境中, Director of Cloud Operations 對最近的運算成本上升感到非常失望。 特別是, 根據系統的使用量來看, currencyservice 使用了超出預期的 CPU
你的團隊已經被賦予了優化的任務。 APM 工具將被使用來分析服務, 並且確保你的團隊可以將心力集中在對的地方。
從主控台左手邊選單打開 Stackdriver Profiler

變更右上方的 Timespan 到 30 分鐘。 如果還沒有資料的話, 等個 1 到 2 分鐘讓資料載入
注意: Profiler 提取隨機的呼叫樣本來建立一個總和的呼叫堆疊。 如果你沒有看到你預期中的資料, 那可能是因為本教程運行的時間還不足, 或是你的進度比預期的要快。 可以在本次練習中多多使用 screenshots
在 filter 的 service 欄位選擇 frontend, 然後在 Profile type 欄位選擇 CPU time

Profiler 提取隨機的系統頗析樣本, 並且融合這些資料, 顯示出哪些功能使用了最大量的資源。 下面的火焰圖顯示了由使用的資源分組 (在這個案例中, 資源為 CPU) 過的 function 呼叫, X 軸為 CPU 的總量, Y 軸為父子關係

在這個案例中, 在左手邊的 ServeHTTP 呼叫使用了大部分的 CPU, 點擊這個呼叫, 進一步搜索原因。

展開的圖表顯示了有一半的呼叫是由 viewCartHandler 相對應的 getRecommendations 所造成。
所以可能可以下手的地方是 getRecommendations 以及其相對應的 getProduct, 回想一下之前的練習, recommendation service 以及 getProduct 在迴圈內被頻繁的呼叫, 因為在蟲試邏輯中有錯。 解決這個問題之後, 將可以減少運算成本達 20%
恭喜
你已完成本教程
留言