# 前言
如果可以過目不忘, 那可能就不用寫 Blog 了…
# 未開始先談移除
打開 terminal
使用 mysqldump 備份你的資料庫
mysqldump -u你的使用者名 -p --all-databases > /tmp/backup.sql
尋找是否還有 MySQL process, 若有的話, 使用
kill -9 processId砍掉ps -ax | grep mysql
若使用 brew, 使用 brew 刪除
brew remove mysql
brew cleanup移除以下檔案
sudo rm /usr/local/mysql
sudo rm -rf /usr/local/var/mysql
sudo rm -rf /usr/local/mysql*
sudo rm ~/Library/LaunchAgents/homebrew.mxcl.mysql.plist
sudo rm -rf /Library/StartupItems/MySQLCOM
sudo rm -rf /Library/PreferencePanes/My*卸載之前的 MySQL 自動登入
launchctl unload -w ~/Library/LaunchAgents/homebrew.mxcl.mysql.plist
移除之前的 MySQL 設定
vim /etc/hostconfig
# Remove the line MYSQLCOM=-YES-移除以下檔案
rm -rf ~/Library/PreferencePanes/My*
sudo rm -rf /Library/Receipts/mysql*
sudo rm -rf /Library/Receipts/MySQL*
sudo rm -rf /private/var/db/receipts/*mysql*重啟電腦, 確保沒有任何程序在跑
執行 mysql, 應該不能執行
# 使用者帳號及權限
建立使用者
CREATE USER 'userName'@'userHost' |
更改使用者名稱
RENAME USER 'userName'@'hostName' TO 'newUserName'@'newHostName' |
更改使用者密碼
SET PASSWORD FOR 'userName'@'hostName' = 'newPassword' |
顯示特定使用者權限
SHOW GRANTS FOR 'userName' |
賦予已建立的使用者權限
- SQL 敘述:
GRANT ALL ON 'databaseName'.'tableName' TO 'userName'@'hostName'
GRANT SELECT (columnName1, columnName2, ...) ON 'databaseName'.'tableName' TO 'userName'@'hostName' - 備註:
需注意, 在 MySQL 8, username 加上 hostName 視為一個完整的 GRANT 對象, 如果 hostName 不同, 即使 userName 相同, 對 GRANT 來說也是不同對象
顯示所有 user 以及 host
SELECT User, Host |
刪除使用者
- SQL 敘述:
DROP USER 'userName'@'hostName';
- 備註:
需注意, userName 加上 hostName 視為一個完整 user 對象, 若有多個 host, 需下多次指令刪除
賦予權限
GRANT SELECT, INSERT, UPDATE, DELETE ON databaseName.tableName |
權限表
| 權限 | 說明 |
|---|---|
| ALL [PRIVILEGES] | 一次賦予所有基本權限。不需附加 GRANT 的各種選項。 |
| ALTER (變換) | 允許使用 ALTER TABLE 敘述, 但授權時亦須同時賦予 CREATE 和 INSERT 等權限。 如需替資料表更名時, 還要搭配 DROP 權限。 此權限有一定的風險: 某人可能透過更名資料表來倒取使用權 |
| ALTER ROUTINE | 允許使用者帳號變換或棄置 (DROP) 預儲常式 (STORED ROUTINES)。 這其中包括了 ALTER FUNCTION 和 ALTER PROCEDURES 兩道敘述。 |
| CREATE | 允許執行 CREATE TABLE 敘述。 注意還需要有 INDEX 權限才能定義索引。 |
| CREATE TEMPORARY TABLES | 允許使用 CREATE TEMPORARY TABLES 敘述 |
| CREATE USER | 允許使用者帳號執行數種與管理使用帳號相關之敘述: 如 CREATE USER 、 RENAME USER 、 REVOKE ALL PRIVILEGES 、 以及 DROP USER 等敘述。 |
| CREATE VIEW | 允許執行 CREATE VIEW 敘述 |
| DELETE | 允許執行 DELETE 敘述 |
| DROP | 允許使用者執行 DROP TABLE 和 TRUNCATE 兩道敘述 |
| EVENT | 允許使用者帳號為事件排程工具定義事件。 包括 CREATE EVENT, ALTER EVENT 和 DROP EVENT 等敘述 |
| EXECUTE | 允許以 EXECUTE 敘述執行預報程序 (STORED PROCEDURES) |
| FILE | 允許使用 SELECT … INTO FILE 和 LOAD DATA INFILE 等敘述以便將資料會出成檔案, 或是從檔案匯入。 此權限也暗藏安全風險。 應該限定僅可在 SECURE_FILE_PRIV 變數中指定的特定目錄下執行 |
| INDEX | 授權使用 CREATE INDEX 和 DROP INDEX 等敘述 |
| INSERT | 允許執行 INSERT 敘述。 要先擁有此一權限才能執行 ANALYZE TABLE, OPTIMIZE TABLE 和 REPAIR TABLE 等敘述 |
| LOCK TABLES | 允許使用者對已有 SELECT 權限的資料表執行 LOCK TABLES 權限 |
| PROCESS | 允許使用 SHOW PROCESSLIST 和 SHOW ENGINE 等敘述 |
| RELOAD | 允許下達 FLUSH 敘述 |
| REPLICATION CLIENT | 允許使用者查詢主副伺服器 (MASTER AND SLAVE) 的狀態資訊, 如 SHOW MASTER STATUS 和 SHOW SLAVE STATUS 以及 SHOW BINARY LOGS 等敘述 |
| REPLICATION SLAVE | 這是複寫副伺服器 (REPLICATION SLAVE SERVER) 所必需的權限, 目的是要從主伺服器讀取二進位事件紀錄 (BINARY LOG EVENTS) |
| SELECT | 允許執行 SELECT 敘述 |
| SHOW DATABASES | 允許對所有資料庫使用 SHOW DATABASES 敘述, 而且不限於使用者有權使用的資料庫 |
| SHOW VIEW | 允許使用 SHOW CREATE VIEW 敘述 |
| SHUTDOWN | 允許 MYSQLADMIN 工具程式搭配 SHUTDOWN 選項執行 |
| SUPER | 授權執行 CHANGE MASTER TO, KILL, PURGE BINARY LOGS 及 SET GLOBAL 等敘述, 並且允許 MYSQLADMIN 工具程式搭配 DEBUG 選項執行 |
| TRIGGER | 此權限授權使用者帳號得以建立或棄置觸發器 (TRIGGERS), 亦即可以使用 CREATE TRIGGER 和 DROP TRIGGER 等敘述 |
| UPDATE | 允許執行 UPDATE 敘述 |
| USAGE | 新建使用者時引用此關鍵字, 可達到完全不賦予權限, 或是在修訂現有使用者資料時不會動到既有權限的效果 |
建立賦予權限的帳號
GRANT specifiedPrivileges ON databaseName.tableName |
收回已賦予的權限
REVOKE specifiedPrivileges |
建立 Role
CREATE ROLE 'roleName'; |
然後可以賦予 role 權限
賦予使用者 Role 權限
GRANT 'roleName' TO 'userName'@'hostName'; |
切換 Role
## 切換 |
# 資料備份
備份所有資料庫
mysqldump --user=specifiedUserAndHostName \ |
備份指定資料庫
mysqldump --user=specifiedUserAndHostName --password --lock-tables \ |
備份參數參考
使用以下選項, 可以縮小 dump 檔
–skip-add-drop-table: 忽略 會清除舊資料表的 DROP TABLE 敘述
–skip-add-locks: 開始備份時不先鎖定資料表
–skip-comments: 檔案裡不加註解
–skip-disable-keys: 略過 會處理資料表索引的指令
–skip-set-charset: 略過 指定使用字元集的 SET NAMES 敘述
–compact: 使用上述所有選項
–user: 要求 mysqlsump 使用 admin_backup 這個帳號與 MySQL Server 互動
–password: 指定使用帳號的密碼
–lock-all-tables: 在開始備份前, 把所有資料庫中的所有資料表鎖定
–lock-tables: 在開始備份前, 先把該資料庫中所有資料表鎖定
–all-databases: 指定匯出所有資料庫
–extended-insert: 會把每個資料表所需的多筆 INSERT 敘述濃縮成一句, 可縮小備份檔以及增進回原效率
–skip-extended-insert: 若 server 預設有 --extended-insert 效果, 但想看到一筆筆的 INSERT 敘述, 可以使用此選項
–ignore-table: 略過指定 table, 通常會略過 mysql.user table, 該 table 會用特殊帳號備份
–no-create-info: 不包含 create 敘述
–no-data: 只備份架構, 不備份資料
–verbose: 在備份過程中, 把重大步驟產生的訊息顯示出來
–replace: 使用 replace 代替 insert
# 資料還原
# dump file 還原
從 dump file 還原
mysql --user=performingOperationUser --password < dumpFileName.sql |
復原部分資料
- 修改 dump file, 只留下開頭, 結尾變數, 以及需要的 table 段落
- 修改 dump file 中的
create database, use database, 改成一個臨時的 database name, 匯出後在從該臨時 database 中取出資料, 完成後再刪掉該 temporary database - 或是賦予一個臨時使用者該 table 的權限, 讓這個使用者去執行 restore
# 從 Binary Log 還原
如果很不幸的, 你想要還原備份後才新增的資料
確認 Binary Log 是否有啟用
SHOW BINARY LOGS |
啟用 binary log
在 mysql.ini / mysql.cnf 檔案中:
# log-bin 表示啟動 binary log |
顯示當前 log 點
SHOW MASTER STATUS; |

Binlog_Do_DB: 指定哪些資料庫才要記錄到 binary log
Binlog_Ignore_DB: 指定哪些資料庫不要記錄到 binary log
Executed_Gtid_Set: 已經執行的 transaction 編號
取得 DATA 存在位置
SHOW VARIABLES WHERE Variable_Name LIKE 'datadir'; |

確定 log 檔案確實在該目錄底下後, 輸出文字檔
mysqlbinlog --database=databaseName \ |
找出問題點
手動找出問題點, 如下 example
# at 1258707 |
復原備份到問題點前
可看到從 position point 1258707 開始了含有 DELETE 的 transaction, 現在我們要將資料復原, 並拿掉這個含有 DELETE 的 transaction
先復原到 position 1258707:
mysqlbinlog --database=databaseName--stop-position="1258707" \ |
從問題點後開始復原到最新的 log point
可看到有問題的 transaction 的結尾落在 1284862, 並且有指出下一個起始點為 1284889, 因此可從 position 1284889 開始往後復原
mysqlbinlog --database=rookery --start-position="1284889" --to-last-log \ |
至此就大功告成啦!
# 中文亂碼問題
# 先確認 locale 狀態:
確認 charset 狀態, 在 mysql 當中: ```bash
show variables like ‘char%’;2. 確認 `database` locale 狀態:
```bash
SELECT default_character_set_name FROM information_schema.SCHEMATA
WHERE schema_name = "databaseName";確認
tablelocale 狀態:SELECT CCSA.character_set_name FROM information_schema.`TABLES` T,
information_schema.`COLLATION_CHARACTER_SET_APPLICABILITY` CCSA
WHERE CCSA.collation_name = T.table_collation
AND T.table_schema = "databaseName"
AND T.table_name = "tableName";確認
columnlocale 狀態:show full columns from tableName;
確認
collationshow variables like 'collation%';
# locale 修改
# 確認 mysql 設定檔位置並修改
取得 ‘my.cnf’ 位置, 通常,檔案會在
/etc/mysql/my.cnfmysql --help -verbose | grep 'my.cnf'編輯檔案
vim /etc/mysql/my.cnf
貼上以下設定
[client]
default-character-set=utf8mb4
[mysql]
default-character-set=utf8mb4
[mysqld]
collation-server = utf8_unicode_ci
init-connect='SET NAMES utf8'
character-set-server = utf8mb4
# 修改 database locale
ALTER DATABASE database_name CHARACTER SET utf8 COLLATE utf8_general_ci; |
# 修改 table locale
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8; |
# 完成修改後, 重啟 mysql
service mysql restart |
# 別忘了 PHP locale
如果有用使用 PHP 的話,記得也將 PHP 那邊的 locale 設為 uft8, 可參考文章
mysqli_set_charset($dbc,"utf8"); |
# 還是亂碼?
理論上,上面的都做完了,應該就不會有亂碼了,如果問題尚未解決,可以試試下面的方法
查看資料庫 locale 設定
show create database databaseName
查看 table locale 設定
show create table tableName
其餘設定
set names uft8;
# 匯入大量資料
# 修改 my.cnf 或 my.ini 檔 (永久性的放寬)
[mysqld] |
# 暫時性的放寬
set global net_buffer_length=1000000; |
set global max_allowed_packet=1000000000; |
# 匯入
# 從 sql 檔匯入
mysql --max_allowed_packet=100M -u root -p database < dump.sql |
如果已有設定, --max_allowed_packet 可不加
# 從 csv 匯入
# 一般 csv 格式
LOAD DATA INFILE '/tmp/Clements-Checklist-6.9-final.csv' |
從 csv 檔讀取資料並匯入 database.table
FIELD TERMINATED BY: field 跟 field 之間由 , 區隔開來
OPTIONALLY: 有則處理, 沒有則不執行
ENCLOSED BY: 使用 ENCLOSED BY '"', 當 " (doube quote) 有出現時, 會將兩個 " (double quote) 之間的內容視為一個 column 的內容, 若沒出現則不使用, 為了應付某些 filed 的內容其實是 text, 會用 " (double quote) 包住, 但內容有許多 ,(comma)
IGNORE 1 LINES: 表示忽略第一行, 因為第一行是 field name, 我們並不會用到
@niente: 因為 csv 檔中某些欄位的資料我們並不需要, 因此在建立 table 時只需要建立我們需要的 column, 在匯入時, 將沒用到的 fieldd 按照 csv 上的順序標示為 @niente (只要是變數就行, 名稱不重要), 這樣就不會將資料匯入啦
@family, SET family: 可以在 LOAD DATA 的過程中, 針對 csv 上特定的 column 做處理, 匯入完成後就已經會是處理好的
# 較特別的 csv 格式
格式範例:
["prospect name"|"prospect email"|"prospect country"] |
sql example:
LOAD DATA INFILE '/tmp/birdwatcher-prospects.csv' |
以下為 FIELDS 子句意思:
TERMINATED BY: 表示 | 為 field 跟 field 之間的間隔
ENCLOSED BY: 表示每一個 field 的內容都會由 " 包住
ESCAPE BY: 標示跳脫用字元, 不過預設就是 \, 因此這個可省略
LINES 子句:
STRINGS BY: 表示 [ 開頭算一行的開始
TERMINATED BY: 表示 ]\r\n 為一行的結束, 正常 Linux 只需 \n 即可, 但考量到 Windows 環境, 因此多加了 \r
使用 mysqlimport
mysqlimport –user='marie_dyer' --password='sevenangels' \ |
基本上語法跟 LOAD DATA 是一樣的, 差別在於檔名若有 - 要改成 _, 以免 MySQL 判定為刪減符號
以下為 FIELDS 子句意思:
TERMINATED BY: 表示 | 為 field 跟 field 之間的間隔
ENCLOSED BY: 表示每一個 field 的內容都會由 " 包住
ESCAPE BY: 標示跳脫用字元, 不過預設就是 \, 因此這個可省略
LINES 子句:
STRINGS BY: 表示 [ 開頭算一行的開始
TERMINATED BY: 表示 ]\r\n 為一行的結束, 正常 Linux 只需 \n 即可, 但考量到 Windows 環境, 因此多加了 \r
# 大量匯出
( SELECT 'scientific name','common name','family name' ) |
使用 SELECT INTO OUTFILE 將資料匯出, 子句部分語法跟 LOAD DATA 完全一樣
需使用 IFNULL 將 null 轉為空字串, 因為 INTO OUTFILE 預設會將 null 轉為 n
以下為 FIELDS 子句意思:
TERMINATED BY: 表示 | 為 field 跟 field 之間的間隔
ENCLOSED BY: 表示每一個 field 的內容都會由 " 包住
ESCAPE BY: 標示跳脫用字元, 不過預設就是 \, 因此這個可省略
LINES 子句:
STRINGS BY: 表示 [ 開頭算一行的開始
TERMINATED BY: 表示 ]\r\n 為一行的結束, 正常 Linux 只需 \n 即可, 但考量到 Windows 環境, 因此多加了 \r
匯出範例:
"scientific name"|"common name"|"family name" |
# 查單一資料庫 size
SELECT table_schema "databaseName", ROUND(SUM(data_length + index_length) / 1024 / 1024, 1) "DB Size in MB" FROM information_schema.tables where table_schema="databaseName" GROUP BY table_schema; |
# where 子句操作符

# EXTRACT 支援的時間格式

# DATE_FORMAT, TIME_FORMAT 時間格式碼

# Index
# 加入 Foreign Key
ALTER TABLE tableName |
# 移除 Foreign Key
# 取得 constraint
SELECT * FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS |
# 移除 constraint
ALTER TABLE table_name |
# 移除 index
ALTER TABLE table_name |
# 取得 metadata
取得 table rows 大約估計值
SELECT table_rows FROM information_schema.tables WHERE table_name = 'tableName' |
# Questions and Answers
以下的 MySQL example code, t2 上最後一筆資料的 id 是多少?
- Example:
insert into t values(null, 1,1);
insert into t values(null, 2,2);
insert into t values(null, 3,3);
insert into t values(null, 4,4);
create table t2 like t;
insert into t2(c,d) select c,d from t;
insert into t2 values(null, 5,5); - Answer:
8, 因為 id 的申請是倍數增加的
第一次, 申請到 1 個 id
第二次, 申請到 2 個 id
第三次, 申請到 4 個 id, 至此, 已有 7 個 id, 但只需 insert 4 筆資料, 所以 5~7 沒用到
MySQL 不會去回滾已取得的 increment id, 所以最後一筆申請到的 id 會是 8
MySQL 中, 對於批量插入數據的語句, 像是 insert ... select, 申請 increment id 的規則是?
首次, 1 個 id
第二次, 2 個 id
第三次, 4 個 id
第四次, 8 個 id
以此類推, 因為在不知道有幾筆的情況下, 一筆筆申請的效率太低了, 如果需要 insert 一百萬筆的話
MySQL 中, 為了避免 insert...select 這樣的語句造成主從的 increment id 不一致, 以及不影響高併發的效能, 建議 innodb_autoinc_lock_mode 以及 binlog 的格式做怎樣的設置?
innodb_autoinc_lock_mode 設為 2, 即立即釋放, 不影響高併發效能
binlog 設為 row, 解決主從不一致的問題
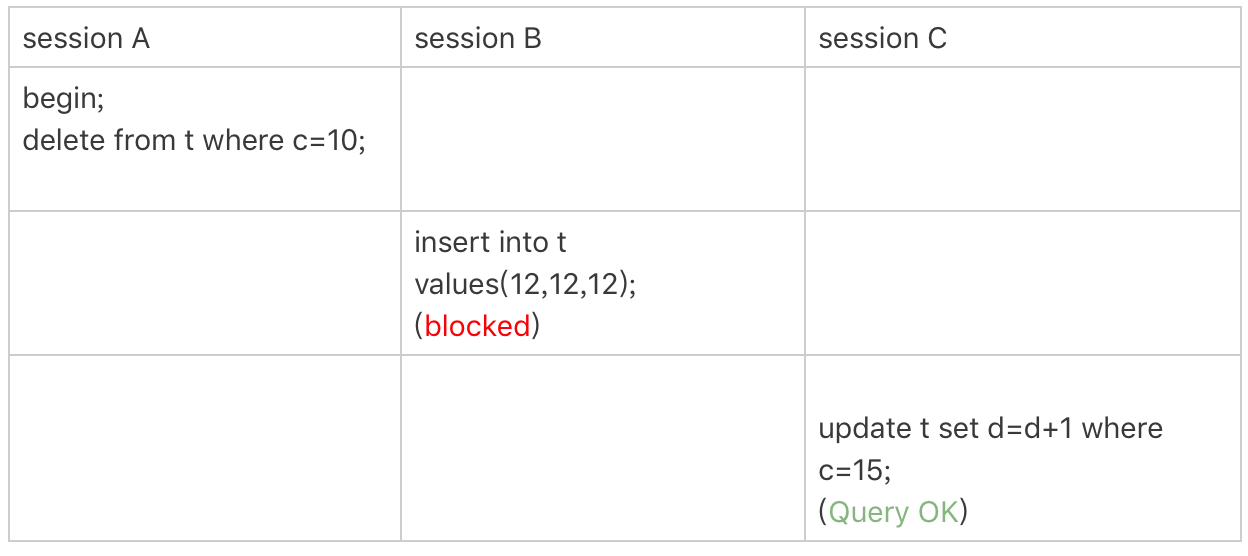
以下的 MySQL example image 中, 若 session B 的 insert...select 沒有 lock, 那可以取得連續 id 嗎?
- Example:
- Answer:
不可

MySQL 中, 參數 ‘innodb_autoinc_lock_mode’ 為什麼在 5.7 的版本中, 預設值是 1, insert ... select 這種不確定要申請多少 id 的語句會在語句執行完畢後才釋放 increment id lock?
若是不上鎖, 在 binlog 格式為 row 時不會有問題, 因為 row binlog 是實際去記錄每一個 row 的實際紀錄
使用 statement binlog 時, 如果不上鎖的話, 在併發時並無法保證 insert ... select 語句在 insert 時可以取得連續的 id, 但 statement binlog 執行時是沒有併發的問題, 因此可以取得連續 id, 這就造成主從不一致
MySQL 中, 參數 ‘innodb_autoinc_lock_mode’ 在 MySQL 8 的預設值是多少?
2
MySQL 中, 參數 ‘innodb_autoinc_lock_mode’ 根據設置的值不同, 會有哪三種行為?
(0) 所有的語句在申請 increment id 時都上鎖, 語句執行完畢才釋放
(1) 一般語句取得 id 後立即釋放, insert ... select 這種不確定要申請幾個 id 的語句, 要等到語句全部執行完畢才釋放
(2) 所有語句都在申請取得後立即釋放
MySQL 中, 為什麼不支援自增 id 回退?
會影響效能
假設 transaction a 取得 id 2, transaction b 取得 id 3, a 提供失敗, b 提交成功, 如果支援回退的話, 這時 InnoDB 的當前自增 id 會修正為 2, 結果出現資料庫內有 id = 3 的資料, 而當前自增 id = 2, 之後的 transaction 如果申請到 id = 3, 就會發生衝突
為解決這個問題, 方法有 2
(1) id 沒出現在資料庫才給申請, 這相當於每一次都要表搜索, 效能不佳
(2) 自增鎖粒度加大, 一個事物完成並提交才給申請下一個 id, 這會影響併發能力
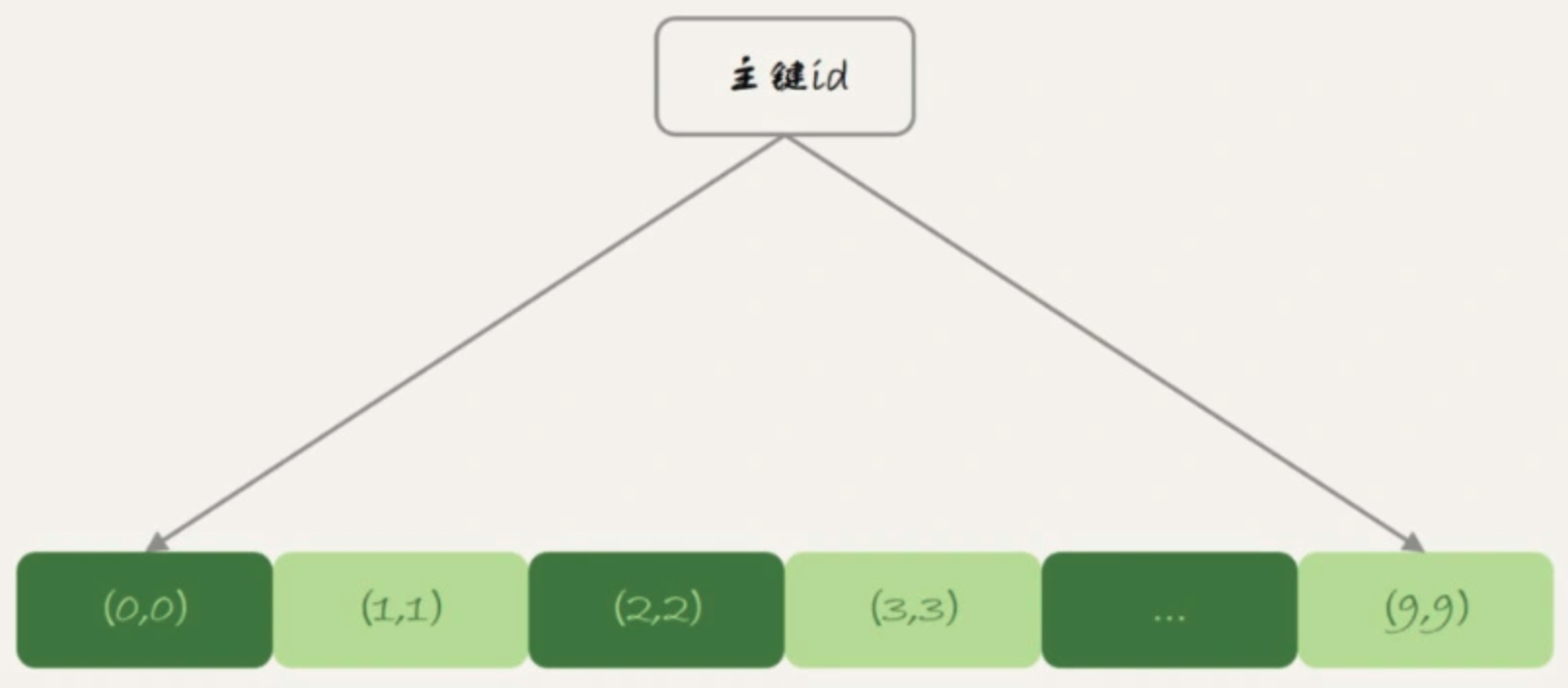
以下的 MySQL example code 中, 最後插入的 id 是多少?
- Example:
insert into t values(null,1,1);
begin;
insert into t values(null,2,2);
rollback;
insert into t values(null,2,2); - Answer:
3
以下的 MySQL example code 中, 為什麼 id 是 3, 不是 2?
- Example:
- Answer:
InnoDB 發現用戶沒有指定自增 id 的值, 獲取當前的值並導入 insert query
將當前的值改成 3

以下的 MySQL example code 的意思是?
- Example:
create temporary table temp_t(id int primary key, a int, b int, index (b))engine=memory;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b); - Answer:
使用 temp table 優化 join 時, 用 memory engine table 來代替 InnoDB engine table, 速度會更快
以下的 MySQL example code, 使用 memory engien 改寫是否會更好?
- Example:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b); - Answer:
會, 因為 memory engine table 使用 hash index, 等值查詢更快
2000 筆紀錄不大, 可全部放在內存
memory engine table 不需寫 disk, 速度更快
MySQL 中, 對比 memory table 以及 InnoDB table, 為什麼說 InnoDB 更適合被使用?
- 若資料量大, InnoDB 併發效果較好
- 若資料量小, InnoDB 的資料也是會緩存在 buffer pool 中的
MySQL 中, 為什麼說正式環境不適合使用 memory engine table?
- memory engine table 不支援行鎖, 併發效果不好
- 因為斷開或重啟後會清空資料, 會造成主從同步停止, 甚至清空主庫 memory table
MySQL 的 memory table 支援行鎖嗎?
不支援, 只支援表鎖
以下的 MySQL example code 的意思是?
- Example:
- Answer:
加入 btree 到 memory, 不同 index 造成排列順序的不同

MySQL 中, 如何使 memory table 支援範圍搜尋嗎?
加上 btree index
以下的 MySQL example code 的意思是?
- Example:
alter table t1 add index a_btree_index using btree (id);
- Answer:
在 memory table 加入 btree index, 使其支援範圍查找

以下的 MySQL example code 中, output 是? 為什麼?
- Example:
CREATE TABLE t1 (
id int PRIMARY KEY,
c int) engine = Memory;
INSERT INTO t1
values(2, 2), (4, 4), (3, 3), (1, 1), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9), (0, 0);
SELECT
*
FROM
t1;
delete from t1 where id=5;
insert into t1 values(10,10);
select * from t1; - Answer:
id=10 會替換原先 id=5 的位置
MySQL 中, Memory table 中, 每行數據的長度相同嗎?
是的
MySQL 中, Memory table 支援 text or blob column 嗎?
不支援
MySQL 中, 當數據位置方生變化時, Memory table 需要修改所有索引, 為什麼?
因為 Memory table 屬於 Heap Organised Table, 每種索引的地位都相等, 皆紀錄資料存放的位置, 所以資料的 hash 變了, 所有的索引也需跟著改變
MySQL 中, 當數據位置方生變化時, InnoDB table 只需要修改主鍵索引, 為什麼?
因為 InnoDB 屬於 Index Organised Table, 主鍵與資料存在一起, 而其他二級索引只存主鍵 id
MySQL 中, Memory 表在插入新數據的時候, 只要有找到空洞就可以插入, 為什麼?
因為 Memory table 是 Heap Organised Table, 是無序性的
MySQL 中, InnoDB 表在插入新數據的時候, 只能在特定的位置插入, 為什麼?
因為 InnoDB 是 Index Organised Table, 需要有序性的插入
MySQL 中, 何謂堆組織表 (Heap Organised Table)?
索引上保存數據位置
MySQL 中, 何謂索引組織表 (Index Organised Table)?
數據存在主鍵索引上, 其他索引存主鍵 id
以下的 MySQL example code 中, output 的排序是? 為什麼?
- Example:
CREATE TABLE t2 (
id int PRIMARY KEY,
c int) engine = innodb;
INSERT INTO t2
values(3, 3), (2, 2), (1, 1), (4, 4), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9), (0, 0);
SELECT
*
FROM
t2; - Answer:
按照 id (primary key) 順序排列, MySQL innoDB engine 所有數據都在 primary key 索引上, 而 primary key 是有序儲存的
以下的 MySQL example code 中, output 的排序是? 為什麼?
- Example:
CREATE TABLE t1 (
id int PRIMARY KEY,
c int) engine = Memory;
INSERT INTO t1
values(2, 2), (4, 4), (3, 3), (1, 1), (5, 5), (6, 6), (7, 7), (8, 8), (9, 9), (0, 0);
SELECT
*
FROM
t1; - Answer:
按照 insert 順序排序, 因為 memory table 是按照輸入的順序排列的

以下的 MySQL example image, 為什麼沒使用 using temporary?
- Example:
- Answer:
因為使用SQL_BIG_RESULT, 優化器不會使用臨時表, 會使用排序演算法在 disk 文件中針對 id%100 的結果做排序, 像是 0000111122223333

MySQL 中, 為什麼不能用 rename 修改臨時表的名稱?
執行 rename 時, 會依照 庫名/表名.frm 的規則去 disk 找文件, 但臨時表在 disk 上的 frm 文件是放在 tmpdir 目錄下的, 且文件名的規則是 #sqlProcessId_treadId_序號.frm , 因此會出現找不到文件名的錯誤
MySQL 什麼時候會使用內部臨時表?
(1) 如果語句執行過程可以一邊讀數據, 一邊直接得到結果, 那是不需要額外內存的, 反之, 就會需要額外的內存來保存中間結果
(2) join_buffer 是無序數組, sort_buffer 是有序數組, 臨時表是二維表結構
(3) 如果執行邏輯需要用到二維表結構, 就會優先考慮使用臨時表, 像是 union 需要用到 unique index constraint, group by 需要用到另一個 column 來 count
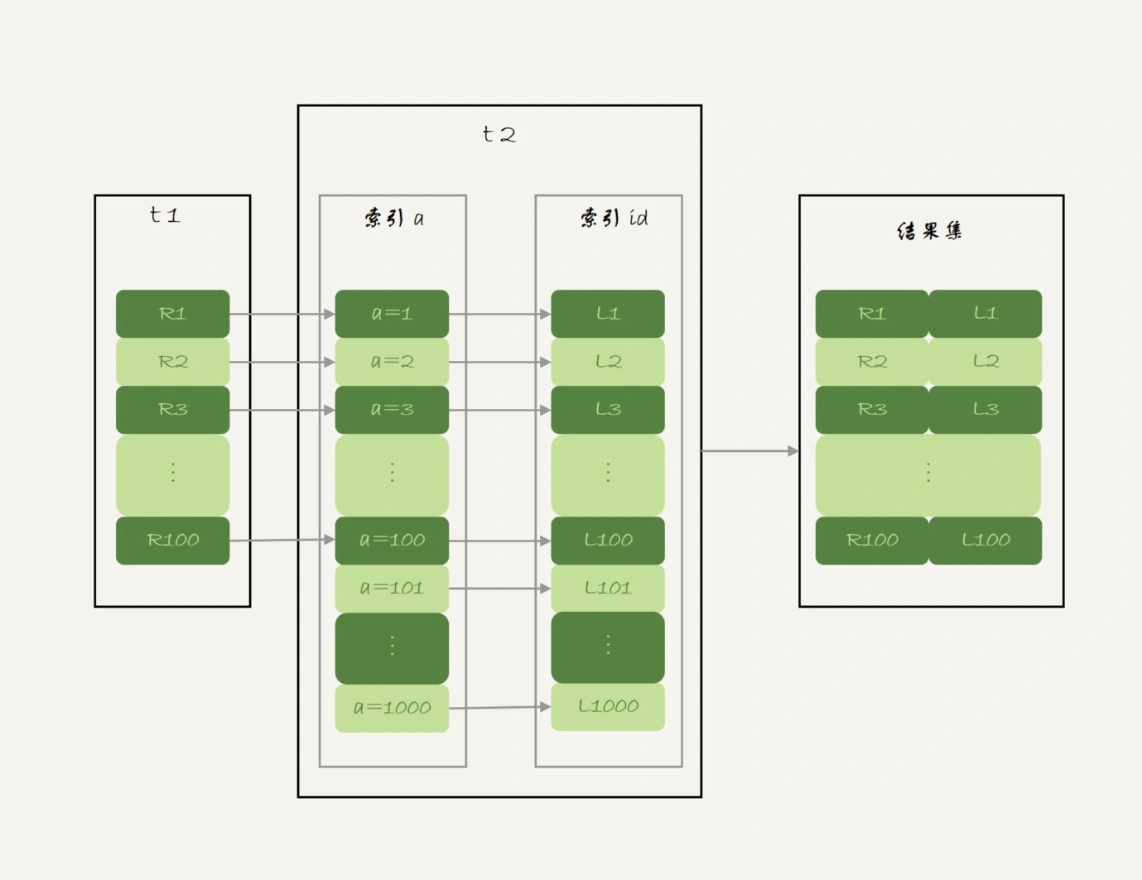
以下的 MySQL example code, 確切流程是?
- Example:
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
- Answer:
(1) 初始化sort_buffer, 確定放入一個 int, 記為 m
(2) 掃描 t1 的 index a, 依序取出裡面的 id 值, 將 id%100 的值存入sort_buffer中, 使用 index a 而不是 index id 的原因是因為, id 屬於 clustered index, 而 a 屬於 secondary index, a index 就只有 a,id, 所以找 a index 的 cost 較小
(3) 掃描完成後, 對sort_buffer的 column m 排序, 如下圖
(4) 如果sort_buffer內存不夠用, 會使用 disk 臨時文件輔助排序
(5) 排序完成後, 得到一個有序數組, 自然可以經由排序知道不同的 m 值的分別數量總共有多少, 如上圖, 掃描到 1 時, 就知道總共有 x 個 0, 掃描到 2 時, 就知道總共有 y 個 1
(6) 整體流程如下
(7) explain 的結果如下



以下的 MySQL example code 的意思是?
- Example:
select SQL_BIG_RESULT id%100 as m, count(*) as c from t1 group by m;
- Answer:
當已知該 query 會使用到內存臨時表, 且結果可能非常大, 內存臨時表的 size 不足以容納時, 可直接使用SQL_BIG_RESULT來指定使用 disk 臨時表
若不指定, 則 MySQL 會先使用內存臨時表, 當判斷 size 不足以容納時, 才轉成 disk 臨時表, 這樣 cost 反而較高
以下的 MySQL example image 中, 若要優化拿掉 using temporary 以及 using filesort, 可以怎麼做?
- Image:
- Answer:
using temporary, 因為id%10本身並沒有排序, 可針對這個條件建立一個 virtual column 並加上 index, 這樣就不需要使用 temporary
using filesort, mysql 8 之後的版本預設不會自動排序, 之前的版本若要取消排序可使用order by null

以下的 MySQL example code 中, 該如何優化 group by?
- Example:
create table t1(id int primary key, a int, b int, index(a));
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
select id%10 as m, count(*) as c from t1 group by m order by null; - Answer:
針對 group by 的 column 加入加入欄位以及索引, 若該欄位無特殊邏輯, 可單純針對欄位本身增加 index 即可alter table t1 add column z int generated always as(id % 100), add index(z);
select z, count(*) as c from t1 group by z;
MySQL 當使用 group by 時, 8 以前的版本會自動根據 group by 的欄位排序, 若不需要排序可以怎麼做?
加上 order by null
以下的 MySQL example image 的意思是?
Image:
Example:
select id%10 as m, count(*) as c from t1 group by m;
Answer:
(1) 創建臨時表, 有兩個 column, m & c, m 為 primary key
(2) 掃描 t1 的 index a, 一次取得 id 並計算id%10的結果, 記為 x
(3) 若臨時表沒有 m = x 的 row, 則插入 new row
(4) 若臨時表已有 m = x 的 row, 則 c++
(5) 遍歷完成, 根據 column m 排序, 返回結果
實測 MySQL 8 不會自動 order by m

以下的 MySQL example image 的意思是?
- Example:
- Answer:
(1) 子查詢取得 1000, 並插入臨時表
(2) 子查詢取得 1000, 插入臨時表失敗, 因為已經存在
(3) 子查詢取得 999, 插入臨時表成功
返回結果

以下的 MySQL example code 中, 該選擇哪一個表為驅動表?
- Example
select * from t1 join t2 on(t1.a=t2.a) join t3 on (t2.b=t3.b) where t1.c>=X and t2.c>=Y and t3.c>=Z;
- Answer
先經由where t1.c>=X and t2.c>=Y and t3.c>=Z過濾條件選出資料最少的當作驅動表
若為 t1, 則t1->t2->t3, 並在 join key 上加 index
若為 t3, 則t3->t2->t1, 並在 join key 上加 index
若為 t2, 則需評估 t2 join t1 或 t2 join t3, 哪個資料少
最後給 c 加上 index
以下的 MySQL example image 中, S 為 M 的備庫, 為什麼在 S 上, 同個線程可以建立同名的臨時表?
- Example:
- Answer:
MySQL 在紀錄 binlog 時, 會把主庫執行這個語句的 thread_id 寫到 binlog 中, 這樣, 在備庫的 thread 就能夠知道每個語句的主庫 thead_id, 且利用這個 thread_id 來構造臨時表的 table_def_key

(1) session A 的臨時表 t1,在備庫的 table_def_key 就是:庫名 + t1 + “M 的 serverid” + “session A 的 thread_id”
(2) session B 的臨時表 t1,在備庫的 table_def_key 就是:庫名 + t1 + “M 的 serverid” + “session B 的 thread_id”
MySQL 在紀錄 binlog 時, 不論是 create table 或是 alter table 語句, 都是原樣紀錄, 甚至連空格都不變, 但如果執行 drop table 時, 系統紀錄 binlog 會變成如下 example, 為什麼?
Example:
DROP TABLE `t_normal` /* generated by server */
Answer:
因為如果在主庫上有建立臨時表, 而 binlog 格式為 row 的話, 會略過臨時表語句, 如果不這麼做, 那在備庫上因為並不存在該臨時表, 就會出錯造成同步停止
MySQL 中, 當 binlog 格式為 row 時, 既然 binlog 不紀錄臨時表語句, 那備庫如何刪除?
主庫會將 drop table temp_table 的語句給備庫執行
MySQL 中, 當 binlog 格式為 row 時, 既然 binlog 不紀錄臨時表語句, 那備庫如何建立臨時表?
主庫會將創建臨時表的語句給備庫執行
MySQL 中, 當 binlog 格式為 mixed/statement 時, 會將臨時表語句記錄下來嗎?
會
MySQL 中, 當 binlog 格式為 row 時, 會將臨時表語句記錄下來嗎?
不會
MySQL 中, 同個 session 可以建立重複名稱的 temp table 嗎?
不可
以下的 MySQL example image 的意思是?
- Example:
- Answer:
在不同 session 可建立同名的臨時表而不會衝突, 不同的 session 維護自己的臨時表空間

MySQL 中, 臨時表文件的前綴是?
#sql{process_id}_{thread_id}_序列號
MySQL 中, 臨時表文件的後綴是?
frm
以下的 MySQL example code 的意思是?
- Example:
select @@tmpdir
- Answer:
顯示當前 session 的臨時文件目錄
以下的 MySQL example image 的意思是?
- Example:
- Answer:
(1) 建立 temp table
(2) 從分表取得資料
(3) 將資料 insert 到 temp table
(4) 從 temp table 做最後操作

以下的 MySQL example image 的意思是?
- Example:
- Answer:
將資料分成 1024 個分表

MySQL 中, 當我使用臨時表, 若連線異常斷開, 或資料庫重啟, 臨時表內的資料會自動釋放嗎?
會
MySQL 中, 臨時表會在一個 session 結束時自動回收嗎?
會
MySQL 中, 臨時表可以與普通表重名嗎?
可以
MySQL 中, 當 temp table 與一般 table 的命名相同, crud 時會取得哪一個?
temp table
MySQL 中, session A 建立的 temp table 可以跟 session B 建立的 temp table 重複命名嗎?
可以
MySQL 中, session A 建立的 temp table 可以被 session B 存取嗎?
不可
MySQL 中, hash join 的概念是?
當 MySQL 採用 BNJ 算法時, 被驅動表中的每一行都會去跟 block 中的每一行做判斷, 假設驅動表為 1000 行, 被驅動表有 1000000 行, 那總判斷次數就是十億次
hash join 的概念, 就是將 join_buffer 中維護的無序數組轉為 hash table, 所以被驅動表就不需要跟 block 中的每一行做比較, 總判斷次數降為 100 萬次
MySQL 8 支援 hash join 嗎?
支援
以下的 MySQL example image 的意思是?
- Example:
- Answer:
前兩張圖是 BNJ 算法, 須判斷 10 億次, 耗時 1 分多鐘
第三張圖, 利用建立臨時表的方式, 觸發 BKA 算法, 1 秒內完成



以下的 MySQL example code 的意思是?
- Example:
create temporary table temp_t(id int primary key, a int, b int, index(b))engine=innodb;
insert into temp_t select * from t2 where b>=1 and b<=2000;
select * from t1 join temp_t on (t1.b=temp_t.b); - Answer:
利用建立臨時表來觸發 BKA 算法
MySQL 中, BNJ 算法對系統影響主要有哪三個方面?
(1) 可能多次掃瞄被驅動表, 佔用 disk I/O 資源
(2) 判斷 join 條件需要執行 N*M 次判斷, 如果是大表就會佔用非常大量的 CPU 資源
(3) 可能導致 Buffer Pool 熱數據被淘汰, 影響內存命中率
MySQL 中, 如果一個使用 BNJ 算法的 join query, 多次掃描一個冷表, 且這個 query 的執行時間大於 1 秒, 且冷表的數據大於整個 buffer pool 的 3/8, 那會發生什麼事?
會不停的洗掉 old 區, 造成正常訪問的熱表一進到 old 區就被洗掉而沒有機會進入 young 區, 降低原本該有的 buffer pool hit rate
MySQL 中, 如果一個使用 BNJ 算法的 join query, 多次掃描一個冷表, 且這個 query 的執行時間大於 1 秒, 且冷表的數據小於整個 buffer pool 的 3/8, 那會發生什麼事?
會將冷表的數據移動到 young 區, 降低原本該有的 buffer pool hit rate
以下的 MySQL example code 的意思是?
- Example:
set optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
- Answer:
開啟 MRR, 開啟 BKA, 穩定使用 BKA
以下的 MySQL example image 中, 如果 join_buffer 滿了會怎麼樣?
- Example:
- Answer:
滿了會繼續步驟 2-3, 完成後清空 buffer 並繼續 1-3

基本步驟
(1) 先將 t1 需要查詢的 row 放到 join_buffer
(2) 取出索引 a 到 t2 取得對應的 row
(3) 組成 row 並回傳結果
以下的 MySQL example image 的意思是?
- Example:
- Answer:
(1) 先將 t1 需要查詢的 row 放到 join_buffer
(2) 取出索引 a 到 t2 取得對應的 row
(3) 組成 row 並回傳結果
MySQL 中, BKA 算法的全寫是?
Batched Key Access
以下的 MySQL example image 中, MRR 的意思是?
- Example:
- Answer:
先將 id 排序過, 再用排序過的 id 到 id index 去取出資料

以下的 MySQL example code 的意思是?
- Example:
set optimizer_switch="mrr_cost_based=off"
- Answer:
優化器會判斷消耗以決定是否使用 MRR, 若設定成 off, 則會穩定使用 MRR 優化
以下的 MySQL example image 中, 萬一 read_rnd_buffer 滿了, 會怎麼樣?
- Example:
- Answer:
若滿了, 會跳到 2-3, 2-3 執行完畢後, 清空 buffer, 重複 2-3

基本步驟
(1) 從索引 a 取得 id, 並存入 read_rnd_buffer
(2) read_rnd_buffer 排序 id
(3) 依照排序後的 id 順序, 到索引 id 取出資料
以下的 MySQL example image 的意思是?
- Example:
- Answer:
(1) 從索引 a 取得 id, 並存入 read_rnd_buffer
(2) read_rnd_buffer 排序 id
(3) 依照排序後的 id 順序, 到索引 id 取出資料
AWS RDS 預設參數無法更改, 要如何更改?
因為預設的參數不給改, 所以要建立一個 parameter group 來自定義參數, 並套用到指定的 instance 上
連結
MySQL 中, MRR 的簡單概念是?
因為大部分的資料都是 auto id 順序寫入的, 所以將索引找到的 id 排序, 以達到順序讀取資料的優化
以下的 MySQL example image 的意思是?
- Example:
- Answer:
根據索引 a 查找 id, 因為 id 順序沒有排過, 會變成隨機讀, 效能較差

MySQl 中, net_buffer 是每個 thread 一個, 還是共享?
每個 thread 一個
MySQL 中, 為什麼當大量出現 thread state 為 sending to client 時, 加大 net_buffer_length 是一個解決方法? socket_send_buffer 比 net_buffer_length 還小, 不是嗎?
因為只要 MySQL 將資料存到 net_buffer_length 之後, 儘管 socket_send_buffer 慢慢發, 但對於 MySQL 來說就是已經發出去了, 這樣就不會影響到語句的執行
MySQL 中, 如果一個 transaction 被 kill 之後持續處於 rollback 狀態, 應該讓他執行完畢, 或是重啟 mysql process?
應讓它自行執行完畢, 因為 rollback 的邏輯是不可少的
可以切到備庫, 減少原主庫的壓力, 讓其自動完成
以下的 MySQL example image 的意思是
- Example:
- Answer:
MySQL 優化過的 LRU 算法, 分為 young, old 兩區, 決定哪些資料該留在內存中, 哪些該淘汰
young 區中的 page 被訪問時, 會移到 head
old 區中的 page 被訪問時, 會根據其存在於 old 區中的時間決定再來的位置
如果超過 1 秒, 則移到 young 區 head, 反之, 則停在 old 區
所以當熱資料被頻繁 query 時, 都會待在 young 區, 而冷資料被 query 時, 只會待在 old 區, 不影響熱資料的 young 區, 從而保證了 buffer pool hit rate

以下的 MySQL example image 中, old 區的一個 page 被訪問, 該 page 會跑到什麼位置?
- Example:
- Answer:
如果該 page 已存在超過 1 秒, 會移到 young 區的 head
如果該 page 存在不超過 1 秒, 仍待在 old 區
以下的 MySQL example image 中, young 區的一個 page 被訪問, 該 page 會跑到什麼位置?
- Example:
- Answer:
會跑到 head 的位置
以下的 MySQL example image 是 LRU 的基本模型, 可能會有什麼問題?
- Example:
- Answer:
當讀到一個歷史大表格時(不常使用), 會將當前內存中常用的資料都淘汰掉, 這樣會造成 buffer pool hit rate 急遽降低

MySQL 中, 內存管理算法 LRU, 全寫是?
Least Recently Used, LRU
MySQL 中, inno_buffer_pool_size 建議設為多少?
物理內存的 60% ~ 80%
MySQL 中, 哪個指令可以看內存命中率?
show engine innodb status
以下的 MySQL example image 中, 為什麼處於 block 狀態, 卻是顯示 sending data?
- Example:
- Answer:
因為 MySQL 會在執行語句階段一開始就把狀態改成sending data, 因此只要是還在執行階段, 都是顯示sending data, 儘管鎖住了

MySQL state 中, sending to client 跟 sending data 的差異是?
sending data 表示語句正在執行階段, 只要是在執行過程中, 儘管鎖住了也是顯示 sending datasending to client 表示正在等待 client 接收資料
MySQL 中, 如果很多 thread 常常處於 “sending to client” 這個狀態, 加大哪一個參數可能可以減少這個狀況??
net_buffer_length
MySQL 中, 如果很多 thread 常常處於 “sending to client” 這個狀態, 那可能要優化哪一部分?
查詢結果
MySQL 中, 一般正常的線上業務來說, 如果查詢的資料不是特別大, 通常都建議使用 mysql_use_result 還是 mysql_store_result?
mysql_store_result
以下的 MySQL example image 中, 如果一直出現 sending to client, 有可能是甚麼原因?
- Example:
- Answer:
server 的網路棧滿了

MySQL 在回傳資料時, 是邊讀邊發, 那若 client 接收的慢, 可能會造成什麼情況?
server 因為結果發不出去, 造成 transaction 執行時間拉很長
MySQL 在回傳資料時, 是邊讀邊發, 還是一次讀完再發?
邊讀邊發
MySQL 中, 到哪去看 socket_send_buffer?
/proc/sys/net/core/wmem_default
MySQL 中, 一個查詢最大會佔用 MySQL 多少內存?
net_buffer_length
以下的 MySQL example image 的意思是?
- Example:
- Answer:
MySQL query 的結果會逐一的放到net_buffer, 滿了之後經由socket_send_buffer送到 client 端

MySQL 中, query result set 會發送到 net_buffer, net_buffer 滿了之後調用網路接口發出去, 那如果返回以下的訊息, 代表的意思是?
- Example:
EAGAIN 或 WSAEWOULDBLOCK - Answer:
代表本地網路 socket send buffer 已滿, 進入等待, 直到網路棧重新可寫, 再繼續發送
MySQL 中, query result set 會全部取得後才送到 client 端嗎?
不會, 會發送到 net_buffer, net_buffer 滿了之後調用網路接口發出去
MySQL 中, 參數 net_buffer_length 的意思是?
定義 net_buffer 的大小
MySQL 中, -quick flag 有什麼效果?
(1) 跳過 table 自動補全功能
(2) 使用 mysql_use_result
(3) 不會把執行命令記錄到本地的歷史文件
MySQL 中, 當使用 mysql_use_result, 可能會造成 server 更快還更慢?
更慢, 因為可能會導致服務端發送結果被阻塞
MySQL 中, client 端發送請求後, 接收服務端返回結果的方式有哪兩種?
(1) mysql_store_result client 端本地緩存
(2) mysql_use_result 不緩存, 讀一個處理一個
MySQL 中, 若因為 table 數量多, 想要加快連接 mysql client 介面連接速度, 可以怎麼做?
-A 關掉自動補全功能
MySQL 中, 當 table 數量一多時, 使用 mysql client 連接會卡很久, 實際上是卡在哪?
卡在建立 local hash table
MySQL 中, 為什麼當 table 數量一多時, 使用 mysql client 連接會卡很久?
因為 MySQL client 會提供一個 local DB 以及 table 的自動補全功能, 因此需要
(1) 執行 show database
(2) 執行 show tables
(3) 將上面兩條命令的結果構建一個 local hash table
MySQL 中, 按下 Ctrl+C 是不是就可以直接終止 thread 呢?
不行, 只是會送一個 kill query, 但不代表可以終止掉該 thread
MySQL 中, 有哪些情況可能會造成終止邏輯耗時長, kill 會卡住?
(1) 超大事務執行期間被 kill, 回滾操作需要對事務執行期間生成的所有新數據版本作回操作
(2) 大查詢回滾, 如果查詢過程中生成了比較大的臨時文件, 加上此時文件系統壓力大, 刪除臨時文件可能需要等待 I/O 資源
(3) DDL 命令執行到最後階段被 kill, 需要刪除中間過程的臨時文件, 也可能受 I/O 資源影響耗時較久
MySQL 中, 有哪兩種情況, show processlist 的結果會是 Command=killed?
(1) thread 沒有執行到判斷狀態的邏輯
(2) 終止邏輯耗時較長
以下的 MySQL example image 中, 為什麼 session E 有效果? 實際效果是?
- Example:
set global innodb_thread_concurrency=2;
- Answer:
kill C 只是將 connection 斷開, 實際上, query 仍在 server 執行

以下的 MySQL example image 中, 為什麼 session D 沒有效果?
- Example:
set global innodb_thread_concurrency=2;
- Answer:
因為在 innodb_thread_concurrency 滿的情況下, thread 會每十毫秒判斷是否能進到 innodb 執行, 不行就 sleep, 在這個等待的循環中, 並沒有判斷線程狀態的邏輯, 因此不會進入終止邏輯階段
MySQL 中, 一個語句執行, 如何隨時判斷狀態? 例如收到 kill 指令
語句執行中會有許多埋點, 在埋點判斷狀態, 執行該有的邏輯
MySQL 中, 當執行 kill query 時, MySQL 會做以下兩件事, 為什麼要對 thread 發送信號?
- Example:
(1) 將 session 的運行狀態改成 THD::KILL_QUERY (將變量 killed 給值為 THD::KILL_QUERY))
(2) 給 session B 的執行線程發一個信號 - Answer:
因為 session B 處於 lock waiting 的狀態, 如果只是改狀態, session B 並不知道這個狀態變化, 會繼續等待, 發信號就是讓 session B 退出等待

以下的 MySQL example image 的意思是?
- Example:
- Answer:
使用 kill query 將 waiting for lock 的 query kill 掉
MySQL 中, 有哪兩種 kill 語句?
kill query thread_id, 終止該 thread 執行的語句
kill connection thread_id, 終止該 tread 的 connection
MySQL 跟 Linux 中的 kill, 實際上都是怎麼樣的行為? 是直接將 process 砍掉嗎?
不是
實際上是告訴 process, 可以開始執行停止執行的邏輯了
MySQL 中, update 跟 performance_schema 都是使用輪詢取資料的方式, 那為何說後者較準確?
後者是 MySQL 內部會自動統計資料, 所以取得得是隨著時間統計的資料
update 只是測試單一個時間點, 所以會有隨機性
MySQL 中, innodb_thread_concurrency 設為多少最好?
核心數的兩倍
以下的 MySQL example code 的意思是?
- Example:
select event_name,MAX_TIMER_WAIT FROM performance_schema.file_summary_by_event_name where event_name in ('wait/io/file/innodb/innodb_log_file','wait/io/file/sql/binlog') and MAX_TIMER_WAIT>200*1000000000;
truncate table performance_schema.file_summary_by_event_name; - Answer:
先利用 MAX_TIMER_WAIT 作為指標, 取出超過 200 毫秒的紀錄, 取得資料後, 清空之前的紀錄, 接下來若是再出現異常, 就可累計
以下的 MySQL example code 的意思是?
- Example:
update setup_instruments set ENABLED='YES', Timed='YES' where name like '%wait/io/file/innodb/innodb_log_file%';
- Answer:
打開 redo log 的 performance_schema
以下的 MySQL example image 的意思是?
- Example:
- Answer:
performance_schema 針對 redo log 的各項統計
COUNT_STAR 代表 I/O 總數
接下來四項代表總和、最大、平均、最小
COUNT_READ 代表 read 總數
SUM_NUMBER_OF_BYTES_READ 代表 read 的總 byte
COUNT_WRITE 代表 write 總數
COUNT_MISC 是針對其他類型的統計, 在 redo log 中, 可理解為 fsync

以下的 MySQL example code 的意思是?
- Example:
mysql> CREATE TABLE `health_check` (
`id` int(11) NOT NULL,
`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
/* 检测命令 */
insert into mysql.health_check(id, t_modified) values (@@server_id, now()) on duplicate key update t_modified=now(); - Answer:
由於檢測資料庫, 若架構為雙 M, 則兩台資料庫可能會因為更新同一行而出現行衝突, 因此將 primary key 設為 server_id, 當資料庫收到自己的 server_id 時會自動忽略, 結果就是主庫偵測主庫的, 備庫偵測備庫的
以下的 MySQL example code, 為什麼仍不足以判斷 MySQL 是否正常?
- Example
select * from mysql.health_check;
- Answer
select 的確可以判斷併發查詢是否堵住了, 但無法判斷磁碟是否吃滿了
以下的 MySQL example code, 會佔用併發查詢的總數嗎?
- Example
select sleep(100) from t
- Answer
會哦
MySQL 中, 進入鎖等待的 thread, 會吃 CPU 嗎?
不會
MySQL 中, 鎖等待的 connection, 會否佔用併發查詢的總數?
不會
MySQL 中, 併發連接以及併發查詢, 哪一種是 CPU 殺手
併發查詢
MySQL 中, innodb_thread_concurrency 建議設為多少?
64~128, 取決於 CPU 有幾核
以下的 MySQL example code & image 的意思是?
- Example:
set global innodb_thread_concurrency=3;
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t values(1,1) - Image:
- Answer:
select 1;只能檢測出 MySQL process 還在, 但如果是併發查詢被佔滿了, 就無法偵測出

MySQL join 中, 建議小表當驅動表, 如何定義小表?
在 where 語句過濾過, 以及 select 欄位的多寡, 總結出行數較少且字段較少的, 稱為小表
以下的 MySQL example code 中, 假設 t1 有 100 行, t2 有 1000 行, 哪句效能較優?
- Example:
select t1.b,t2.* from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=100;
select t1.b,t2.* from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=100; - Answer:
第一句
where 讓兩個表都等於 100 行, 但 t1 只取 b, t2 取所有字段, 因此 t2 資料較大
結論, 選佔用 join_buffer 少的
以下的 MySQL example code 中, 假設 t1 有 100 行, t2 有 1000 行, 哪一句的效能較好?
- Example:
select * from t1 straight_join t2 on (t1.b=t2.b) where t2.id<=50;
select * from t2 straight_join t1 on (t1.b=t2.b) where t2.id<=50; - Answer:
第二句, 因為 where 條件, t2 只需 50 行, 所以 join_buffer 中只需丟入 50 行即可
以下的 MySQL example image 的意思是?
- Image:
- Answer:
(1) 根據 join_buffer 的大小, 取出對應數量 t1 放入 join_buffer
(2) t2 full table scan, 每一行 t2 都要跟 t1 88 行比對
(3) 符合的結果存到 result set
(4) 清空 join_buffer
(5) 塞入 t1 剩下的行數
(6) 重複步驟 2
(7) 重複步驟 3

MySQL 中, join_buffer_size 的用途是?
定義 join_buffer 的大小, 會影響到 BNJ (Block Nested Join) 的速度
以下的 MySQL example image 的意思是?
- Image:
- Answer:
代表 join 無使用 index, 使用 BNJ 算法以及 join_buffer, 這種情況下不建議使用 join

以下的 MySQL example code 中, 說說 join 實際的執行順序?
- Example:
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
drop procedure idata;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
create table t1 like t2;
insert into t1 (select * from t2 where id<=100)
select * from t1 straight_join t2 on (t1.b=t2.b); - Answer:
被驅動表上無可用的索引
(1) 由於是select * from t1, 因此將整個 t1 讀入 join_buffer
(2) full scan t2, 並逐一取出, 與 join_buffer 中的每一行比對, 由於 join_buffer 中是無序數組, 因此 t2 中的每一行都要跟 join_buffer 做 100 次判斷, 總共判斷 100*1000 = 100000 次
(3) 取出表 t2 中滿足條件的行, 跟 t1 該行組成一行, 作為結果集的一部分

MySQL 中, 使用 join 時, 該選擇 record 多或少的當驅動表?
少的, 因為複雜度是 N + N*2*logM
N 是驅動表行數, M 是被驅動表行數
以下的 MySQL example code 中, 假設 t1 共有 N 行, t2 共有 M 行, a 有索引, 那總時間複雜度為多少?
- Example:
select * from t1 straight_join t2 on (t1.a=t2.a);
- Answer:
N+N2logM
t1 行數, 每次在 t2 搜索的複雜度為 2*logM, 共搜索 N 次
t2 每次共會搜尋兩棵樹, a index 以及 id
每次樹搜索的時間複雜度為 logM
以下的 MySQL example code 中, 假設 t2 共有 M 行, a 有索引, 那搜索 t2 單次的時間複雜度是多少?
- Example:
select * from t1 straight_join t2 on (t1.a=t2.a);
- Answer:
2*logM
共會搜尋兩棵樹, a index 以及 id
每次樹搜索的時間複雜度為 logM
以下的 MySQL example code 中, 若不使用 join, 而使用 select * from t1 在手動拼接, 共掃幾行? 差異是?
- Example:
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
drop procedure idata;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
create table t1 like t2;
insert into t1 (select * from t2 where id<=100)
select * from t1 straight_join t2 on (t1.a=t2.a); - Answer:
一樣共掃 200 行, 差異在於會有 101 次 query, 使用 join 只有 1 次
以下的 MySQL example image, 分別各掃兩個 table 幾行?
- Image:
- Answer:
(1) 對驅動表 t1 全表掃, 100 行
(2) 取 a 字段到 t2 找, 樹搜索共 100 行
(3) 共 200 行
以下的 MySQL example image, 是算哪種算法?
- Image:
- Answer:
NLJ (Index Nested-Loop Join)
以下的 MySQL example code 中, 說說 join 實際的執行順序?
- Example:
CREATE TABLE `t2` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `a` (`a`)
) ENGINE=InnoDB;
drop procedure idata;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=1000)do
insert into t2 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
create table t1 like t2;
insert into t1 (select * from t2 where id<=100)
select * from t1 straight_join t2 on (t1.a=t2.a); - Answer:
(1) 從表 t1 中讀入一行數據 R
(2) 從數據 R 中, 取出 a 字段, 到表 t2 中去找
(3) 取出表 t2 中滿足條件的行, 跟 R 組成一行, 作為結果集的一部分
(4) 重複 1~3, 直到表 t1 循環結束
MySQL 中, 以下三種 dead lock log 代表的意思是?
- Example:
locks gap before rec
lock_mode X locks rec but not gap
lock_mode X waiting - Answer:
(1) 第一種代表 gap lock
(2) 第二種代表 row lock
(3) 第三種代表 next-key lock
以下的 MySQL example image 中, 為什麼會 block?
- Image:
- Answer:
原先鎖的範圍為 (5~最大值], 更新之後, 變成 (1, 最大值], 所以 5 鎖住了


以下的 MySQL example image 中, 為什麼會 block?
- Image:
- Answer:
因為 id=10 被刪除後, next-key lock 變為 (5,15], 原本是 (10,15]

MySQL 中, 為了避免死鎖, 在對同一個資源 query 時, 要按照怎樣的順序訪問?
相同的順序
以下的 MySQL example image, 事務 2 的意思是?
- Image:
- Answer:
HOLDS THE LOCK(S)用來顯示這個事務持有哪些鎖;index c of table test.t表示鎖是在表t 的索引c 上;hex 0000000a 和hex 00000014表示這個事務持有c=10 和c=20 這兩個記錄鎖;WAITING FOR THIS LOCK TO BE GRANTED,表示在等(c=5,id=5) 這個記錄鎖。lock in share mode的這條語句,持有c=5 的記錄鎖,在等c=10 的鎖;for update這個語句,持有c=20 和c=10 的記錄鎖,在等c=5 的記錄鎖。

以下的 MySQL example image, 事務 1 的意思是?
- Image:
- Answer:
WAITING FOR THIS LOCK TO BE GRANTED, 表示這個事務在等待的鎖的信息index c of table test.t, 說明在等的是表 t 的索引 c 上面的鎖lock mode S waiting, 表示這個語句要自己加一個讀鎖, 當前狀態等待中Record lock, 說明這是一個紀錄鎖n_fields 2, 表示這個紀錄是兩列, 也就是 column c 以及 primary key id0: len 4; hex 0000000a; asc ;;, 是第一個 column, 也就是 c, 值為十六進制 a, 即 10 是第一个字段,也就是 c。值是十六进制 a,也就是 101: len 4; hex 0000000a; asc ;;, 是第二個 column, 也就是 primary key id, 值也是 10, 這兩行裡面的 asc 表示的是, 接下來要打印出值裡面的 ‘可打印字符’, 但 10 不是可打印字符, 因此就顯示空格
以上信息顯示出在等 (c=10,id=10) 這一行鎖, 但既然出現死鎖了, 表示這個事務也佔有別的鎖, 但沒有顯示出來
以下的 MySQL example image, transaction 1 中, asc ;; 代表的意思是?
- Image:
- Answer:
要打印出值的 ‘可打印字符’, 但 10 不是可打印字符, 因此顯示空格
以下的 MySQL example image, transaction 1 中, 1: len 4; hex 0000000a; asc ;; 代表的意思是?
- Image:
- Answer:
第二個字段, 也就是 primary key id, 值是 16 進制 A, 也就是 10
以下的 MySQL example image, transaction 1 中, 0: len 4; hex 0000000a; asc ;; 代表的意思是?
- Image:
- Answer:
第一個字段, 也就是 c, 值是 16 進制 A, 也就是 10
以下的 MySQL example image, transaction 1 中, n_fields 2 代表的意思是?
- Image:
- Answer:
表示這個紀錄是兩列, column c 以及 primary key id
以下的 MySQL example image, transaction 1 中, Record lock 代表的意思是?
- Image:
- Answer:
說明這是一個紀錄鎖
以下的 MySQL example image, transaction 1 中, lock mode S waiting 代表的意思是?
- Image:
- Answer:
表示這個事務想要自己加一個讀鎖, 狀態為等待中
以下的 MySQL example image, transaction 2 中, hex 0000000a 和 hex 00000014 代表的意思是?
- Image:
- Answer:
表示這個事務持有 c=10, c=20 這兩個紀錄鎖
以下的 MySQL example image, transaction 1 中, index c of table `test`.`t` 代表的意思是?
- Image:
- Answer:
表示在等的是表 t 的索引 c 上的鎖
以下的 MySQL example image, transaction 1 中, WAITING FOR THIS LOCK TO BE GRANTED 代表的意思是?
- Image:
- Answer:
表示這個事務在等待的鎖的信息
MySQL 中, 當條件為範圍查詢時, 為什麼會出現等值查詢?
在第一次樹搜索定位時會使用等值查詢
以下的 MySQL example code 中, 加了哪些鎖, 順序為何?
- Example:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
begin;
select * from t where id>9 and id<12 order by id desc for update; - Answer:
由於 desc, 會先 tree search 找 id=12 的值, 沒找到, 只找到(10,15)key-lock, 這邊會先往右遍歷, 因為 15 != 12, 索引等值查詢不相等時會退化為 gap lock
向左遍歷, 舊版 MySQL 會掃到第一個不符合條件的值為止, 即 id=5, 所以鎖了(0,5],(5,10]
總共鎖了(0,5],(5,10],(10,15)
根據阿里巴巴 MySQL 規約, 撈取資料時, 可以使用 * 嗎?
不可, 需指名 column
根據阿里巴巴 MySQL 規約, 不在代碼中使用 truncate 來代替 delete, 儘管 truncate 速度快, 原因為何?
truncate 無事務, 且無法觸發 trigger
根據阿里巴巴 MySQL 規約, 如果有全球化需求, 且有表情符號需求, 資料庫儲存使用什麼編碼?
utf8mb4
根據阿里巴巴 MySQL 規約, 如果有全球化需求, 資料庫儲存使用什麼編碼?
utf8
根據阿里巴巴 MySQL 規約, 須盡量避免 in, 若非得使用, 限制多少數量 ?
1000 以內
根據阿里巴巴 MySQL 規約, 是否須盡量避免 in ?
是的
根據阿里巴巴 MySQL 規約, 要刪除 data 前, 要先經過哪道程序?
要先 select, 確認無誤避免誤刪
根據阿里巴巴 MySQL 規約, 不可使用 process, 原因為何?
難以調適、拓展, 更無移植性
根據阿里巴巴 MySQL 規約, 需使用 IFNULL() 來判斷是否 NULL, 為什麼?
因為
NULL<>NULL的返回结果是 NULL,而不是 false。NULL=NULL的返回结果是 NULL,而不是 true。NULL<>1的返回结果是 NULL,而不是 true。
MySQL 中, 如果一個大事務執行了 10 分鐘, 從庫會只堵這個事務, 還是所有的事務?
看是否有並行複製, 預設是串行, 就是全堵
MySQL 中, 一般主從延遲超過多少就不好?
大於 1
MySQL 當主從連接時會取得 unix_timestamp 取得時間差, 若連接完成後再去改從庫系統時間, 會否造成 seconds_behind_master 不準?
會的, 主庫只在建立連接時取得時間差
根據阿里巴巴 MySQL 規約, 可以使用 foreign key 嗎?
只可在應用層實施, 高併發或分布式資料庫時會造成嚴重阻塞
以下的 MySQL example code 的意思是?
- Example:
SELECT IF (ISNULL (SUM (g)),0,SUM (g)) FROM table;
- Answer:
因為 sum(col) 如果 col 全為 null, 則 result 為 null, 因此為了避免 NPE (Null Pointing Exception) issue, 使用 IFNULL 判斷, 若 NULL 則給 default 0
以下的 MySQL example code 中, 如果 col 全為 null, 那結果會是?
- Example:
select sum(col) from table;
- Answer:
NULL
以下的 MySQL example code, 假設 column1 全為 null, column2 全不為 null, 則結果為?
- Example:
select count (column1, column2) from table;
- Answer:
0
根據阿里巴巴 MySQL 規約, 在建立索引方面有哪三種誤解?
- 一個查詢就需要一個 index
- index 會嚴重消耗空間, 拖慢更新以及新增速度
- 唯一索引一律需要在應用層先查後插入解決
根據阿里巴巴 MySQL 規約, 建立 compund index 時, 通常區分度高的為左邊, 有什麼例外情況?
非等值以及等值混合判斷時, 即使非等值的 index 區分度較高, 也需置於右邊
根據阿里巴巴 MySQL 規約, 建立 compund index 時, 怎樣的 index 置於右邊?
區分度高的
根據阿里巴巴 MySQL 規約, SQL 性能優化又分為哪三個等級?
- const: 單一匹配, 如 id 或 unique index
- ref: normal index
- range: range index serach
以下的 MySQL example code 的意思是?
- Example:
SELECT a.* FROM table_a as a, (select id from table_a where xxx LIMIT 100000,20) as b where a.id=b.id
- Answer:
當資料庫資料筆數到達一定程度時, limit 會造成效能低下, 因為 MySQL 是先取得 100000 + 20 行, 在丟棄 100000 行
因此可以利用 subquery 取得目標 id, 再從該 id 取得所有資料
根據阿里巴巴 MySQL 規約, 可以使用左模糊或全模糊搜尋嗎?
不可, 若有必要請使用搜尋引擎
根據阿里巴巴 MySQL 規約, 在 varchar 上建立 index, 務必使用哪種類型 index?
prefix
根據阿里巴巴 MySQL 規約, 超過幾個 table 不可使用 join?
三個
以下的 MySQL example code 的意思是?
- Example:
stop slave;
CHANGE MASTER TO IGNORE_SERVER_IDS=(server_id_of_B);
start slave; - Answer:
先暫時性的 ignore 指定的 server_id, 等到循環複製的情況解除後, 再加回來
MySQL 中, 為什麼執行 set global server_id=x 後會造成循環複製?
因為 server_id 變了, 收到 relay log 之後發現跟目前的 server_id 不同, 就會造成循環複製了
以下的 MySQL example image 的意思是?
- Image:
- Answer:
可用性優先策略, binlog format 為 row
假設在主備切換的途中, 有兩條 insert 語句, insert c=4 以及 insert c=5

- 主庫 A 執行完 insert 語句, 插入 c=4
- 由於採用可用性優先策略, 不將主庫改為 readonly, 所以 insert 完畢, 即 (4,4)
- 切換為備庫 B, 此時 insert c=5, 主庫 A 改為 readonly, 備庫 B 改為可寫, 並且收到來自主庫 A 的 relay log (4,4)
- 備庫 B insert c=5 執行完畢, 即 (4,5), 主庫 A 收到來自於備庫 B 的 relay log (4,5)
- 由於 binlog format 為 row, 所以兩邊同時報錯 duplicate key error
以下的 MySQL example image 的意思是?
- Image:
- Answer:
可用性優先策略, binlog format 為 mixed
假設在主備切換的途中, 有兩條 insert 語句, insert c=4 以及 insert c=5

- 主庫 A 執行完 insert 語句, 插入 c=4
- 由於採用可用性優先策略, 不將主庫改為 readonly, 所以 insert 完畢, 即 (4,4)
- 切換為備庫 B, 此時 insert c=5, 主庫 A 改為 readonly, 備庫 B 改為可寫, 並且收到來自主庫 A 的 relay log (4,4)
- 備庫 B insert c=5 執行完畢, 即 (4,5), 主庫 A 收到來自於備庫 B 的 relay log (4,5)
- 由於 binlog format 為 statement, 所以兩邊都寫入資料
最終導致主備資料不一致的現象
以下的 MySQL example image 的意思是?
- Image:
- Answer:
可靠性優先策略

- 判斷 SBM (seconds_behind_master) 是否在 5 秒內, 若大於 5 秒則重複判斷
- 若在 5 秒內, 將主庫 A 改為 readonly
- 判斷備庫 B 的 SBM, 直到等於 0
- 將備庫設為可讀寫
- 將業務請求導向備庫 B
MySQL 中, 為什麼大事務會造成主備延遲?
若一個主庫上的語句花費 10 分鐘執行, 那這個事務很有可能就會造成至少 10 分鐘的主備延遲
MySQL 中, 若主備延遲的原因是因為備庫又被拿來提供 read, 壓力太大, 通常解法是?
採用一主多從方式, 用多個從庫去分散壓力
MySQL 中, 主備延遲有哪兩種可能?
- 備庫機器規格較差
- 備庫又被用來提供 read, 反而造成壓力太大
- 大事務, 或大表 DDL
- 備庫的並行複製能力
MySQL 中, 以下的三個時間點中, 主備延遲的主要原因, 可能是哪兩個時間點造成的?
- 時間點:
- 主庫 A 執行完成一個事務, 寫入 binlog, 這個時刻記為 T1
- 之後傳給備庫, 備庫 B 接收完這個 binlog 的時刻記為 T2
- 備庫 B 執行完成這個事務, 這個時刻記為 T3
- Answer:
T3 - T2, 即備庫消耗 relay log 的速度
MySQL 中, 以下的三個時間點中, 哪兩個時間點在網路正常的情況下是非常短的?
- 時間點:
- 主庫 A 執行完成一個事務, 寫入 binlog, 這個時刻記為 T1
- 之後傳給備庫, 備庫 B 接收完這個 binlog 的時刻記為 T2
- 備庫 B 執行完成這個事務, 這個時刻記為 T3
- Answer:
T2 - T1
MySQL 中, 若主備庫的系統時區不一致, 會否影響到 seconds_behind_master 的準確度?
不會, 備庫連接到主庫時, 會執行 SELECT UNIX_TIMESTAMP() 取得當前主庫的系統時間, 若發現這個時間與備庫上的系統時間不一致, 在計算 seconds_behind_master 時會扣掉這個差值
MySQL 中, seconds_behind_master 的精度到?
秒
MySQL 中, seconds_behind_master 的計算方法是?
- 每個事務的 binlog 裡有都有一個時間 column, 用於記錄主庫上寫入的時間
- 主庫取出事務的時間 column, 計算與當前系統的差值
MySQL 中, 要取得 seconds_behind_master, 可以在備庫上使用哪個指令?
show slave status
MySQL 中, 以下的三個時間點中, 所謂的主備延遲, 代表的是哪段時間點?
- 時間點:
- 主庫 A 執行完成一個事務, 寫入 binlog, 這個時刻記為 T1
- 之後傳給備庫, 備庫 B 接收完這個 binlog 的時刻記為 T2
- 備庫 B 執行完成這個事務, 這個時刻記為 T3
- Answer:
同一個事務在備庫執行完成的時間和主庫執行完成的時間的差值
T3 - T1
根據阿里巴巴 MySQL 規約, 業務上具有唯一特性的欄位, 即使是組合欄位, 也必須建立 unique index, 對嗎?
對的
根據阿里巴巴 MySQL 規約, 建議 table 大小超過多少才分庫分表?
2GB
根據阿里巴巴 MySQL 規約, 建議 table 超過幾行才分庫分表?
500 萬行
根據阿里巴巴 MySQL 規約, 容許 column redundency 嗎? 原則是什麼?
容許適當以提高性能
- 不是頻繁修改 column
- 不是超長 column varchar, 不是 text
例如商品總類目, 長度短且基本不會變更, 可冗余以減少關聯
根據阿里巴巴 MySQL 規約, 若修正了 column name 或 column type, 建議一併修改什麼?
comment
根據阿里巴巴 MySQL 規約, database 命名盡量與什麼一致?
Application
根據阿里巴巴 MySQL 規約, table 命名原則推薦格式為?
業務名稱_表的作用, 如 tiger_task
根據阿里巴巴 MySQL 規約, table 有哪三個必備 column?
id - primary key, created_at - datetime, updated_at - datetime
根據阿里巴巴 MySQL 規約, 若 column character 大於 5000, 是否需要獨立一張表格?
是
根據阿里巴巴 MySQL 規約, character 大於多少使用 text? 否則就使用 varchar?
5000
根據阿里巴巴 MySQL 規約, 如果欄位的 character 長度固定, 使用哪個 column type?
char
根據阿里巴巴 MySQL 規約, 小數類型一律使用哪個 column type?
decimal, 為保持精度
根據阿里巴巴 MySQL 規約, 一般 index 的命名開頭為?
idx_xxx, 即 index 簡稱
根據阿里巴巴 MySQL 規約, unique key index 的命名開頭為?
uk_xxx, 即 unique key 簡稱
根據阿里巴巴 MySQL 規約, table 命名可以保留字嗎?
不行, 可 google reserved word 查詢 MySQL 保留字
根據阿里巴巴 MySQL 規約, table 命名可以使用複數嗎?
不行
根據阿里巴巴 MySQL 規約, column 命名在兩個 _ 之間, 可以只出現數字嗎?
不行
根據阿里巴巴 MySQL 規約, column 命名可以用數字開頭嗎?
不行
根據阿里巴巴 MySQL 規約, boolean 的 column type 為?
unsigned tinyint
根據阿里巴巴 MySQL 規約, boolean 的欄位命名規則為?
is_xxx
MySQL 中, 生產環境的 binlog 格式強烈建議為哪一種?
row
MySQL 中, 假設一個 table 中並沒有 primary key, 然後 insert 了一筆 record A, record A 和之前的某一筆 record B 一模一樣, 然後使用 binlog 恢復到還沒 insert 之前, 會否刪掉早前那筆一模一樣 record
有可能刪到 record B, 因為當 table 沒有 primary key, binlog 中就不會紀錄 primary key
MySQL 中, 假設禮拜日的 23 做了備份, 禮拜二 20 要恢復數據, 該使用哪個參數讓 binlog 停在禮拜日的 23?
可使用 –stop-datetime flag
MySQL 中, 若一個事務的 binlog 寫入後, 超過了 max_binlog_size, 那會怎麼樣?
會 rotate, 生成一個新的 binlog file, 但會寫完在 rotate, 不會斷掉
MySQL 中, master 從本地讀取 binlog 並傳給 slave, 是讀 page cache, 還是 disk?
這是 OS 做的事, 若有 page cache 則讀 page cache, 否則則是 disk
MySQL 中, 一般生產環境的 非雙 1 的設置是?
innodb_flush_logs_at_trx_commit=2
sync_binlog=1000
MySQL 中, 在哪些情景可能會將 binlog, redo log 設為 非雙 1 ?
- 有預知的業務高峰期
- 備庫延遲, 要讓備庫趕上主庫
- 用備份恢復主庫的副本時
- 批量導入數據時
MySQL 雙 master 架構中, 如何解決循環複製?
- 規定兩個資料庫 server_id 必須不同
- 備庫在接到 binlog 並重放後, 生成的 binlog 中, server_id 需與來源的 server_id 相同
- 每個資料庫在收到 master 發來的 binlog, 先判斷 server_id 是否跟自己的一樣, 若是則丟棄
MySQL 雙 master 架構中, 何謂循環複製?
master A 的 binlog 在 master B 的 relay log 中執行完畢後, 在 B 又產生新的 binlog, 又傳回 A, 而 A 又執行了一次, 一直往返
MySQL 中, log_slave_updates 設為 on, 表示?
表示 relay log 執行後, 也會產生 binlog
以下的 MySQL example image 的意思是?
- Image:
- Answer:
雙 master 配置, 彼此皆為對方的 slave, 也為 master, 因此在切換時就不用特別設置誰為 master 誰為 slave

MySQL 中, 標準的使用 binlog 恢復數據的做法是?
使用 mysqlbinlog 工具解析出來, 把解析結果整個丟給 MySQL 執行, 只複製某段 query 可能會有上下文的關係mysqlbinlog master.000001 --start-position=2738 --stop-position=2973 | mysql -h127.0.0.1 -P13000 -u$user -p$pwd;
MySQL 中, 假如一個 query 刪除十萬筆資料, 若使用的 binlog 格式為 row, 儲存的方式是?
會儲存十萬筆到 binlog, 紀錄明確 each row 的確實 deleted query
MySQL 中, 假如一個 query 刪除十萬筆資料, 若使用的 binlog 格式為 statement, 儲存的方式是?
單純儲存該 MySQL query, 頂多十幾個 bytes
MySQL 中, binlog mixed 格式被發明的出發點是?
節省 row 格式造成的空間消耗
MySQL 中, binlog mixed 格式的特色是?
會自己判斷該 query 是否會造成主從不一致, 若會則使用 row 格式, 不會則使用 statement
以下的 MySQL example image 的意思是?
- Image:
- Answer:
server id 1: 表示該 transaction 是在 server_id=1 的資料庫上執行的
每個 event 都有 CRC32: 因為 binlog_checksum 設為 CRC32
Table_map: 代表操作的 table
指令使用了 -vv, 因此解析了所有內容, 例如 @1=4, @2=4
binlog_row_image 預設配置為 FULL, 因此 Delete_event 中包含了該 row 所有 column 的值, 如果設為 MINIMAL, 則只會紀錄必要訊息, 如 id
最後的 Xid event, 表示該 transaction 被正確提交了

以下的 MySQL example code 的意思是?
- Example:
mysqlbinlog -vv data/master.000001 --start-position=8900;
- Answer:
使用 mysqlbinlog, 從指定的 binlog file 中, 指定 position, 取出接下來的資料
以下的 MySQL example image 的意思是?
- Image:
- Answer:
binlog row 格式

以下的 MySQL example 中, 為什麼使用 statement 格式的 binlog 可能會有問題?
- Example:
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`a` int(11) DEFAULT NULL,
`t_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `a` (`a`),
KEY `t_modified` (`t_modified`)) ENGINE = InnoDB;
INSERT INTO t
values(1, 1, '2018-11-13');
INSERT INTO t
values(2, 2, '2018-11-12');
INSERT INTO t
values(3, 3, '2018-11-11');
INSERT INTO t
values(4, 4, '2018-11-10');
INSERT INTO t
values(5, 5, '2018-11-09');
delete from t /*comment*/ where a>=4 and t_modified<='2018-11-10' limit 1; - Answer:
因為在 slave 再次執行 binlog 時, 不確定會使用 a 或是 t_modified 哪一個索引, 可能會造成 master 與 slave 資料不一致
以下的 MySQL example image 的意思是?
- Image:
- Answer:
binlog statement 格式

MySQL 中, binlog 又分為哪三種格式?
statement, row, mixed
以下的 MySQL example image 的意思是?
- Image:
- Answer:
- 在備庫上使用 change master, 指定 master 的 ip, port, account, password, 以及要從哪個位置請求 binlog, 包含文件名以及 log 偏移量
- 在備庫使用 start slave, 會啟動兩個 process, io_thread 以及 sql_thread, io_thread 會與 master 建立連接
- master 校驗完身份後, 開始按照 slave 指定的位置, 從本地讀取 binlog, 發給 slave
- slave 拿到 binlog 後, 寫到 relay log, 稱為中轉日誌
- sql_thread 讀取 relay log, 解析並執行

以下的 MySQL example image 中, 將備庫設為 readonly, 那我還怎麼同步呢?
- Image:
- Answer:
同步的 session 需擁有 super 權限
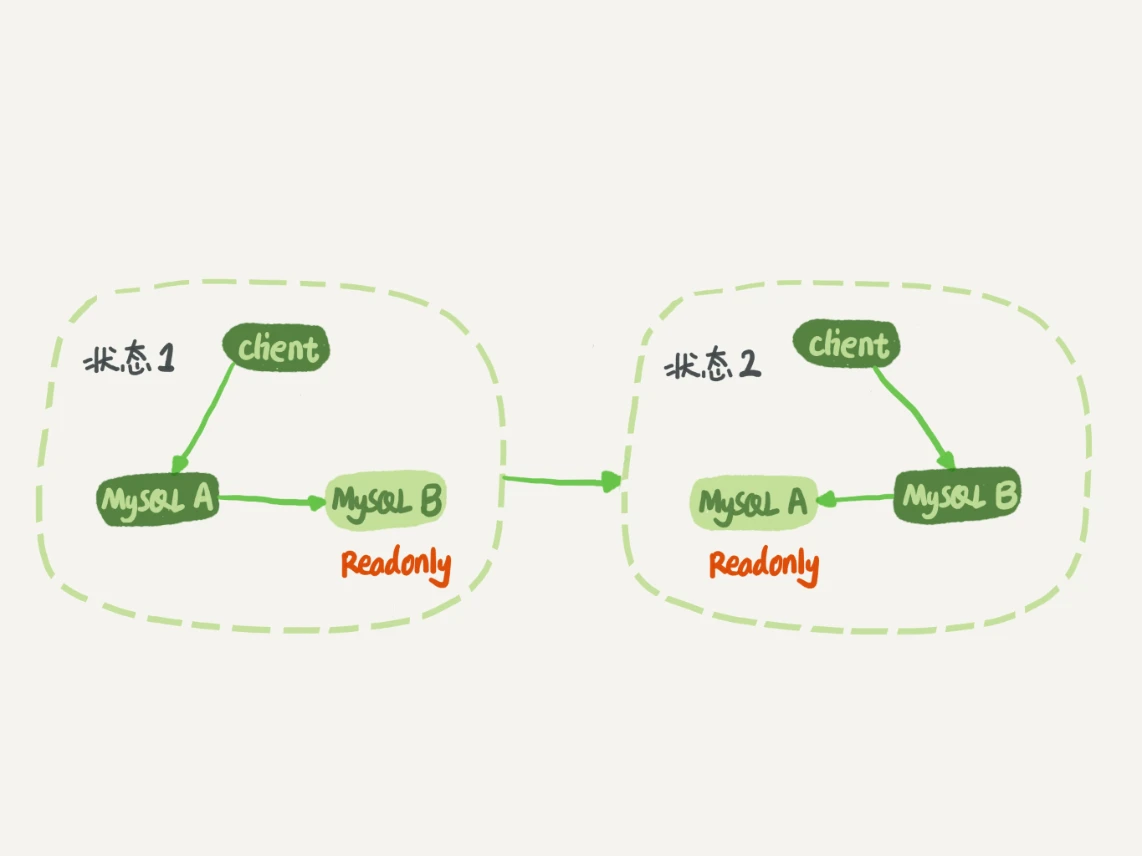
以下的 MySQL example image 中, 會將備庫設為 readonly, 主要有哪三種考量?
- Image:
- Answer:
- 當在備庫上使用一些 query 時, 可防止誤寫
- 如果切換邏輯沒寫好, 會造成雙寫
- 可用 readonly 來判斷 node 的角色
以下的 MySQL example image 的意思是?
- Image:
- Answer:
兩個資料庫, 互為備庫, 當為備庫時為 readonly
MySQL 中, binlog_cache_size 跟 max_binlog_cache_size 的差別是?
前者超出了會存到 disk 上, 後者會噴錯
MySQL 中, 為什麼說 redo log 可以共用一個 relog log buffer, 但 binlog 卻要每個線程獨立, 不可中斷?
一個 binlog 都相當於一個事務, 要是中斷了或分散了, 就相當於把一個事務分開執行, 這樣就無法保證其原子性
redo log 是以 page 為單位, 一個事務可能會更動多個 page, 多個事務也可能只更動一個 page, 所以較無原子性問題
MySQL 中, 如果 sync_binlog = N, binlog_group_commit_sync_no_delay_count = M, binlog_group_commit_sync_delay = 很大值, 這種情況下, 何時會 fsync?
會先滿足 sync_binlog 條件, 接下來才會去判斷要使用 no_delay_count 還是 sync_delay, 如果 no_delay_count > sync_binlog, 則會滿足 no_delay_count 才會 fsync
MySQL 中, 事務未提交前, redo log 及 binlog 會寫到哪裡?
redo log buffer 以及 binlog cache
MySQL 中, 要走到 redo log prepare, 會先經過 transaction commit 嗎?
會, 二階段協議(非 lock 的二階段提交) 是在 transaction commit 後才開始
MySQL 中, 事務執行期間, 如果發生 crash, 導致 redo log 丟了, 這樣會不會造成主備不一致?
不會, 因為 crash 之後 redo log 和 binlog 都沒了, 從業務上來看, 這個數據也沒有提交, 因此數據一致
MySQL 中, 為什麼 binlog cache 是每個線程自己維護, 而 redo log buffer 是全局共用?
因為 binlog 是不可以被打斷的, 一個事務的 binlog 必須連續寫, 整個事務完成後, 在一起寫到文件內
redo log 則沒有這個要求, 中間有生成的 log 可以寫到 redo log buffer 中, redo log buffer 中的內容還能搭便車, 隨其他事務一起被寫到 disk 中
MySQL 中, 執行一個 update 語句, 在執行 hexdump 查看 ibd 文件內容, 為何沒看到數據有改變?
可能因為 WAL 機制, update 語句執行完畢後, InnoDB 只保證寫完了 redo log, page cache, 還沒 sync 到 disk
MySQL 中, 如果遇到性能上的瓶頸, 通常有哪三種方法可以提升性能?
- 調高 binlog_group_commit_sync_no_delay_count, binlog_group_commit_sync_delay 參數, 會增加 response time, 但無數據丟失風險
- 將 sync_binlog 設置大於 1, 常見的為 100~1000, 主機掉電會丟 binlog
- 將 innodb_flush_log_at_trx_commit 設為 2, 風險是主機掉電時會丟數據
MySQL 中, ‘binlog_group_commit_sync_no_delay_count’ 以及 ‘binlog_group_commit_sync_delay’ 的關係是?
or, 只要其中一個滿足就調用 fsync, 所以如果 delay 設為 0, count 也就失效了
MySQL 中, ‘binlog_group_commit_sync_no_delay_count’ 的意思是?
累積多少次 write 的次數才調用 fsync
MySQL 中, ‘binlog_group_commit_sync_delay’ 的意思是?
延遲多少微秒才調用 fsync
以下的 MySQL example image 的意思是?
Image:
Answer:
將 fsync 的時間延後, 以更加優化 group 提交, 減少 IOPS 消耗

以下的 MySQL example image 中, 為什麼 trx1 會帶著 length 160 到 fsync?
Image:
Answer:
trx1 是第一個到 redo log 的 trx, 因此被選為該 group 的 leader, 當 fsync 的時間到了, 會 fsync redo log 中的所有 trx, 又名為 group commit

何謂 MySQL 的 ‘雙 1’ 配置?
sync_binlog 以及 innodb_flush_log_at_trx_commit 都設為 1, 一個事務提交前, 會有兩次的刷盤
MySQL 中, 在二階段提交時, redo log 會在 prepare 時持久化, 還是 commit 時?
會在 prepare 時持久化, commit 時只寫到 disk
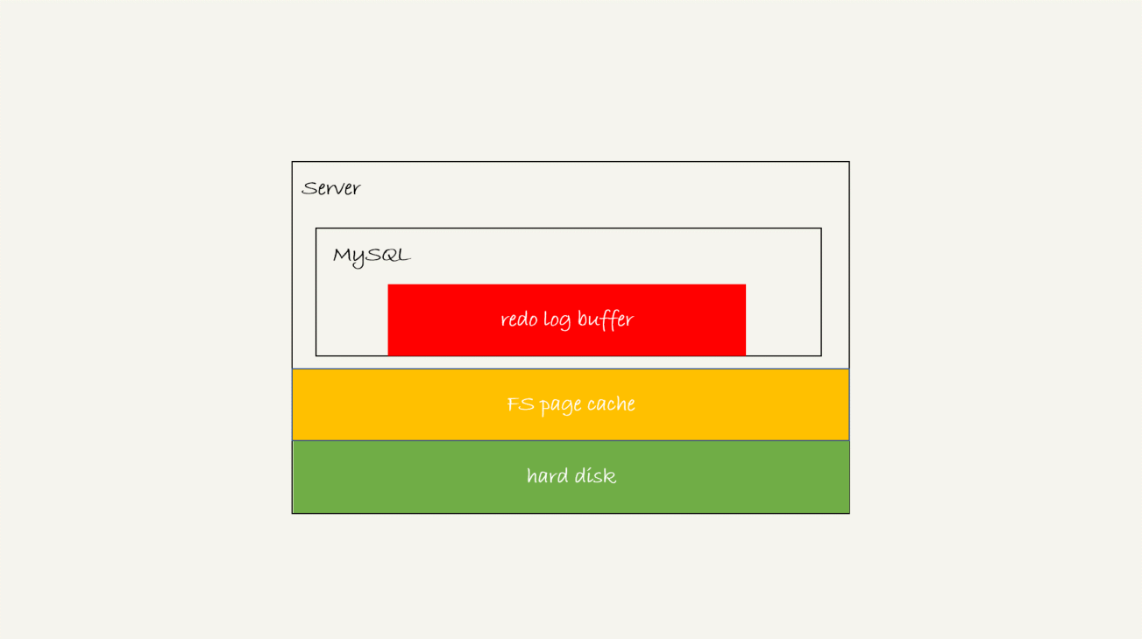
MySQL 中, 有哪三種情況, 會讓一個沒有提交的事務的 redo log 寫入磁盤中?
Image:
Answer:
後台 process 固定每秒輪詢一次, 會呼叫 write 將 redo log buffer 寫到 page cache, 在調用 fsync 將 page cache 寫入 disk
當 redo log buffer 即將達到 innodb_log_buffer_size 的一半, 後台 process 會主動寫盤, 但由於事務並沒有提交, 只會調用 write, 不會調用 fsync
並行的事務提交時, 順帶將其他未提交的 redo log buffer 持久化, 假設事務 A 執行到一半, 已寫了一些 redo log 到 buffer 當中, 這時有另外一個事務 B 提交, 且 innodb_flush_log_at_trx_commit=1, 這時會將 redo log buffer 中的的 log 全部持久化到 disk
以下的 MySQL example image 中, 當 innodb_flush_log_at_trx_commit=2, 行為是?
Image:
Answer:
每次事務提交都只是把 redo log 寫到 page cache
以下的 MySQL example image 中, 當 innodb_flush_log_at_trx_commit=1, 行為是?
Image:
Answer:
每次事務提交都把 redo log 持久化到 disk
以下的 MySQL example image 中, 當 innodb_flush_log_at_trx_commit=0, 行為是?
Image:
Answer:
每次事務提交都只是把 redo log 留在 redo log buffer 中
以下的 MySQL example image 中, 每個區塊的寫入速度比較是?
Image:
Answer:
紅色跟黃色都屬於內存, 速度差不多, 綠色屬於 disk, 速度慢多了
以下的 MySQL example image 中, 每個區塊分別代表的意思是?
Image:
Answer:
紅色屬於 MySQL process 中的內存, 黃色為 page cache, 還不算持久化, 綠色才算持久化
以下的 MySQL example image 中, 如果有 I/O 瓶頸, 一般會將 sync_binlog 設為多少?
Image:
Answer:
100~1000

以下的 MySQL example image 中, 如果服務容錯率非常低的話, 那 sync_binlog 會設為多少?
Image:
Answer:
1, 每次都 fsync
以下的 MySQL example image 中, 如果我的 sync_binlog=N(N>1), 那行為會是?
Image:
Answer:
每次都 write, 但累積 N 個 transaction 後才 fsync
以下的 MySQL example image 中, 如果我的 sync_binlog=1, 那行為會是?
Image:
Answer:
每次事務都 fsync
以下的 MySQL example image 中, 如果我的 sync_binlog=0, 那行為會是?
Image:
Answer:
每次事務都只 write, 不 fsync
MySQL 中, binlog_cache_size 的用途是?
控制單個線程內, binlog cache 的大小, 若超出規定值, 則暫存到 disk 上
以下的 MySQL example image 的意思是?
Image:
Answer:
transaction 執行過程中, 會先把 log 寫到 binlog cache, 提交時, 再把 binlog 寫到 binlog 文件中
系統給 binlog cache 分配了一塊內存, 每個線程一個, binlog_cache_size 用於控制單個線程內, binlog cache 所佔的大小, 如果超過了, 將會暫存到 disk
transaction 提交時, 會將 binlog cache 完整寫入到 binlog 文件, 並清空 binlog cache
以下的 MySQL 步驟的意思是?
- Example:
上線前, 在測試環境, 把 slow log 打開, 把 long_query_time 設為 0
在測試表中插入模擬線上的資料, 逐一觀察 slow log 中每類 query 的輸出, 留意 rows_examined 是否與預期一致 - Answer:
在上線前檢查, 預先發現問題
MySQL 中, 哪個工具可以幫忙檢查所有 slow log 中所有 query 的返回結果?
以下的 MySQL example code 的意思是?
Example:
insert into query_rewrite.rewrite_rules(pattern, replacement, pattern_database) values ("select * from t where id + 1 = ?", "select * from t where id = ? - 1", "db1");call query_rewrite.flush_rewrite_rules();
Image:
Answer:
當 sql 語句寫錯了, 但無法從程式端修改時, 可直接從 DB 端修改, 但須謹慎評估, 可能造成誤傷

MySQL 中, 以下的步驟的意思是?
Example
在備庫上執行 set sql_log_bin=off, 執行 alter table 加上索引
主從切換
在主庫上執行 set sql_log_bin=off, 執行 alter table 加上索引Answer
當索引沒設計好時, 直接在備庫上執行 DDL
MySQL 中, 通常造成慢查詢大體上會是哪三種原因?
- 索引沒設計好
- SQL 語句沒寫好
- MySQL 選錯索引
以下的 MySQL example code 的意思是?
- Example
[mysqld]
skip-grant-tables
skip-networking - Answer
當忘了 root 密碼, 或者暫時性地減低 connection 的 cost, 可以先把驗證部分拿掉, 並中斷 networking, 這樣外部就無法直接連接資料庫
然後在 restart mysql
以下的 MySQL example image 的意思是?
Image
Answer
當不確定有哪些 connection 是處於 transaction 中時, 可使用select * from information_schema.innodb_trx

以下的 MySQL example image 中, 如果非得 kill 掉一個 session, 該 kill 哪一個?
Image
Answer
session B, 因為不會造成什麼有損傷害
若 kill session A, 那會造成 rollback

MySQL 中, 為什麼說每一次連接的成本都很大?
要經過 TCP 三次握手, 以及權限驗證等等的程序
MySQL 中, insert … select 會加鎖嗎?
為了一致性, 會加 read lock
MySQL 中, RC Isolation level 下, 若要避免 binlog 與資料庫不一致, 需怎麼做?
將 binlog 設置為 row 格式
以下的 MySQL example image 中, 默認是會上鎖的, 說說不上鎖造成的結果
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)) ENGINE = InnoDB;
INSERT INTO t
values(0, 0, 0), (5, 5, 5), (10, 10, 10), (15, 15, 15), (20, 20, 20), (25, 25, 25);Image
Answer
session A 已表示要鎖住所有 d=5 的 row 了, session B 還透過 update 讓 d=5 多了 1 row
session C 則是透過 insert 直接插入新的一個 d=5 的 row

MySQL 中, RR Isolation 中, 索引等值查詢, 向右遍歷且最後一個值不滿足等值條件時, 會怎麼做?
next-key lock 退化為 gap lock
MySQL 中, RR Isolation 中, 索引等值查詢, 當給唯一索引加鎖時, 規則是?
next-key lock 退化為 row lock
MySQL 中, RR Isolation 中, 基本的加鎖單位是?
next-key lock, 先加 gap lock, 再加 row lock
MySQL 中, 無索引的 update 會逐行加鎖, 還是全部加鎖?
逐行
MySQL 中, 如果 Isolation level 為 RC, semi-consistent read 優化對 delete 有效嗎?
無效, 只對 update 有效
MySQL 中, 如果 Isolation level 為 RC, 何謂 semi-consistent read 優化?
如果 update 碰到一個被上鎖的行, 會讀入最新的版本, 如果滿足查詢條件則等待鎖, 不滿足則直接跳過
MySQL 中, 如果 Isolation level 為 RC, 在 transaction 中, 會待 commit 才釋放 lock, 還是語句執行完畢就釋放?
語句執行完畢就釋放
MySQL 中, 如果 Isolation level 為 RC, 那 next-key lock 如何判別範圍?
拿掉 gap lock, 只剩行鎖
以下的 MySQL example image 中, 說明 dead lock 是如何產生的
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
根據加鎖原則, session A 加入 next-key lock(5,10]
因為 c 為非唯一索引, 因此繼續向後遍歷, 取得不符合的下一個值, 即 15, 根據優化原則, 索引向右遍歷取得不符合條件的值時, 退化為 gap lock, 因此最終加鎖範圍為(5,15)
這時 session B 也要加上 next-key lock, 先加 gap lock(5,10), gap lock 彼此是不衝突的, 而在要加上行鎖時鎖住了
然後 session A 此時要 insert (8,8,8), 卻被 session B 的 gap lock 鎖住了, 因此判斷為 dead lock, sessoin B 斷開

MySQL 中, 在 RR 層級, 刪除時盡量使用 limit, 原因是?
避免多餘的 gap lock 以及 row lock
以下的 MySQL example image 中, 說明為何 blocked, 為何 okay?
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
insert into t values(30,10,30);Image
Answer
根據加鎖原則, c=10, 取得 next-key lock(5,10], 因為 c 為非唯一索引, 因此繼續往後掃, 但因 limit 2, 所以只掃了兩行, 為 (c=10,id=10), 以及 (c=10,id=30)
因此, 整個鎖為(5,10], 而 10 的範圍為(c=10,id=10), (c=10,id=30), 所以 session B okay


以下的 MySQL example image 中, 說明為何 blocked, 為何 okay?
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
insert into t values(30,10,30);Image
Answer
c=10, 因此會取得(5,10]next-key lock, 因為 c 不是唯一索引, 會往後掃到第一個不符合條件的 row, 所以會掃到 c=15
在等值查詢下, 當不符合條件時, 會退化為 gap lock(10,15), 因此鎖住(5,15), 以及相對應的 id
以下的 MySQL example image 中, c 索引是如何排列的?
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
insert into t values(30,10,30);Answer

以下的 MySQL example image 中, 說明為何 blocked
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
session A 是一個範圍查詢, 理論上會取得 next-key lock(10,15], 且因為 id 為唯一索引, 因此判斷到 id=15 就不會再尋找下一個了
但 MySQL (新版本已經修復) 會掃到第一個不符合條件的 record, 即 id=20, 所以實際取得的鎖為(10,15], (15,20], 因此鎖住了 session B, C
這算 bug

以下的 MySQL example image 中, 說明為何 blocked
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
session A 是一個範圍查詢, 理論上會取得 next-key lock(10,15], 且因為 id 為唯一索引, 因此判斷到 id=15 就不會再尋找下一個了
但 MySQL (新版本已經修復) 會掃到第一個不符合條件的 record, 即 id=20, 所以實際取得的鎖為(10,15], (15,20], 因此鎖住了 session B, C
以下的 MySQL example image 中, 說明為何 blocked, 為何 okay
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
根據非唯一索引等值查詢原則, c=10, 會附加 next-key lock(5,10]
範圍查詢會繼續往後查找, 找到 c=15, 所以鎖了 next-key lock(10,15], 因此 c=15 被鎖住了
定位 c=10 時, 是等值查詢, 而向右掃到 c=15 時, 是範圍查詢

以下的 MySQL example image 中, 說明為何 blocked, 為何 okay
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
根據唯一索引等值查詢的優化原則,(5,10]的 next-key lock 退化為行鎖, 只鎖 id=10
範圍查詢會繼續往後查找, 找到 id=15, 所以鎖了 next-key lock(10,15], 因此 id=15 被鎖住了
定位 id=10 時, 是等值查詢, 而向右掃到 id=15 時, 是範圍查詢

以下的 MySQL example image 中, 如果我要保持 share lock, 並且讓 session B 也 blocked, 該怎麼做?
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
只要讓 covering index 不成立就可以了

以下的 MySQL example image 中, 如果我把 share lock 換成 exclusive lock, 結果會變成? 為什麼?
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
結果會變成兩個都 blocked
要是 for update, MySQL 會將 primary key 上符合條件的 row 加鎖
根據加鎖原則, 單位為 next-key lock, 因此加鎖範圍為(0,5]
當索引為非唯一索引時, 會繼續向後遍歷, 直到找到第一個不符合的值, 第一個不符合的值為 c=10, 因此會掃過的地方都會加鎖, 因此加一個 next-key lock(5,10]
根據優化原則, 索引上的等值查詢, 最後一個不滿足等值條件的 next-key lock 會退化為 gap lock, 因此(5,10]退化為(5,10)
根據加鎖原則, 只有訪問到的才會加鎖, 此 query 使用了 covering index, 因此只鎖 covering index 的部分, 沒鎖主鍵, 所以 session B okay
以下的 MySQL example image 中, 說明為什麼 session B 為何 blocked, 而 session C 為何 okay
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
根據加鎖原則, 單位為 next-key lock, 因此加鎖範圍為(0,5]
當索引為非唯一索引時, 會繼續向後遍歷, 直到找到第一個不符合的值, 第一個不符合的值為 c=10, 因此會掃過的地方都會加鎖, 因此加一個 next-key lock(5,10]
根據優化原則, 索引上的等值查詢, 最後一個不滿足等值條件的 next-key lock 會退化為 gap lock, 因此(5,10]退化為(5,10)
根據加鎖原則, 只有訪問到的才會加鎖, 此 query 使用了 covering index, 因此只鎖 covering index 的部分, 沒鎖主鍵, 所以 session B okay
以下的 MySQL example image 中, 說明為什麼 session B 為何 blocked, 而 session C 為何 okay
Table Schema
CREATE TABLE `t` (
`id` int(11) NOT NULL,
`c` int(11) DEFAULT NULL,
`d` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `c` (`c`)
) ENGINE=InnoDB;
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);Image
Answer
根據加鎖原則, 加鎖單位為 next-key lock, session A 的加鎖範圍為(5,10]
根據優化原則, 這是一個等值查詢, 而 (id=7), 而 id=10 不滿足查詢條件, next-key lock 退化成 gap lock, 因此最終加鎖範圍為 (5,10)

以下的 MySQL example image 的意思是?
- Example
- Answer
除了鎖上紀錄之外, 還加上了 gap lock, 以防止新插入

MySQL 中, 幻讀專指 update 後的數據還是新插入的行?
新插入的行
以下的 MySQL example code, 假設 b 在 table 中的值都是 ‘1234567890’, 那結果會是? 會跑很久嗎? 為什麼?
- Example
CREATE TABLE `table_a` ( `id` int(11) NOT NULL, `b` varchar(10) DEFAULT NULL, PRIMARY KEY (`id`), KEY `b` (`b`)) ENGINE=InnoDB;
select * from table_a where b='1234567890abcd'; - Answer
結果為空
會
engine 在執行時, 因為 varchar(10) 的關係, 會將帶入的 b 截斷為 10 character, 即 ‘1234567890’, 而在引擎中, 符合該條件的有十萬筆, 因此會有十萬次回表, 而每一次取得結果返回 server 層時, server 會再做一次判斷, 結果不吻合, 因此返回空
以下的 MySQL example images 的意思是?
- Example
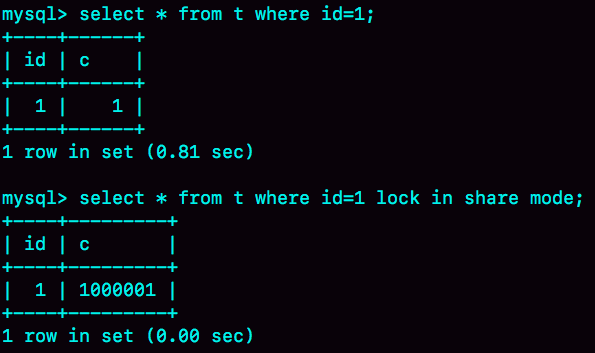


- Answer
session A 的第一個 select 語句耗時較久, 因為該 row 其實已被 update 100 萬次, 代表有 100 萬個版本, 而該 session 的 transaction 版本是在 100 萬次 update 之前, 因此會經由 undo log 返回一百萬個 update 之前的結果, 因此耗時較久
第二個 select 使用當前 read, 即取得最新的版本, 所以不須經過 undo log 回朔, 因此較快
以下的 MySQL example image 的意思是?
- Example
- Answer
id 4 佔了 MDL read lock
id 5 flush table 需要取得 MDL write lock, 但 id 4 的 read lock 要先釋放
id 6 以及後面的 process 都會被 id 5 卡住

以下的 MySQL example code 的意思是?
- Example
select blocking_pid from sys.schema_table_lock_waits;
- Answer
找出 blocking pid
MySQL 中, performance_schema 是什麼意思?
開啟後, 搭配 sys 可以快速找到 blocking_pid, 但會損失 10% 性能
以下的 MySQL example image 的意思是?
Example
Answer
select * from t where id=1被 MDL block 住了

以下的 MySQL example code 中, 如果 d.tradeid 的 character set 是 utf8, 而 l.tradeid 是 utf8mb4, 那會使用所以樹搜索嗎? 為什麼? 可以怎麼修改?
- Example
select l.operator from tradelog l , trade_detail d where d.tradeid=l.tradeid and d.id=4;
- Answer
不會
因為 utf8mb4 為 utf8 的 superset, 因此會變成 CAST(d.tradeid as utf8mb4)=l.tradeid, 進而破壞索引的有序性
將 where 條件對調就行了
以下的 MySQL example code, 假設 id 的 column type 為 int, 是否可以使用索引樹搜索?
- Example
select * from tradelog where id="83126";
- Answer
可以, 因為會變成select * from tradelog where id = CAST(83126 as int), 不影響 id 有序性
以下的 MySQL example image 的意思是?
- Example
- Answer
MySQL 將 string 轉為 int

以下的 MySQL example code 的意思是?
- Example
select "10" > 9;
- Answer
可以得到 MySQL 對於 string 與 int 的轉換規則, 若是 1 代表將 string 轉為 int, 若是 0 代表將 int 轉為 string
以下的 MySQL example code 中, 索引沒有作用, 可能是什麼原因?
- Example
select * from tradelog where tradeid=110717;
- Answer
可能是 tradeid 的 column type 不是 int, 然後會將 string 轉為 int, 變成select * from tradelog where CAST(tradid AS signed int) = 110717;, 當 tradeid 使用了 function, 便失去樹搜索的功能
以下的 MySQL example code, 會使用索引快速定位嗎? 為什麼? 該怎麼修改?
- Example
select * from tradelog where id + 1 = 10000
- Answer
不會, 因為優化器偷懶 XD
id = 10000 - 1
MySQL 中, 為什麼對索引使用 function, 會讓索引失效?
因為 function 可能會破壞索引的有序性, 就算最後有使用索引, 也可能只是使用 full index scan, 而不不是使用樹搜索快速定位
以下的 MySQL image 的意思是?
- Example
- Answer
對索引使用函數可能會破壞索引的有序性, 優化器會因此放棄走樹搜索功能

以下的 MySQL example code 掃描的總行數是?
- Example
select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
id1 = select * from t limit @Y1,1;
id2= select * from t where id > id1 limit @Y2-@Y1,1;
select * from t where id > id2 limit @Y3 - @Y2,1; - Answer
C + (Y1 + 1) + (Y2 - Y1 + 1) + (Y3 - Y2 + 1)
以下的 MySQL example code 掃描的總行數是?
- Example
select count(*) into @C from t;
set @Y1 = floor(@C * rand());
set @Y2 = floor(@C * rand());
set @Y3 = floor(@C * rand());
select * from t limit @Y1,1; //在应用代码里面取Y1、Y2、Y3值,拼出SQL后执行
select * from t limit @Y2,1;
select * from t limit @Y3,1; - Answer
C + (Y1 + 1) + (Y2 + 1) + (Y3 + 1)
所以, 如果遇到需求是每次打開 APP 提供給使用者隨機幾個單字的話, 那較佳的實踐是?
使用 redis 儲存整個單字庫, 如果數據量不大的話
以下的 MySQL example code 的意思是?
- Example
select count(*) into @C from t;
set @Y = floor(@C * rand());
set @sql = concat("select * from t limit ", @Y, ",1");
prepare stmt from @sql;
execute stmt;
DEALLOCATE prepare stmt; - Answer
取得所有 row 的數量
row number * rand(), rand() 即 0~1 的小數, 配上 floor, 所以假如 row number 是 10, 可能的數就會介於 0~9
即 offset 0~9 limit 1, 由於 limit 後面的函數無法直接接 variable, 所以使用 concat()
DEALLOCATE prepare 為釋放當次 prepare 資源
以下的 MySQL example code 的意思是?
- Example
select max(id),min(id) into @M,@N from t ;
set @X= floor((@M-@N+1)*rand() + @N);
select * from t where id >= @X limit 1; - Answer
取得最大 id, 最小 id
@M-@N+1 代表總共有幾個 row (如果中間有空洞, 這並不準確),* rand()代表* 0 ~ 1的小數, 最後+ @N使值不會小於 @N 或 @M
最後, 取得 id >= @X 的第一個數字
缺點就是, 如果之間有空洞, 那就不滿足嚴格的隨機
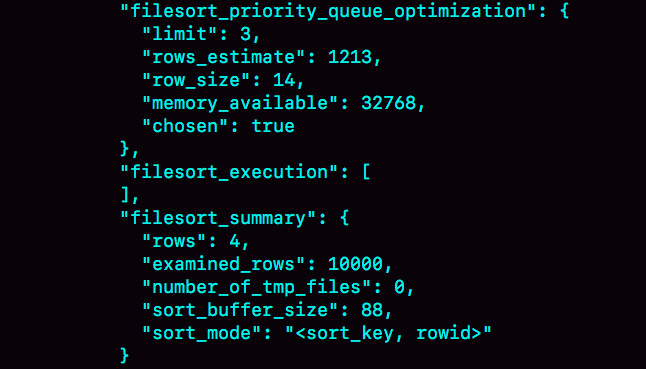
以下的 MySQL example image 的意思是?
- Image
- Answer
使用對列優先演算法 (filesort_priority_queue_optimization)來排序, 先組成一個 stack (limit 3), 再依序跟其他的 row 比較, 最終取得 R 值最小的 3 個 row (滿足 limit 3)

以下的 MySQL example image 中, 使用的是哪一種排序演算法?
- Image
- Answer
優先隊列演算法 (filesort_priority_queue_optimization)
以下的 MySQL example code 的意思是?
- Example
show global variables like 'sort_buffer_size';
- Answer
取得 current sort_buffer_size 的值
MySQL InnoDB 中, internal_tmp_disk_storage_engine 的意思是?
定義 disk 臨時表該使用哪個 engine
MySQL InnoDB 中, disk 臨時表使用的默認 engine 是?
InnoDB
MySQL InnoDB 中, tmp_table_size 的意思是?
當超過這個值, 內存臨時表會轉為 disk 臨時表
MySQL InnoDB 中, 如果 primary key 存在, 那 row_id 是?
primary key
MySQL InnoDB 中, 如果把 primary key 刪了, 那還會有 primary key 嗎?
會自動生成長度為 6 bytes 的 row_id 當作 primary key
以下的 MySQL example image 中, 如果我的 sql query 是 select word from words order by rand() limit 3;, 且資料庫中有 10000 筆資料, 那照這個圖的流程, 共會讀取幾筆資料?
- Image
- Answer
20003 筆
從主表讀入臨時表, 10000 筆, 從臨時表讀入 buffer sort, 10000 筆, 從 buffer sort 取得在臨時表的 3 筆資料

以下的 MySQL example image 中, 簡述一下各個流程
- Image
- Answer
(1) 在 memory 中建立一個臨時表, 表中有兩個欄位, r 為 double, w 為 varchar
(2) 從 words table 按 primary key 順序取出 word, 對每一個 word 使用 rand(), 記為 r, 1 > r > 0
(3) 初始化 sort_buffer, 欄位為 r (rand) 以及 position (row_id), 將臨時表中的資料存到 sort buffer 中
(4) sort buffer 中進行排序
(5) 根據排序後 sort buffer 的前三筆的位置資訊 (row_id), 從臨時表中取出相對應的三筆資料
MySQL InnoDB 中, 為了節省 disk I/O, 在排序時會選擇哪種排序法?
row_id
以下的 MySQL example image 中, Extra column 中的意思是?
- Image
- Answer
Using temporary 代表需要使用臨時表
Using filesort 代表有排序需求, 所以會在臨時表上排序

MySQL 中, 當 binlog_format=row 且 binlog_row_image=FULL, 代表什麼?
代表 binlog 需要記錄所有的字段, 所以在 read 的時候會 read 全部的資料, 會影響在 transaction 中, 當前讀的行為, 原本不會去讀的會變成全讀, 所以也不就不會做不必要的 update, 也就不會產生新的可見 version
以下的 MySQL example image 中, 為什麼結果是 (1,3)
- Image
- Answer
因為 update 中沒有足夠的訊息來判斷該 row 不需要再被更新了, 因此實際上 session A 還是更新了一次, 並在該 transaction 中加入了該 transaction 對該 row update 而生成的一個新的 version, 因此結果為 (1,3)

以下的 MySQL example image 中, 為什麼結果是 (1,2)
- Image
- Answer
因為 update 的 where 中, 有 a = 3, 觸發當前讀, 進而發現該 row 的值已經是 3, 判斷不需要更新, 因為沒有在 transaction 中產生新的 view, 所在 session A 的 transaction 中, (1,3) 是不可見的

以下的 MySQL example image 中, using index 的意思是?
- Image
- Answer
表示有使用覆蓋索引

以下的 MySQL example image 的意思是?
- Image
- Answer
使用聯合索引, 並且符合覆蓋索引, 從 index 中取得 city 之後, 不需到原表取值, 也不需進去 sort_buffer 排序, 直接返回結果集

以下的 MySQL example image 的意思是?
- Image
- Answer
因為使用了 compound index, 原本需要排序的 name 在 index 中已經是有序的了, 因此取得 city 後, 直接返回原表取得需要的資料, 然後就不需進去 sort_buffer 排序, 而是直接返回結果集

MySQL 中, 為什麼 row_id 排序比全字段排序掃描的行數多?
因為最後還要到原表去取需求的資料, 而不是排序完直接返回
以下的 MySQL example image 的意思是?
- Image
- Answer
使用 row_id 排序
初始化 sort_buffer, 確定要放入字段為 id, name
從 index city 取得 id, 並到 table 經由 id 取得 id, name, 再放到 sort_buffer
從 index 取下一筆紀錄, 直到將所有符合條件的 id, name 都放到 sort_buffer
在 sort_buffer 中排序
按照順序到 table 使用 id 取得全部需求字段, return
最後一個步驟不需額外耗費內存儲存結果, 而是直接返回

MySQL 中, 何謂 row_id 排序?
只將必要的字段放到 sort_buffer, 即 primary key 以及要排序的 column
MySQL 中, 何謂全字段排序?
將要 return 的資料全部丟到 sort_buffer 中排序
MySQL 中, max_length_for_sort_data variable 的用途是?
定義 sort data 的最大長度, 若是單行超過這個長度, 會採用另外一種算法
以下的 MySQL example image 中, packed_additional_fields 的意思是?
- Image
- Answer
排序過程對字符串做緊湊處理, 即使字段定義是 varchar(16), 排序過程還是按照實際長度分配空間

以下的 MySQL example image 中, examined_rows 的意思是?
- Image
- Answer
排序的行數
MySQL 中, 若使用外部文件來排序, 通常會使用哪個演算法?
歸併演算法
以下的 MySQL example image 中, number of tmp files 的意思是?
- Image
- Answer
共使用了幾個外部 disk 文件來幫助排序
MySQL 中, 如果 sort_buffer_size 小於要 sort 的資料量的話, 會發生什麼事?
會使用外部 disk 臨時文件來 sort
MySQL 中, 什麼是 sort_buffer_size?
sort_buffer 的 size
以下的 MySQL example code 的意思是?
- Example
SET optimizer_trace='enabled=on';
select VARIABLE_VALUE into @a from performance_schema.session_status where variable_name = 'Innodb_rows_read';
select city, name,age from t where city='杭州' order by name limit 1000;
SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
select VARIABLE_VALUE into @b from performance_schema.session_status where variable_name = 'Innodb_rows_read';
select @b-@a; - Answer
暫時的打開 optimizer_trace
記下初始 read row
執行 query
取得 optimizer_trace
記下 query 後的 read row
取得總共 read row
MySQL 中, 會給每個 session 分配一塊內存用以排序, 稱為?
sort_buffer
以下的 MySQL example image 的意思是?
Image
Example
select city,name,age from t where city='杭州' order by name limit 1000 ;
Answer
從 index 中取得符合 where condition 的 primary key
回表取得 city, name, age
將值到放 sort buffer 中, 排序
返回結果

以下的 MySQL example code 的意思是?
- Example
begin; /*启动事务*/
insert into `like`(user_id, liker_id, relation_ship) values(A, B, 1) on duplicate key update relation_ship=relation_ship | 1;
select relation_ship from `like` where user_id=A and liker_id=B;
/*代码中判断返回的 relation_ship,
如果是1,事务结束,执行 commit
如果是3,则执行下面这两个语句:
*/
insert ignore into friend(friend_1_id, friend_2_id) values(A,B);
commit;
mysql> begin;
insert into `like`(user_id, liker_id, relation_ship) values(B, A, 2) on duplicate key update relation_ship=relation_ship | 2;
select relation_ship from `like` where user_id=B and liker_id=A;
/*代码中判断返回的 relation_ship,
如果是2,事务结束,执行 commit
如果是3,则执行下面这两个语句:
*/
insert ignore into friend(friend_1_id, friend_2_id) values(B,A);
commit; - Answer
用 single row 來實現 status 1, 2, 3|為按位或, 會將數字轉為二進制再運算, 比如說 1|2 = 3, 因為 01 (1), 10 (2), 所以會變成 11, 即 3, 而 2|2 還是 2, 因為 10, 10, 會等於 10, 而 1|1 還是 1, 因為 01, 01, 會等於 01, 因為還是 1
最後的 ignore, 當 insert 重複資料時, 會 ignore, 以免 error 讓 transaction rollback
MySQL 中, 如果出現 crash 的情況, 如果恢復數據頁的內存?
若判斷數據頁有丟失更新的可能, 會先將數據頁的資料讀到內存, 在使用 redo log 去更新內存到 crash 前的內容
MySQL 中, 如果是正常運行的實例, 刷髒頁時, 會使用到 redo log 嗎?
不會, 會把內存刷到 disk
MySQL 中, redo log 建議設置多大?
如果 disk 有幾個 TB 大小, 建議 4 個文件, 每個 1 GB
以下的 MySQL image 中, 如果只使用 binlog 而不使用 redolog, 當 crash 了, 會出現什麼情形?
- Image
- Answer
transaction 2 因為尚未提交, crash 後會藉由 binlog2 來復原, 但因為 MySQL 是使用 WAL 方式, 所以 transaction 1 有可能因為內存上的數據頁丟失而一起丟失, 但因為 binlog 顯示已提交, 所以並不會重新執行一次 binlog1, 因此 transaction 1 數據可能丟失

MySQL 中, redo log 和 binlog 是如何關聯的?
會有共同的 XID
MySQL 中, bin-checksum 的用途是?
校驗 binlog 的完整性
MySQL 中, 當發生 crash, MySQL 如何判斷 binlog 是否完整?
statement 格式的 binlog, 最後會有 commit;
row 格式的, 最後會有一個 XID event
以下的 MySQL example 中, 比較各種 count() 的效能以及行為?
- Example
count(*)
count(1)
count(id)
count(columnName) - Answer
count(*) 會 scan 整張表, 但不取值, server 層會對於每一行的回傳累加 1, 屬於 MySQL 特別優化的選項, 優先選擇
count(1) 會 scan 整張表, 但不取值, server 層會對於每一行的回傳累加 1
count(id) 會 scan 整張表, 取 id, server 層會對於每一行的回傳累加 1
count(columnName) 會 scan 整張表, 如果是 not null, 會取出每一行, 判斷不為 null, 累加, 若為 nullable, 則取出每一行, 並且判斷不為 null 才累加, 效率最差
MySQL 中, count(*) 跟 count(columnName) 差異是?
count(*) 會回傳總行數, 而 count(columnName) 會回傳該 column 不為 null 的 count
MySQL 中, 如果我要統計一個表上總共有幾列, 但該表上的 row 數量很多, 有什麼好解法?
可以獨立建立另外一張表, 每當該表上面有新增, 就在這張表上 + 1, 跑 transaction, 並且如果高併發的話, 可以分成多行, 在取多行的加總, 以減少 dead lock detection 的產生
MySQL 中, show table status 取得的 row 準確嗎?
不準, 誤差可能高達 40~50%
MySQL 中, 若要使用 count(), 使用哪個語句會有優化過? 如何優化?
count(*), 會掃描最小的索引樹
MySQL 中, 如果機器規格很高, 但 redo log 設得很小, 那會發生什麼事?
因為 redo log 很快就被寫滿, 會被迫一直進入停止 update, 推進 checkpoint, 要 flush page 的狀態, 造成 disk 壓力明明不大, 但性能卻週期性的下降
MySQL 中, 重建表有哪兩種推薦的方式?
alter table t engine = InnoDB
gh-ost
以下的 MySQL example code 的意思是?
- Example
optimize table t
- Answer
recreate table and analyze it
以下的 MySQL example code 的意思是?
- Example
alter table t engine = InnoDB
- Answer
會重建一個表, 實際上是alter table t engine=innodb,ALGORITHM=copy;
MySQL 中, inplace 跟 online 是否同意思?
不同, 可以有 online 效果的肯定是 inplace algorithm, 但 inplace algorithm 不見得可以 online, 比如 full-text index, spatial index
MySQL 中, 如果我有一個 1TB 的 table, disk 空間為 1.2TB, 那我能不能做一個 DDL 呢?
不行, 因為 tmp_file 也會佔空間
MySQL 中, inplace 的意思是?
整個 DDL 過程都是在 innoDB 內部完成的, 速度較快, 就像是原地操作
MySQL 中, 若要比較保險的重建表, 可以使用哪個工具?
gh-ost
以下的 MySQL image 中, 在 alter 語句啟動後, MDL Write lock 會立即降級為 MDL Read lock, 那為什麼不乾脆解鎖呢?
- Image
- Answer
要避免在 alter 過程中, 有其他 DDL 插入

以下的 MySQL image 中, Online DDL 是如何實現的?
- Image
- Answer
在 alter 語句啟動時需先拿到 MDL Write lock, 拿到後就會立即降級為 MDL Read lock, 所以不影響 DML 的操作
以下的 MySQL image 的意思是?
- Image
- Answer
- state 1 代表舊表, 佈滿空洞
- state 2 會建立一個 tmp file, 當執行 alter 語句時會需要 MDL Write lock, 拿到後在複製資料之前會降級為 MDL Read lock, 以實現 online DDL, 然後開始將資料從舊表複製到 tmp file, 於此同時進來的 query, 會被記在 row log 當中
- state 3 資料複製完畢後, 會將 row log 中的資料一併複製到 tmp file
- state 4 將 tmp file 取代舊表
MySQL 中, 如何才能釋放刪除資料後的空洞?
重建表
以下的 MySQL image 的意思是?
- Image
- Answer
當數據頁原本是滿的, 從中插入, 會申請一個新的數據頁, 並分裂成兩個數據頁, 產生空洞
MySQL 中, 如果使用 delete 把所有的資料都刪了, 資料檔案的大小會縮小嗎?
不會, 只會變得可復用而已
以下的 MySQL example code 的意思是?
- Example
SET @wsum := 0;
SELECT
t1.*
FROM (
SELECT
m.*,
(@wsum := @wsum + m.weight) AS cumulative_weight
FROM
test1 m
ORDER BY
m.turn ASC) t1
WHERE
t1.cumulative_weight <= 1000
ORDER BY
turn DESC
LIMIT 1; - Answer
設一個變數, 讓變數在 table 中累加某個值, 進而可取得累加到某個點的所有 row
以下的 MySQL image 中, 如果刪掉 R4, 然後插入一個 id = 800 的 row, 可以復用原本這一行的空間嗎?
- Image
- Answer
不行

以下的 MySQL image 中, 如果刪掉 R4, 然後插入一個 id = 400 的 row, 可以復用原本這一行的空間嗎?
- Image
- Answer
可以
以下的 MySQL image 中, 如果刪掉 R4, 那硬碟文件會縮小嗎?
- Image
- Answer
不會, 只會標記為可復用
MySQL 中, innodb_file_per_table 參數建議設置為?
on, 這樣當 drop table 就可以刪掉空間, 反之因為是儲存在共享空間, 刪掉空間也不會回收
以下的 MySQL example code 的意思是?
- Example
innodb_file_per_table
- Answer
決定表數據要儲存在共享空間, 還是單獨 .idb 結尾的檔案
MySQL 中, 當 checkpoint 推進時, 如何判斷要 flush 的 page 是乾淨的還是髒的?
當 flush 時, 會取得最舊的 LSN, 對比內存中的 page, 要是該 LSN 不存在於內存, 代表刷過了, 即可跳過
MySQL 中, 當 checkpoint 推進時, 如何選擇要 flush 的 page?
每個 buffer pool instance 都會有一個 flush list, 每次寫 redo log 都會有一個 LSN, 會 flush LSN 最小的 page, 代表最老的 page
MySQL 中, 不建議讓髒頁比例到達幾%?
75 %
MySQL 中, 什麼時候會推進 redo log 的 checkpoint?
當 redo log 快寫滿時
MySQL 中, 當因為內存不足必須要 flush dirty page 時, 會推進 redo log 的 checkpoint 嗎?
不會
MySQL 中, flush, purge, merge, 分別代表的意思是?
- flush: 刷髒頁
- purge: 清 undo log
- merge: sync change buffer
MySQL 中, 什麼是 LSN?
log sequence number
MySQL 中, redo log 寫滿, 必須得 flush dirty page, 這種情況是正常的嗎?
不正常, 應該盡量避免, 因為出現這種情況時, 整個系統都無法再接受更新
MySQL redo log 中, 當內存不夠用時, 需要淘汰資料庫的 page, 那如果 page is dirty, 是什麼原因一定要 flush redo log, 而不能直接釋放 page, 當下次讀該 page 的時候, 再從 redo log 去拿正確資料?
效能考量, 每次釋放 page 時都 flush 可以確保 page 有兩種狀態
- 如果內存中存在該 page, 那該 page 的資料一定是最新的
- 如果內存中不存在該 page, 該 disk 上的資料一定是最新的
MySQL 中的 innodb_flush_neighbors 建議怎麼設?
如果是傳統 disk, 設為 1, 若是 SSD, 設為 0
MySQL 中的 innodb_flush_neighbors 的意思?
當 flush dirty page 時, 若相鄰的 page 也是 dirty page, 就一起 flush, 會一直連坐下去, 直到相鄰的 page 非 dirty
MySQL 中的 innodb_io_capacity 建議設為?
機器的 IOPS
以下的 fil command 的意思是?
- Example
fio -filename=$filename -direct=1 -iodepth 1 -thread -rw=randrw -ioengine=psync -bs=16k -size=500M -numjobs=10 -runtime=10 -group_reporting -name=mytest
- Answer
取得機器 IOPS 數值
什麼是 IOPS?
Input/Output Operations Per Second
MySQL 中, 當要讀入一個 page, 但 buffer pool 已經滿了, 會怎麼做?
會將最久沒有使用的 page 淘汰, 若是乾淨的則直接釋放, 若是髒的則 flush 後釋放
MySQL 中, buffer pool 中的內存頁, 通常有哪三種狀態?
- 還未使用
- 已使用, 是乾淨的
- 已使用, 是髒的
MySQL 中, 通常有哪四種情況會需要 flush dirty pape?
- redo log 寫滿了
- 內存用光了
- 空閒時
- 關機時
MySQL 中, 通常什麼情況會造成 MySQL 頓一下, query 速度忽然變得極慢?
flush dirty page
以下的 MySQL image 中, 為什麼會選錯索引?
- Example
- Answer
因為 session A 還沒有提交前, session B 是無法刪除資料的, 就算刪除了, undo log 也會留著, 索引會有兩份, 一份是 session B delete 語法提交前, 一份是提交後

MySQL 中, 若使用倒序或 crc hash 來儲存, 有何共通點?
都不支援 range scan
MySQL 中, 若使用倒序或 crc hash 來儲存, 在查詢效率差異為何?
hash 雖說還是可能會重複, 但機率並不高, 反觀 prefix index 重複機率較高, 因此效率上 hash 勝出
MySQL 中, 若使用倒序或 crc hash 來儲存, 在 CPU cost 上差異為何?
reverse cost 會小一些
MySQL 中, 若使用倒序或 crc hash 來儲存, 在儲存空間上差異為何?
倒序不需額外儲存空間, 但考量到前綴的字數需要一定數量來區分, 所以差異並不大
以下的 MySQL example code 的意思是?
- Example
alter table t add id_card_crc int unsigned, add index(id_card_crc);
select field_list from t where id_card_crc=crc32('input_id_card_string') and id_card='input_id_card_string' - Answer
額外建立一個 column, 在 insert 時使用 crc32 hash id_card, 並存到這個 column, 這樣在 select 時就可以利用這個 column 上的 index 來 query id_card, 但因為 crc32() 可能會有重複的 hashed string, 因此要再比對 id_card 是否一致
以下的 MySQL example code 的意思是?
- Example
select field_list from t where id_card = reverse('input_id_card_string');
- Answer
身分證很有可能前面好幾個字母都是相同的, 可以採用倒序儲存, 並配合 prefix index
MySQL 中, prefix index 是否支援 covered index?
不支援
以下的 MySQL example code 的用意是?
- Example
mysql> select count(distinct email) as L from SUser;
mysql> select
count(distinct left(email,4))as L4,
count(distinct left(email,5))as L5,
count(distinct left(email,6))as L6,
count(distinct left(email,7))as L7,
from SUser; - Answer
判斷不同字數的 prefix index 與實際上的不同值數量差距多少, 以決定最佳的 prefix index 長度
MySQL 中, 有哪幾種方法可以修正 MySQL 選錯索引?
- 使用 force index 語法
- 修改語句
- 使用 analyze 重新計算索引
- 刪除不必要索引
以下的 MySQL example code 的意思是?
- Example
analyze table t
- Answer
重新統計索引
以下的 MySQL example code 的意思是?
- Example
innodb_stats_persistent
- Answer
決定是否將索引統計存在 disk 或 memory
on 的話, N = 20, M = 10
off 的話, N = 8, M = 16
當變更行數超過 1/M 時, 會觸發重新索引統計
MySQL 中, 基數 (Cardinality) 如何求得?
取 n 個 page, 分別計算每個 page 中的不同值數量, 再將所有 page 的不值相加, 再除以 n, 最後乘以總 page 數量
MySQL 中, 何謂基數 (Cardinality)?
索引中值不同的數量, 數量越高, 基數越大, 索引的效果也越好, 若是數量很低, 代表索引中幾乎每個值都一樣, 那基數就低, 效果就不好
MySQL 中, insert 時, 可以使用 change buffer 嗎?
primary key 不行, 但 secondary index 可以
MySQL 中, .idb 檔案是?
對應表數據空間的對應檔案
MySQL 中, ibdata1 檔案是?
系統表空間的對應檔案
MySQL 中, redo log 與 change buffer 主要節省的效益分別是?
redo log: 將隨機寫 disk I/O, 節省為順序 I/O
change buffer: 隨機讀 disk I/O 消耗
以下的 MySQL image 的意思是?
- Image
- Answer
當讀 page 1 時, 直接從內存返回
當讀 page 2 時, 從 disk 將 page 2 讀入內存, 並 merge change buffer 的紀錄, 返回

以下的 MySQL image 的意思是?
- Image
- Answer
update 的資料處於內存中, 直接 update 內存
update 的資料所在 page2 不處於內存中, 直接在內存中的 change buffer 寫下紀錄
兩上面兩個 update 寫入 redo log

MySQL 中, 如果有一個情境, 所有的 update 結束後都會伴隨著 select, 那建議關掉哪個設定? 為什麼?
change buffer
因為 change buffer 會在每次 select 時都去 merge 原 page, 產生 I/O cost, 若能在 select 與 select 之間寫入動作越多次的話才能真正發揮 change buffer 效果, 若是每次 update 結束就 select 就相當於每次都 merge, 如此一來便失去 change buffer 的意義
MySQL 中, 什麼樣的情境對 change buffer 來說是成效最大的?
寫多讀少
MySQL 中, 為什麼唯一索引在寫入時的 cost 比一般索引大?
一般索引可以使用 change buffer, 唯一索引需要將 page 讀入內存, 這個動作需要訪問隨機 I/O, 因此成本很高
以下的 MySQL image 中, 如果要插入 (4,400), 如果該 page 不在內存中, 一般索引與唯一索引分別的操作是?
- Image
- Answer
一般: 將更新紀錄在 change buffer, 結束
唯一: 將 page 讀入內存, 找到 3-5, 判斷有無衝突, 插入, 結束

以下的 MySQL image 中, 如果要插入 (4,400), 如果該 page 已經在內存中, 一般索引與唯一索引分別的操作是?
- Image
- Answer
一般: 找到 3-5 之間的位置, 插入, 結束
唯一: 找到 3-5 之間的位置, 判斷有無重複, 插入, 結束
MySQL 中, 當 innodb_change_buffer_max_size 設為 50 時, 意思是?
change buffer 的大小最多只能佔用 buffer pool 的 50%
以下的 MySQL example code 的意思是?
- Example
innodb_change_buffer_max_size
- Answer
設定 change buffer 的 size
MySQL 中, 唯一索引可以使用 change buffer 嗎? 為什麼?
不行, 因為寫入前都要確定該筆資料不存在於資料庫已達到 unique, 所以每次都會將該 page 讀入內存
MySQL 中, change buffer 何時會觸發 merge?
訪問該 page
定時 merge
database shutdown
MySQL 中, change buffer 與原 page sync 的過程稱為?
merge
MySQL 中, 當 update 時, 如果該 page 不處於內存當中, 會如何?
寫入 change buffer, 並在下次查詢時, 將該筆資料所在的 page 讀入內存, 並執行 change buffer 中與該筆資料有關的相關操作
MySQL 中, 當 update 時, 如果該 page 已經處於內存當中, 會如何?
直接更新
MySQL 中, change buffer 會被持久化嗎?
會
MySQL 中, 如果說我的語法是 select id from T where k=5, 那一般索引與唯一索引的查詢差異在於?
一般索引查到第一筆 k=5 的資料後, 會繼續往下查找, 直到查到 k != 5 才會停下
唯一索引查到第一筆 k=5 的資料後就會停下
MySQL 中, 如果一個 column 已在 APP 層設置 unique 邏輯, 一般索引與唯一索引, 哪個效能較好? 為什麼?
一般索引
當讀資料時, 是將整個 page 讀入內存, 而當已經找到第一筆資料時, 代表該筆資料所處的 page 已經被讀入內存了, 這時多讀一次 (一般索引) 的 cost 幾乎微乎其微
當 update 時, 一般索引可以使用 change buffer, 但唯一索引不行, 所以唯一索引會多了 I/O cost, 主要效能差異在這
MySQL 中, 如果一個 column 已在 APP 層設置 unique 邏輯, 那 index 該選擇一般索引還是唯一索引?
一般索引
以下的 MySQL example code 的意思是?
- Example
update t set num=num-200 where num >= 200;
- Answer
為避免 race condition, 加了 where num = 200, 因為 transaction 中, update 會使用當前讀 (current read), 因此會判斷 num = 200, 若不是, 代表庫存不足, 直接報錯
以下的 MySQL image 中, 若為 RC Isolation, transaction A, B 的 select 結果分別是多少, 為什麼?
- Image
- Answer
A: 2, 因為 trx B 尚未提交, 但 trx C 已提交, 所以 C 為可見, B 為不可見
B: 3, 為當前版本, 且 trx C 已提交, 可見

MySQL 中, start transaction with consistent snapshot 在 RC Isolation 中, 有意義嗎?
沒意義, 等同 start transaction, 因為 RC 是每個語句都會產生新的 view
MySQL 中, RR Isolation 與 RC Isolation 的主要區別是?
RR: 在 transaction 中使用同一個 view
RC: 每個語句都會產生一個新的 view
MySQL 中, 在 transaction 中如何使 select 使用當前讀 (current read)?
加鎖, share mode 或 exclusive mode 都可
MySQL 中, 當我在 transaction 中使用 atomic update, 為什麼不是 based on view 中的版本, 而是最新版本?
因為 update 使用的是當前讀 (current read)
MySQL 中, 何謂當前讀 (current read)?
不讀 trx view 中的資料, 而是最新版本的資料
MySQL RR 中, 若 trx A 於 trx B 創建 view 之前提交, 那可見或不可見?
可見
MySQL RR 中, 若 trx A 於 trx B 創建 view 之後才提交, 那可見或不可見?
不可見
MySQL RR 中, 若 trx 版本未提交, 那可見或不可見?
不可見
以下的 MySQL example image 中, transaction A 的結果是? 為什麼?
- Description:
- 系統內只有一個活躍 trx_id 99
- transaction A, B, C 的版本分別是 100, 101, 102
- 三個 transaction 開始前, (1,1) 這一行的 rwo trx_id 為 90
- Image
- Answer
為 1
row (1,1) 的版本為 90, 小於[99,100]的低水位, 表示已提交, 可見
row (1,2) 的版本為 102, 大於[99,100]的高水位, 表示 transaction A 創建之後才建立的 trx, 不可見
row (1,3) 的版本為 101, 大於等於[99,100]的高水位, 表示 transaction A 創建之後才建立的 trx, 不可見

以下的 MySQL example picture 中, 未開始的事務如何定義?
- Example
- Answer
當前系統已產生的最大 trx_id + 1 以上的 trx_id 都視為未開始

以下的 MySQL example picture 中, 已提交的事務如何定義?
- Example
- Answer
由當前事務更新, 或許 trx_id不存在於未提交事務集合, 並且低於高水位, 代表已提交
以下的 MySQL example picture 中, 未提交事務集合的內容是?
- Example
- Answer
所有當前活躍的 trx_id array
以下的 MySQL example picture 中, 高水位的意思是?
- Example
- Answer
系統已產生的 trx_id 中, 最大的那一個 + 1
以下的 MySQL example picture 中, 低水位的意思是?
- Example
- Answer
未提交的 trx_id array 中, trx_id 較小的那一個
以下的 MySQL example image 的意思是?
- Example
- Answer
MySQL MVCC 的多版本
新的 transaction 需要跟 MySQL 的 transaction 系統申請一個自增 id
每個 row 依據被不同的 transaction update 過, 會有不同的版本, 並持有以下的值
被 update 後的值
update 的 transaction id
版本之間的綠色箭頭稱為 undo log, 代表邏輯的回朔上個版本, 非物理性

以下的 MySQL example schema and image 中, k 在 transaction A 以及 B 分別值是多少?
- Schema
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL,
`k` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
insert into t(id, k) values(1,1),(2,2); - Image
- Answer
transaction B 中, k = 3
transaction A 中, k = 1
因為 MySQL 的 RR 只對 read 有效, 對 update 無效

以下的 MySQL example code 的意思是?
- Example
start transaction with consistent snapshot
- Answer
當執行 transaction begin 時, 並不會立即開始 transaction, 第一句操作 DB 的語法才是 transaction 的開始處, 若要指定開始處, 可使用 example code 語法
MySQL 中, RR 跟 RC Isolation 的行鎖差異是?
RC 是逐行掃描逐行鎖, 若條件不對會立即釋放
RR 是逐行掃描逐行鎖, 會等到最終提交 transaction 時才全部釋放
以下的 MySQL example code 中, 如果 name 沒加索引, 會鎖住哪些 row?
- Example
update t set t.name='abc' where t.name='cde' limit 1
- Answer
會先查詢再更新,select * from t where name = "abc" limit 1 for update
會從開始掃描那一行開始鎖, 直到找到 name=’cde’, 掃過的行都會鎖住
以下的 MySQL example code 中, 如果 name 沒加索引, 會鎖住哪些 row?
- Example
update t set t.name='abc' where t.name='cde'
- Answer
會鎖住全表
MySQL 中, 當我使用 mysqldump –single-transaction 時, 如果這時從 master 傳來一個 DDL 的 binlog, 如下 example, 假如是時刻 4 傳來的, 會發生什麼事?
- Example
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* other tables */
Q3:SAVEPOINT sp;
/* 时刻 1 */
Q4:show create table `t1`;
/* 时刻 2 */
Q5:SELECT * FROM `t1`;
/* 时刻 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* 时刻 4 */
/* other tables */ - Answer
此時 read MDL 已經釋放, 沒有影響, 備份為修改前的表結構
MySQL 中, 當我使用 mysqldump –single-transaction 時, 如果這時從 master 傳來一個 DDL 的 binlog, 如下 example, 假如是時刻 2 到時刻 3 之間傳來的, 會發生什麼事?
- Example
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* other tables */
Q3:SAVEPOINT sp;
/* 时刻 1 */
Q4:show create table `t1`;
/* 时刻 2 */
Q5:SELECT * FROM `t1`;
/* 时刻 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* 时刻 4 */
/* other tables */ - Answer
此時因為 Q5 query 已經拿到 read MDL, 所以 DDL 會被 block, 直到 Q6 釋放 read MDL 之後才會執行, 會造成主從延遲
備份的會是修改前的表結構
MySQL 中, 當我使用 mysqldump –single-transaction 時, 如果這時從 master 傳來一個 DDL 的 binlog, 如下 example, 假如是時刻 2 傳來的, 會發生什麼事?
- Example
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* other tables */
Q3:SAVEPOINT sp;
/* 时刻 1 */
Q4:show create table `t1`;
/* 时刻 2 */
Q5:SELECT * FROM `t1`;
/* 时刻 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* 时刻 4 */
/* other tables */ - Answer
會在 Q5 取得資料時, 報錯 Table definition has changed, please retry transaction, 終止 mysqldump
MySQL 中, 當我使用 mysqldump –single-transaction 時, 如果這時從 master 傳來一個 DDL 的 binlog, 如下 example, 假如是時刻 1 傳來的, 會發生什麼事?
- Example
Q1:SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ;
Q2:START TRANSACTION WITH CONSISTENT SNAPSHOT;
/* other tables */
Q3:SAVEPOINT sp;
/* 时刻 1 */
Q4:show create table `t1`;
/* 时刻 2 */
Q5:SELECT * FROM `t1`;
/* 时刻 3 */
Q6:ROLLBACK TO SAVEPOINT sp;
/* 时刻 4 */
/* other tables */ - Answer
mysqldump 尚未取得表結構, 所以沒有影響, 備份後會是 DDL 修改後的表結構
MySQL 中, 將電影院的餘額分成 10 行, 10 行的加總等於電影院的餘額, 為什麼要這樣設計?
適用於高併發場景, 當高併發會去更新同一行時, 會造成大量死鎖以致於吃光效能, 所以分成多行來更新, 降低死鎖發生機率
MySQL 中, 在高併發下, 若是關閉死鎖監測, 會出現什麼問題?
因為關閉了 dead lock detection, 當鎖住時不會自動 rollback, 所以會出現大量的超時
MySQL 中, 偵測死鎖的代價是多少?
O(n的二次方), CPU 使用率極高
MySQL 中, 為什麼不可把 innodb_lock_wait_timeout 參數設定成 1s 來避免死鎖?
因為很多時候不見得是死鎖, 可能只是單純的鎖等待, 這樣會造成很多誤傷
MySQL 中, innodb_deadlock_detect 是什麼設置?
當遇到 dead lock 時, transaction row 數量比較少的那一個會主動釋放 lock
MySQL 中, innodb_lock_wait_timeout 是什麼設置?
當遇到 lock 衝突時, 要等待多久
MySQL 中, 根據二階段鎖的行為, 以下三個動作, 哪一個該放最後, 為什麼?
Example
從顧客 A 帳戶餘額扣錢
在影院 B 的帳戶餘額加錢
紀錄交易日誌Answer
在影院 B 的帳戶餘額加錢要放最後, 因為可能會有多個 session 來更新這筆紀錄, 因此最可能發生衝突, 放在越後面, 佔用鎖的時間越短
MySQL 中, 如果要鎖多行, 要把可能造成最大影響的鎖往後放還是往前放?
往後放
以下的 MySQL image 的的意思是?
Image
Answer
transaction B 會被 block, 直到 transaction A 結束後釋放鎖

MySQL 行鎖中, 何謂二階段鎖協議?
在 transaction 中, 有需要時加鎖, 但會等到 transaction 結束時才釋放
以下的 MySQL example code 的意思是?
- Example
ALTER TABLE tbl_name NOWAIT add column ...
ALTER TABLE tbl_name WAIT N add column ... - Answer
使用 DDL 時, 指定若是拿不到鎖就不等待, 或是等待指定的時間就放棄, 以防止鎖死
MySQL 中, 什麼是 FTWRL?
flush table with read lock
以下的 MySQL image 的意思是?
- Image
- Answer
session A 為 DML, MySQL 自動施加 MDL read
session B 為 DML, MySQL 自動施加 MDL read, 讀讀共享
session C 為 DDL, 嘗試取得 MDL write, 但 MDL read write 互斥, 因此 block, 需等 MDL read 釋放
session D 為 DML, 需先拿到 MDL read, 因為 MDL write priority 高於 MDL read, 因此這排在 session C MDL write 之後, 需等待 MDL write 取得並釋放

至此, 之後的 session 都將被 block, 直到 session A, B MDL read 釋放, 接著是 session C 執行, 之後才會解除 block
MySQL 中, read MDL 會影響 write MDL 嗎?
會, 讀寫互斥
MySQL 中, write MDL 會影響 write MDL 嗎?
會, 寫寫互斥
MySQL 中, read MDL 會影響 DDL 嗎?
會, 當 read MDL 存在時, 無法進行 DDL
MySQL 中, write MDL 會影響 DDL 嗎?
會, 只有拿到 MDL 的 connection 可以操作 DDL
MySQL 中, read MDL 會影響 read MDL 嗎?
不會, 讀讀共享
MySQL 中, read MDL 會影響 DML 嗎?
不會
MySQL 中, MDL read, write 什麼時候會被使用?
- read, 任何 DML 時會被加上
- write, DDL 時會被加上
MySQL 中, 假如 connection A 執行 lock tables t1 read, t2 write, 那 connection A 對 t1, t2 的權限分別為何?
t1, 可讀
t2, 可讀可寫
MySQL 中, 假如 connection A 執行 lock tables t1 read, t2 write, 那 connection B 對 t1, t2 的權限分別為何?
t1, 可讀不可寫
t2, 不可讀不可寫
MySQL 中, 什麼是 MDL?
meta data lock, 元數據鎖
MySQL 中, 表級鎖又分為哪兩種?
表鎖, 元數據鎖
MySQL 中, 當進行全局備份時, 為何建議使用 FTWRL 而不使用 set global readonly=true?
- readonly variable 的值會被用來在很多地方進行判斷, 例如判斷主從庫, 影響重大
- 當使用 FTWRL, 如果 client side 斷開連線時, 會自動釋放 lock, 但 readonly 不會, 會一直鎖住
既然可以使用 mysqldump –single-transaction 來備份, 那為什麼還會有 FTWRL 需求?
因為當有些 table 不支援 transaction 時, 就只能使用 FTWRL 來備份了
使用 mysqldump 備份時, 更新功能會受到影響嗎?
不會, 但前提是務必要加上 --single-transaction 參數
使用 mysqldump 備份時, 可加上哪個參數, 確保 view 一致?
--single-transaction
以下的 MySQL example image 的意思是?
- Example
- Answer
備份時未上鎖, 先備份 user account, 完成後, user 買了一個課程, user course 資料庫更新, 然後在備份 user course, 備份的結果變成, user 錢沒扣, 但卻多了一個課程

MySQL 中, 當在從庫上 FTWRK 時, 會產生什麼狀況?
從庫無法執行同步過來的 binlog, 會造成主從延遲, 在讀寫分離的場景會受影響
MySQL 中, 當在主庫上 FTWRK 時, 會產生什麼狀況?
備份期間無法更新, 會造成業務停擺
以下的 MySQL example code, 通常會用在什麼情境?
- Example
Flush tables with read lock
- Answer
做全庫邏輯備份
以下的 MySQL example code 的意思是?
- Example
Flush tables with read lock
- Answer
讓整個資料庫處於只讀狀態 (上讀鎖)
以下的 MySQL example code 中, 哪個 index 可以省略?
- Example
# Schema
CREATE TABLE `geek` (
`a` int(11) NOT NULL,
`b` int(11) NOT NULL,
`c` int(11) NOT NULL,
`d` int(11) NOT NULL,
PRIMARY KEY (`a`,`b`),
KEY `c` (`c`),
KEY `ca` (`c`,`a`),
KEY `cb` (`c`,`b`)
) ENGINE=InnoDB;
# 需求
select * from geek where c=N order by a limit 1;
select * from geek where c=N order by b limit 1; - Answer
ca 可拿掉
index c = 聯合索引 (c,a,b)
index cb = 聯合索引 (c,b,a)
index ca = 聯合索引 (c,a,b) 跟 index c 重複了
MySQL 中, 每一個單獨的 index, 其實都跟哪一個 key 構成聯合索引?
primary key
MySQL 中, 如果一支 index API, 有多個查詢條件, 並且每個查詢條件都可能不帶 (不帶即不查), 但表的資料量又非常大, 那該怎麼辦?
可評估業務需求用得最多的 query 來建立 2 個聯合索引, 剩下低頻的建立單獨的索引, 前端分別呼叫這兩個索引後, 在前端取交集
MySQL 中, 如果一張 table 中有 a 與 b 兩個單獨的索引, 假設 query 為 `where a = xx and b = yy, 那優化氣會先選擇哪個索引, 還是兩個都走?
- 只選 a, 然後用 b 過濾
- 只選 b, 然後用 a 過濾
- 選 a 和 b, 然後兩個單獨跑出來的結果取交集
MySQL 中, 觸發覆蓋索引的條件是?
當查詢的條件與返回的字段都能被一個非主鍵索引所覆蓋, 則觸發覆蓋索引
MySQL 中, 什麼是 ICP?
Index Condition Pushdown
以下的 MySQL example code 的意思是?
- Example
alter table T engine=InnoDB
- Answer
觸發 MYSQL 重建該表, 進行碎片化整理
以下的 MySQL example code, 與 images 的意思是?
- Example
select * from tuser where name like '张%' and age=10 and ismale=1;
- image1
- image2
- Answer
圖 1 為無索引下推 (index condition pushdown), 圖 2 為索引下推
索引下推中, 當索引中存在 query condition 的資料時, 會在索引 B+ 樹中直接比對, 若條件不符就不必再回表繼續比對了, 若條件相符, 而索引中又不存在 condition query 資料, 那才需要回表繼續比對
無索引下推, 不管索引中是否存在 query condition 需要的資料, 都會回表比對
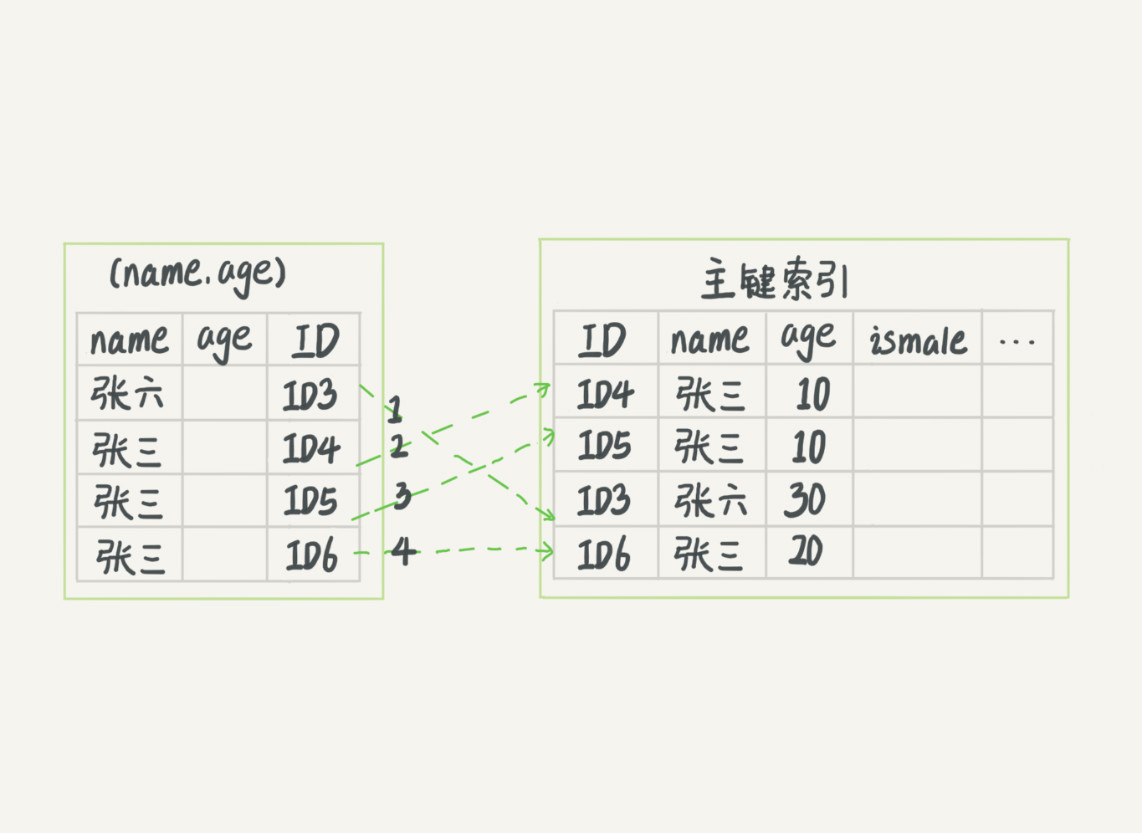
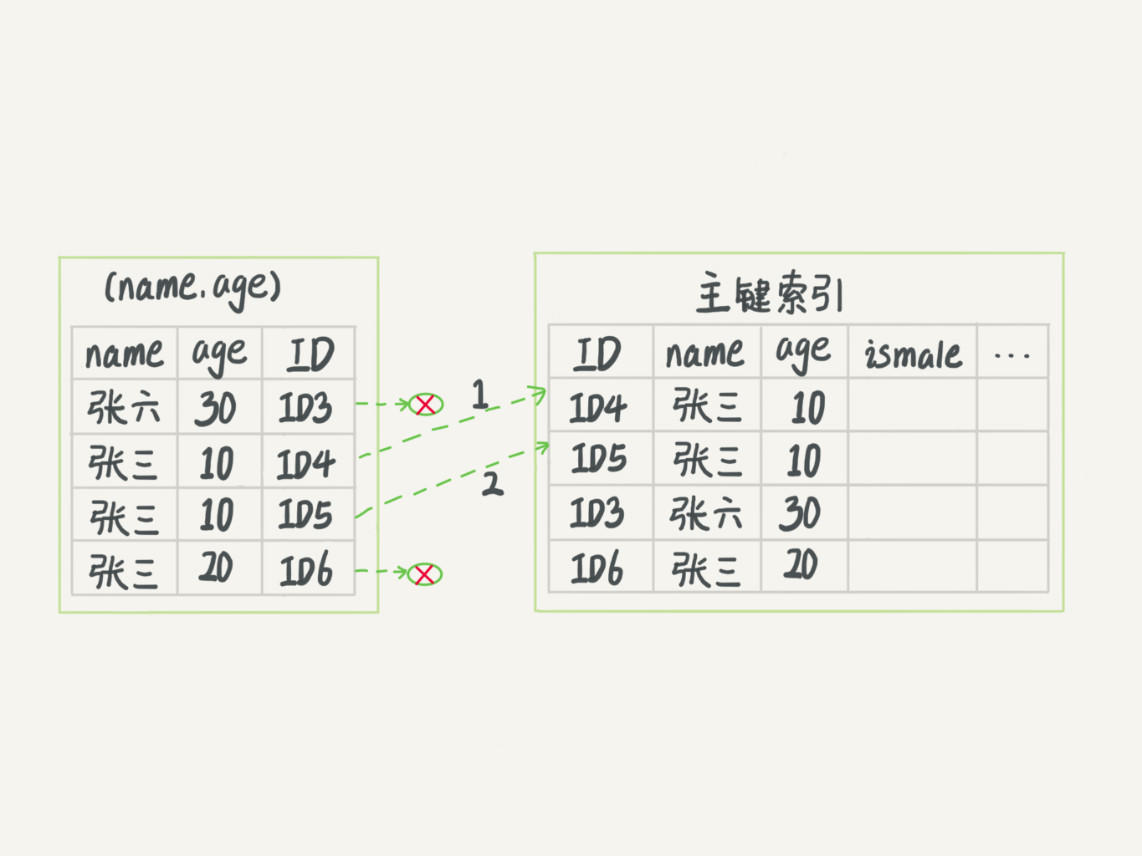
MySQL 中, 如果 a 跟 b 欄位都有各自的查詢需求, 那聯合索引該使用 (a,b), b, 還是 (b,a) a?
可以從空間角度來看, 看 a 跟 b 哪個大, 如果 b 大, 則選 (b,a), a, 因為這樣 b 只需出現一次, 反之則為 (a,b), b
MySQL 中, 在建立聯合索引時, 如何安排索引的順序?
如果可以通過調整索引的順序而減少索引的數量, 那這個順序優先考慮
MySQL 中, 何謂最左前綴原則?
當有一個聯合索引 (compound index), 假設為 (name, age), 那當 query 的 condition, name 為第一項是, 就可以使用這一個聯合索引, 因為索引中, 最左的索引是 name
MySQL 中, 何謂覆蓋索引 (covered index)?
當索引上已經含有 query 所要 select 的資訊, 那就不需回表, 直接 return
MySQL 中, innodb_log_file_size 的意思是?
redo log 的 circular file size, 若一個區塊寫滿就會 flush 到 disk 中, 所以設越大自然越久才需要寫回 disk, 若在 write loading 非常高的情境, 可設為 500M, 預設是 128M
MySQL 中, 當使用 innodb_flush_log_at_timeout 來加快 write 負荷很重的 DB 時, 利與弊?
代表多久將 redo log 寫到 disk 中, 設得越長, write 的速度越快, 但一旦 server 掛點, 遺失的資料也越多
MySQL 中, 當使用 innodb_flush_log_at_trx_commit 來加快 write 負荷很重的 DB 時, 利與弊?
預設是 1, 若設為 2 可大幅降低 insert 的時間, 但若 server 掛點, 因為資料寫入 disk 的頻率變低了, 所以也會遺失比較多的資料
MySQL 中, 當一個 table 中有 text 欄位, 且該欄位資料龐大, 建議怎麼做?
移到一個獨立的 table, 避免 full table scan 時掃到
下面的 image 中, 如果 SQL query 是 select ID from T where k between 3 and 5, 那會回表嗎? 為什麼?
- Image:
- Answer:
不會, 因為在 k index 這個 B+ 樹上, 已含有 ID, 所以直接給就行, 不需回表, 又稱為覆蓋索引
MySQL 中, 當我在 transaction 中使用 DDL, 會發生什麼事?
會自動 commit
以下的 MySQL example image 中, 如果我的語法是 select * from T where k between 3 and 5, 那共會搜尋 index 幾次, 回表幾次?
- Example
- Answer
搜尋索引三次, 回表兩次
找 k=3, 取得 id=300, 回表取 R3
找 k=5, 取得 id=500, 回表取 R4
找 k=6, 不符合條件, 循環終止

MySQL 中, 在 page 內如何定位行??
通過有序數組, 二分法
MySQL 中, 索引樹的葉子節點, 存什麼?
存著頁, 頁裏存行
MySQL 中, 最小的儲存單位是?
page
MySQL 中, 默認 page 大小為?
16 kb
MySQL 中, 默認 pointer 大小為?
6 bytes
MySQL 中, 若調整 page size, page 大跟小有什麼影響?
page 越大, 則可容納的 key 越多, 則載入內存與搜尋
MySQL 中, 為什麼 key 的大小會影響到 N 叉樹的 N?
索引 N 叉樹中, 非葉子節點的通常儲存 key 以及 pointer, pointer 固定為 6 bytes, 而 key 的大小不定, 假設為 10 bytes, 而一個 page 的默認大小為 16kb, 那該 page 就可以容納 1024 個 key, 則該 B+ 樹的 N 為 1024
MySQL 中, 若要調整 N 叉樹的 N, 有哪兩種方向?
- 調整 key 的大小
- 調整 page_size
MySQL 中, 刪除連線, 推薦使用什麼工具?
Percona pt-kill
MySQL 中, 建議將 innodb_undo_tablespaces 设置成 2, 或更大的值, 為什麼?
如果出現長事務導致回滾過大, 方便清理
MySQL 中, 如果要避免長事務, 可以監控哪個表?
information_schema.Innodb_trx
MySQL 中, SET MAX_EXECUTION_TIME 的意思以及用途是?
設定 SQL 語句最長的執行時間, 以確保不會有語句執行意外太長的時間
資料庫中, 有什麼場景不使用 auto increment primary key 的呢?
KV 場景, 像是 redis
MySQL 中, primary key 長度越小, 二級索引佔據的空間越小, 為什麼?
因為二級索引儲存著 primary key
MySQL 中, 使用有業務邏輯的 string 當作 primary key, 為何成本相對較高?
因為不保證有序插入, 可能會造成葉節點數據分裂
MySQL 中, auto increment 對於效能上有什麼幫助?
每次都固定 id + 1, 故不需要對 B+ 數進行插入動作, 只會用到追加, 不涉及挪動其他紀錄, 也不會觸發葉子節點分裂
MySQL 中, 何謂頁合併?
當相鄰的兩個數據頁有資料被刪除, 造成利用率很低, 這時會合併兩個數據頁, 又稱為頁合併
MySQL 中, 何謂頁分裂?
當前的數據頁已滿, 但又有塞東西進來的需求, 所以必須要將部分的數據移動到新的數據頁
下圖中, 如果我要插入 ID 400, 但位於 R5 所在的數據頁已經滿了, 那會發生什麼事??
- Example
- Answer
申請一個新的數據頁, 挪動部分數據過去, 又稱為頁分裂
MySQL 中, 非 primary key index 又稱為?
secondary index
MySQL 中, primary key index 又稱為??
clustered index
以下的 MySQL example image 的意思是?
Example
Answer
兩顆 B+樹, primary key (ID) 這棵樹, 一個 ID 對應到整個 row, k index 這棵樹, k 值對應到相對應的 ID primary key
資料結構中, N 叉數, 假設 N 為 1200, 那樹高三層, 會有幾筆資料?
N 的三次方
資料結構中, 二元樹的搜索效率最好, 但為何資料庫卻不採用二元樹這種資料結構?
因為索引不只在內存, 更在硬碟中, 而每棵樹的查找都相當於訪問一個 block, 換言之, 資料越多, 樹越高, 訪問的 block 越多, 這個查詢效率並不友善 (訪問太多硬碟 block)
以下的數據結構, query 與 insert 的 complexity 是多少?
- Example
- Answer
O(log(N))

以下的數據結構, 適合怎樣的情境?
- Example
- Answer
有序數組較適合靜態引擎, 即不太會更動的資料庫

以下的數據結構, 劣勢在於?
- Example
- Answer
為了維持有序, 所以 insert 會增加額外的 cost 使其維持有序, insert 資料效率差
以下的數據結構, 優勢在於?
- Example
- Answer
查詢, 因為有序, 可使用二分法, 區間查詢效率也很好
以下的 MySQL example picture, 是怎樣的數據結構?
- Example
- Answer
有序數組
MySQL hash 索引只適用於什麼樣的查詢?
等值查詢, 比如 Memcached 或 NoSQL, 因為其 hash value 並無順序性
以下的 hash data structure 索引在區間查詢非常慢, 原因為何?
- Example
- Answer
因為 key 的 hash 並無順序性, 所以若要查找區間, 等於全表掃描

以下的 data structure, hash 的值是有順序性的嗎?
- Example
- Answer
沒有
以下的 picture 的意思是?
- Example
- Answer
Hash 索引, 將 key 透過 hash method 得到一個 hash 值, 將 value 放到一個數組中, 而前面得到的 hash 值, 就是這個 value 在數組中的 key, 如果 hash 值重複, 則對應的 value 會構成一個 linked list, 所以精妙的 hash method 會讓重複機率降低
MySQL 中, 如果我要使用連續的 transaction, 但我想省略 begin 來節省一次的連線, 那可以怎麼做?
使用 commit work and chain 語法
以下的 MySQL example code 的意思是?
- Example
select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60
- Answer
查詢超過 60 秒的長事務
以下的 MySQL example code 的意思是?
- Example
set autocommit=0
- Answer
代表關閉自動 transaction 提交, 也就是說你執行一個最基本的 select, transaction 就開始了, 而且不會自動提交, 這就導致意外的長事務
MySQL 中, 長事務跟 undo log 有什麼關係?
transaction 越長, 所需要保留的 undo log 越多, 佔據的空間也越大
以下的 MySQL illustration 中, undo log 什麼時候會被刪除?
- Example
- Answer
當這個 undo log 不再被需要的時候, 例如沒有比這個 undo log 更早的 transaction read view 存在

以下的 MySQL illustration 中, read view 的意思是?
- Example
- Answer
代表不同時刻啟動的 transaction, 在 repeatable isolation 中, 不同的 transaction 會有不同的 read view
以下的 MySQL illustration 的意思是?
- Example
- Answer
在每一次的 update, 同時都會紀錄下 undo log, 供不同的 read view 使用
MySQL inno DB 中, 當提交一筆 update 時, 共會紀錄哪三種 log?
redo log, undo log, binlog
MySQL 中, 一天備份一次跟一週備份一次, 差別在哪?
恢復時間的長短差別, 使用備份來復原的速度比使用 binlog 復原的速度還快
MySQL 中, binlog 的 row 模式, 是用什麼方式紀錄 log?
紀錄 row 的內容, 記兩條, 更新前和更新後
MySQL 中, binlog 的 statement 模式, 是用什麼方式紀錄 log?
紀錄 sql 語句
MySQL 中, binlog 又分為哪兩種模式?
statement
row
MySQL 中, redo log 是物理性, binlog 是邏輯性, 何謂物理性跟邏輯性?
redo log 紀錄硬碟上數據的物理變化
binlog 紀錄當時所執行的 sql 語法
MySQL 中, innodb_flush_log_at_trx_commit=1 這個參數的意思是?
讓每次 redo log 都會持久化到 disk
MySQL 中, 又不是常常會需要復原資料, 為何一定要使用二階段提交來確保 redo log 與 binlog 資料一致?
因為當需要 scale 來增加系統 read 的 capacity 時, 便會用到 binlog 來實現增加新的 read database, 若資料不一致便無法實現這樣的操作
MySQL 中, 假設不使用二階段提交, 先寫 binlog, 再寫 redo log, 假設 binlog 寫完, 但 redo log 還沒寫完時就 crash 了, 會發生什麼事?
由於 redo log 還沒寫, 也就是該 transaction 無效, 但 binlog 已寫了, 造成跟原庫的資料不一致
MySQL 中, 假設不使用二階段提交, 先寫 redo log, 再寫 binlog, 假設 redo log 寫完, 但 binlog 還沒寫完時就 crash 了, 會發生什麼事?
server 重啟後, 因為 redo log 的 crash save 能力, 資料並沒有丟失, 但是如果使用 binlog 復原資料時, 便會少了那筆紀錄, 造成兩邊資料不一致
MySQL 中, redo log 與 binlog 的二階段提交主要的作用是?
讓兩份 log 的邏輯一致
MySQL 中, binlog 跟 redo log 分別的主要作用是?
- redo log: crash save (innoDB 層面)
- binlog: 恢復某個時間點的數據
MySQL 中, redo log 與 binlog 的寫入流程是?

- 執行器先找引擎取 ID=2 這一行。 ID 是主鍵,引擎直接用樹搜索找到這一行。如果 ID=2 這一行所在的數據頁本來就在內存中,就直接返回給執行器;否則,需要先從磁盤讀入內存,然後再返回。
- 執行器拿到引擎給的行數據,把這個值加上 1,比如原來是 N,現在就是 N+1,得到新的一行數據,再調用引擎接口寫入這行新數據。
- 引擎將這行新數據更新到內存中,同時將這個更新操作記錄到 redo log 裡面,此時 redo log 處於 prepare 狀態。然後告知執行器執行完成了,隨時可以提交事務。
- 執行器生成這個操作的 binlog,並把 binlog 寫入磁盤。
- 執行器調用引擎的提交事務接口,引擎把剛剛寫入的 redo log 改成提交(commit)狀態,更新完成。
重點: binlog 與 redo log 會有共同的 XID, 當 crash 重啟後, 如果有 prepare 又有 commit 的 redo log, 就直接提交, 如果有 prepare 但沒有 commit 的 redo log, 就拿著 XID 去尋找是否有該 binlog, 有則提交, 無則 rollback
MySQL 中, redo log 和 binlog, 哪個是循環寫 哪個是追加寫?
redo log 是循環寫, binlog 是追加寫
MySQL 中, redo log 和 binlog, 哪個是物理性, 哪個是邏輯性?
redo log 是物理性, binlog 是邏輯性
MySQL redo log 中, 先寫日誌, 具體來說是寫到哪? 跟實際更新硬碟的差別在於?
也是寫到磁盤中, 但如果跟實際更新硬碟相比, 一個是順序 I/O, 一個是隨機 I/O, 差別在於隨機 I/O 有一個尋址的過程, cost 較高
MySQL 中, 任何 Storage Engine 都可使用, 屬於 Server 層的 Log 是哪一個?
binlog
MySQL 中, redo log 是屬於哪種儲存引擎專屬的?
InnoDB
MySQL 整體上來看, 其實就分為哪兩層?
server, storage
以下的 MySQL redo log picture 中, check point 代表的意思是?
- Example
- Answer
當前要擦除的位置

以下的 MySQL redo log picture 中, write pos 代表的意思是?
- Example
- Answer
目前從此處開始寫入
以下的 MySQL redo log picture 中, 綠色部分代表的意思是?
- Example
- Answer
可以寫入的空白地方
MySQL 的 redo log 主要解決了什麼問題?
減少 I/O 成本
如果每一次的更新操作都需要寫進磁盤,然後磁盤也要找到對應的那條記錄,然後再更新,整個過程 IO 成本、查找成本都很高
MySQL 的 redo log 可以讓 MySQL server 就算臨時異常重啟, 之前提交的記錄也不會丟失, 這種能力稱為?
crash-save
關鍵點就是先寫日誌,再寫磁盤,也就是先寫粉板,等不忙的時候再寫賬本。
以下的 MySQL picture 是哪一種 log?
- Example
- Answer
redo log
MySQL 中, redo log 的大小是固定的, 對嗎?
對的
MySQL 中, WAL 的全稱是?
Write-Ahead Logging, 先寫日誌, 再寫磁盤
MySQL 8.0 還能使用查詢緩存嗎?
不行
MySQL 查詢緩存, 什麼是 key, 什麼是 value?
查詢語句為 key, 查詢結果為 value
MySQL 中, 預設的 client 端與 server 端的連線是多久?
8 小時
以下的 MySQL example picture 的意思是?
- Example
- Answer
MySQL 的架構圖

MySQL 的 timestamp column, 從資料庫看, 顯示的時間是哪一個時區?
預設為機器當下的時區, 因為 MySQL timezone variable 預設去抓 system timezone
MySQL 的 timestamp column 會隨著系統的時區調整而變動, 為什麼?
MySQL timestamp 會在底層儲存 UTC 的時間, 而從資料庫中看到的時間是根據當下機器的時區轉化過的, 所以 timestamp 欄位會隨著機器的時區不同而顯示該時區的時間, 所以調整 MySQL 的 timezone 是不會影響到資料準確度的
以下的 MySQL example code 的意思是?
- Example
SELECT
`branch_managers`.`account`,
`branch_managers`.`created_at`,
`shops`.`name`
FROM
`branch_managers`
INNER JOIN `shops` ON `branch_managers`.`shop_id` = `shops`.`id`
WHERE
AND `branch_managers`.`id` in(
SELECT
`id` FROM ((
SELECT
`id` FROM `branch_managers`
WHERE
match(account) against ('4k' IN boolean mode))
UNION (
SELECT
`branch_managers`.`id` FROM `branch_managers`
INNER JOIN `shops` ON `branch_managers`.`shop_id` = `shops`.`id`
WHERE
match(name) against ('4k' IN boolean mode))) AS `matches`) - Answer
無法直接使用 or where match 這樣子的 full text search 在多個表格, 因此統一取得 id, 在使用 where in 取得最後需要的資料
使用 union 來取得兩個 select query 取得的不重複 id
使用 derived table, 避免 where in 與 union query 之間的 dependency
以下的 MySQL example image 的意思是?
- Example
- Answer
SELECT 時加上 exclusive lock, 雖然 weight column 並沒有 index, 但 MySQL 為了做到 RR Isolation, 會把整張 table lock 住

使用 MySQL 的 range lock 時, 要特別注意什麼事?
range column 一定要有 index, 否則 MySQL 為了維持 RR Isolation, 會 lock 整張 table
MySQL 的 range lock 如果 range column 並沒有 index, 那會有什麼行為?
MySQL 為了維持 RR Isolation, 會 lock 整張 table
以下的 MySQL example image 的意思是?
- Example
- Answer
SELECT 時加上 exclusive lock, 所以所有 height >= 170 這個 range 的 row 都被鎖住了

MySQL 的 repeatable isolation 中, 如何避免 lost update?
使用 Atomic operation, 像是 credit = credit - 1, 但如果要避免負數, 還是要使用 lock
MySQL 的 repeatable isolation, 實作的 snapshot 只對什麼語法有效?
只對 DQL, 像是 select 有效, 對 DML, 像是 insert, update, delete 都無效
MySQL 的 repeatable isolation 是如何實作 snapshot 的?
會在 transaction 一開始進行一次 select, 並記錄下時間, 之後在此 transaction 中只可看到此時間之前的 committed row, 已經 transaction 自己本身作出的改變, 但這個規則只對 DQL (Data Query Language)有效, 對 DML (Data Manipulation Language) 無效
以下的 MySQL transaction illustration image 的意思是?
- Example
- Answer
MySQL 的 repeatable read 只可避免 phantom read, 但無法避免 phantom update, insert, delete 等其他操作
在 transaction 中, update 的作用範圍依然是所有已經 commit 的 row, 而在 transaction 中, 可以看到自己 update 的 row, 因此 update 造成了 write skew, 而 select 產生 phantom read

資料庫中, Serializable Isolation 中的 Serializable Snapshot Isolation, 是如何實作?
不特別對 transaction 做互相 block, 而是在最後 commit 的時候再做確認, 效能最佳, 但 2008 年才提出, 因此大部分資料庫都還沒有採用
大部分的資料庫都採用哪種方式實作 Serializable Isolation?
Two-phase Lock
資料庫中, Serializable Isolation 中的 Two-phase Lock, 是如何實作?
使用 Shared Lock 以及 Exclusive Lock 配合, 讓每一筆資料在同一時間最多都只會有一個 Transaction 對它進行讀寫, 還要搭配 Range Lock 避免 Phantom 現象, 大部分資料庫都採用這種實作
資料庫中, Serializable Isolation 中的 Serial Order, 是如何實作?
真正照順序進行資料讀寫, 避免所有同時執行更新可能造成的衝突, 犧牲 concurrency, 效能差, 適合讀寫較快速的 In-Memory 資料庫, 如 redis
資料庫中, Serializable Isolation 有哪三種實作方式?
Serial Order
Two-phase Lock
Serializable Snapshot Isolation
資料庫中, 何謂 Serializable Isolation?
可以保證在多個 Transaction 同時對資料庫進行讀寫所得到的結果, 會跟一次只讓一個 transaction 照順序 (serially) 進行讀寫所得到的結果完全一致, 最嚴格的 Isolation level, 但效能較差
資料庫中, 何謂 Repeatable Read Isolation?
只要可以避免 Dirty Read 和 Non-repeatable Read, 就可以稱為 Repeatable Read Isolation, 依照實作方法不同, 有些資料庫的 Repeatable Read 可以避免 Lost Update 以及 Phantom
資料庫中, 何謂 Read Committed Isolation?
只允許讀取已經被 Commit 的資料, 可以避免 dirty read
資料庫中, 何謂 Read Uncommitted Isolation?
允許讀取尚未被 commit 的資料
資料庫中, Isolation 又分為哪四種?
Read Uncommitted Isolation
Read Committed Isolation
Repeatable Read Isolation
Serializable Isolation
資料庫中, 以下的情況又稱為?
- Example:
- Answer:
Write Skew
只有 Serializable Isolation 可以避免

資料庫中, 以下的情況又稱為?
- Example:
- Answer:
Phantom Read, Serializable Isolation 可以避免這個現象, Repeatable Read Isolation 視乎各個資料的實作, PostgreSQL 可以完全避免, MySQL InnoDB 只能避免 Phantom Read, 但無法避免 UPDATE, DELETE 等 DML 寫入的操作
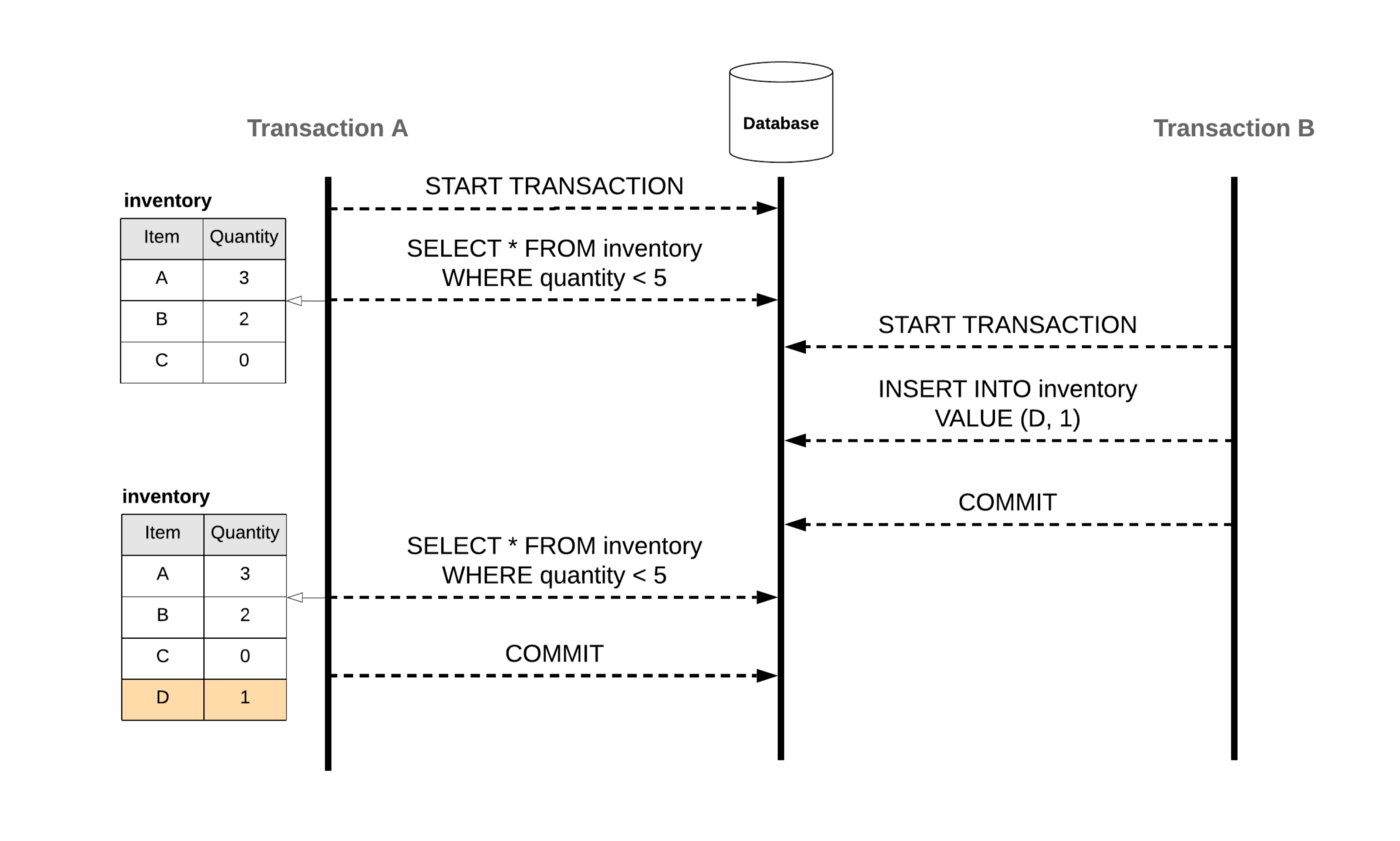
資料庫中, 以下的情況又稱為?
- Example:
- Answer:
Lost Update, Serializable Isolation 可以避免這個情況, Repeatable Read Isolation 看每個資料庫的實作不同有不同的行為, MySQL 無法避免 Lost Update, PostgreSQL 可以

資料庫中, 以下的情況又稱為?
- Example:
- Answer:
Read Skew (Non-repeatable Read), Repeatable Read 或更高的 Isolation 可避免這個情況

資料庫中, 以下的情況又稱為?
- Example:
- Answer:
Dirty Read, Read Committed 或更高的 Isolation 可避免 dirty read

以下的 MySQL example code 中, range lock 範圍內的資料 InnoDB 可以讀嗎?可以寫嗎?
- Example:
SELECT * FROM student WHERE height >= 170 FOR UPDATE;
- Answer:
如果 Isolation level 是 Serializable 的話, 不可讀不可寫
如果 Isolation level 是 Repeatable Read 的話, 可讀不可寫, 因為 InnoDB 的 RR Isolation 實作是採用 Snapshot Isolation, 讀取時都是讀取 Snapshot 內的資料
以下的 MySQL example code 中, 哪些資料會被鎖住? 會加上什麼鎖?
- Example:
SELECT * FROM student WHERE height >= 170 FOR UPDATE;
- Answer:
height >= 170 的資料
exclusive lock
MySQL 中, 如果一筆資料只被一個 transaction 加上 shared lock, 該 transaction 可以將此 shared lock 升級成 exclusive lock 嗎?
可以
MySQL 中, 當一筆資料被 1 個或 1 個以上的 transaction 加上 shared lock, 該筆資料可以被加上 exlusive lock 嗎?
不行
MySQL 中, 同一筆資料可以同時被多個 transaction 加上 shared lock 嗎?
可以
MySQL 中, 當一個 transaction 取得某資料的 shared lock, 在該 lock 釋放之前, 其他 transaction 可以對此資料進行寫入嗎?
不行
MySQL 中, 當一個 transaction 取得某資料的 shared lock, 在該 lock 釋放之前, 其他 transaction 可以對此資料進行讀取嗎?
可以
MySQL 中, 當一個 transaction 取得某資料的 exclusive lock, 在該 lock 釋放之前, 其他 transaction 可以對此資料進行讀取嗎?
不行
MySQL 中, 當一個 transaction 取得某資料的 exclusive lock, 在該 lock 釋放之前, 其他 transaction 可以對此資料進行寫入嗎?
不行
MySQL 中, 何謂 shared lock?
當一個 transaction 取得資料的 shared lock 之後, 其他 transaction 可以 讀取 資料, 但無法 寫入 資料
MySQL 中, 何謂 Exclusive lock?
當一個 transaction 取得資料的 exclusive lock 之後, 其他 transaction 無法對此資料做 讀取 以及 寫入
例如: select a from b for update
以下的 MySQL example code 的意思是?
- Example:
mysqlimport –user='marie_dyer' --password='sevenangels' \
--replace --low-priority --ignore-lines='1' \
--fields-enclosed-by='"' --fields-terminated-by='|' --fields-escaped-by='\\' \
--lines-terminated-by=']\r\n' \
--columns='prospect_name, prospect_email, prospect_country' \
birdwatchers '/tmp/birdwatcher_prospects_import.csv' - Answer:
基本上語法跟 LOAD DATA 是一樣的, 差別在於檔名若有-要改成_, 以免 MySQL 判定為刪減符號
以下為 FIELDS 子句意思:
TERMINATED BY: 表示 | 為 field 跟 field 之間的間隔
ENCLOSED BY: 表示每一個 field 的內容都會由 " 包住
ESCAPE BY: 標示跳脫用字元, 不過預設就是 \, 因此這個可省略
LINES 子句:
STRINGS BY: 表示 [ 開頭算一行的開始
TERMINATED BY: 表示 ]\r\n 為一行的結束, 正常 Linux 只需 \n 即可, 但考量到 Windows 環境, 因此多加了 \r
以下的 MySQL example code 的意思是?
- Example:
( SELECT 'scientific name','common name','family name' )
UNION
( SELECT birds.scientific_name,
IFNULL(common_name, ''),
bird_families.scientific_name
FROM rookery.birds
JOIN rookery.bird_families USING(family_id)
JOIN rookery.bird_orders USING(order_id)
WHERE bird_orders.scientific_name = 'Charadriiformes'
ORDER BY common_name
INTO OUTFILE '/tmp/birds-list.csv'
FIELDS ENCLOSED BY '"' TERMINATED BY '|' ESCAPED BY '\\'
LINES TERMINATED BY '\n'); - Answer:
使用 SELECT INTO OUTFILE 將資料匯出, 子句部分語法跟 LOAD DATA 完全一樣
需使用 IFNULL 將 null 轉為空字串, 因為 INTO OUTFILE 預設會將 null 轉為 n
以下為 FIELDS 子句意思:
TERMINATED BY: 表示 | 為 field 跟 field 之間的間隔
ENCLOSED BY: 表示每一個 field 的內容都會由 " 包住
ESCAPE BY: 標示跳脫用字元, 不過預設就是 \, 因此這個可省略
LINES 子句:
STRINGS BY: 表示 [ 開頭算一行的開始
TERMINATED BY: 表示 ]\r\n 為一行的結束, 正常 Linux 只需 \n 即可, 但考量到 Windows 環境, 因此多加了 \r
MySQL 中, 如果目標 server 並不支援 LOAD DATA INFILE, 那有什麼解法?
找一台有支援的使用 LOAD DATA 匯入後, 在匯出 mysqldump file, 再到目標 server 上復原 from mysqldump file
MySQL 中, 如果遠端登入使用 LOAD DATA 匯入檔案操作, 在 server 端跟 client 端都要開啟哪一個選項?
local-infile=1
以下的 MySQL example code 的意思是?
## csv 格式範例: |
- Answer:
從 csv 檔讀取資料並匯入 database.table
FIELD TERMINATED BY: field 跟 field 之間由 , 區隔開來
OPTIONALLY: 有則處理, 沒有則不執行
ENCLOSED BY: 使用 ENCLOSED BY '"', 當 " (doube quote) 有出現時, 會將兩個 " (double quote) 之間的內容視為一個 column 的內容, 若沒出現則不使用, 為了應付某些 filed 的內容其實是 text, 會用 " (double quote) 包住, 但內容有許多 ,(comma)
IGNORE 1 LINES: 表示忽略第一行, 因為第一行是 field name, 我們並不會用到
@niente: 因為 csv 檔中某些欄位的資料我們並不需要, 因此在建立 table 時只需要建立我們需要的 column, 在匯入時, 將沒用到的 fieldd 按照 csv 上的順序標示為 @niente (只要是變數就行, 名稱不重要), 這樣就不會將資料匯入啦
@family, SET family: 可以在 LOAD DATA 的過程中, 針對 csv 上特定的 column 做處理, 匯入完成後就已經會是處理好的
以下的 MySQL example code 的意思是?
- Example:
LOAD DATA INFILE '/tmp/Clements-Checklist-6.9-final.csv'
INTO TABLE rookery.clements_list_import
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
IGNORE 1 LINES;
(id, change_type, @niente, @niente,
scientific_name, english_name,
@niente, bird_order, @family, @niente,
@niente, @niente, @niente, @niente,
@niente, @niente, @niente, @niente);
SET family = SUBSTRING(@family, 1, LOCATE(' (', @family) ); - Answer:
從 csv 檔讀取資料並匯入 database.table
FIELD TERMINATED BY: field 跟 field 之間由,區隔開來
OPTIONALLY: 有則處理, 沒有則不執行
ENCLOSED BY: 使用ENCLOSED BY '"', 當" (doube quote)有出現時, 會將兩個" (double quote)之間的內容視為一個 column 的內容, 若沒出現則不使用, 為了應付某些 filed 的內容其實是 text, 會用" (double quote)包住, 但內容有許多,(comma)
IGNORE 1 LINES: 表示忽略第一行, 因為第一行是 field name, 我們並不會用到
@niente: 因為 csv 檔中某些欄位的資料我們並不需要, 因此在建立 table 時只需要建立我們需要的 column, 在匯入時, 將沒用到的 fieldd 按照 csv 上的順序標示為@niente(只要是變數就行, 名稱不重要), 這樣就不會將資料匯入啦
@family, SET family: 可以在 LOAD DATA 的過程中, 針對 csv 上特定的 column 做處理, 匯入完成後就已經會是處理好的
使用 MySQL 時, 當遇到 warning 時, 如何顯示 warning?
SHOW WARNINGS; |
以下的 MySQL example code 的意思是?
- Example:
LOAD DATA INFILE '/tmp/Clements-Checklist-6.9-final.csv'
INTO TABLE rookery.clements_list_import
FIELDS TERMINATED BY ','; - Answer:
讀取 csv 檔並 insert 到指定 database.table, 以,為 filed 跟 field 之間的分隔點
MySQL 中, 當我在 CREATE TABLE 時, 如果 column name 可能是 MySQL 的保留字, 那我要用什麼符號將 column name 包住?
` ` (backquote) 符號
MySQL 中, 若要執行 LOCK TABLE, 需先把哪一個選項關閉, 以避免 LOCK TABLE 與 TRANSACTION 相互影響?
AUTOCOMMIT
MySQL 中, 目前 innoDB 是如何處理死鎖的?
將持有最少行級排他鎖的 transaction rollback
以下的 MySQL example code 中, 當兩個 transaction 同時執行時, 很可能會產生哪一種問題?
- Example:
事務1
START TRANSACTION;
UPDATE StockPrice SET close = 45.50 WHERE stock_id = 4 and date = '2002-05-01';
UPDATE StockPrice SET close = 19.80 WHERE stock_id = 3 and date = '2002-05-02';
COMMIT;
事務2
START TRANSACTION;
UPDATE StockPrice SET high = 20.12 WHERE stock_id = 3 and date = '2002-05-02';
UPDATE StockPrice SET high = 47.20 WHERE stock_id = 4 and date = '2002-05-01';
COMMIT; - Answer:
死鎖, 即事務 1, 2 同時執行了第一條 update, 這時第一句 update 作用的 row 已被鎖住, 而當事務 1, 2 嘗試執行第二句 update 時, 發現該 row 已被鎖住, 彼此都在等對方釋放鎖, 故又稱為死鎖
以下的 MySQL 形容, 屬於 ACID 中的哪一種?
- Example:
一旦事務提交,則其所做的修改就會永久保存到數據庫中。此時即使系統崩潰,修改的數據也不會丟失。持久性是個有點模糊的概念,因為實際上持久性也分很多不同的級別。有些持久性策略能夠提供非常強的安全保障,而有些則未必。而且不可能有能做到100%的持久性保證的策略(如果數據庫本身就能做到真正的持久性,那麼備份又怎麼能增加持久性呢?) - Answer:
durability (持久性)
以下的 MySQL 形容, 屬於 ACID 中的哪一種?
- Example:
通常來說,一個事務所做的修改在最終提交以前,對其他事務是不可見的 - Answer:
isolation (隔離性)
以下的 MySQL 形容, 屬於 ACID 中的哪一種?
- Example:
數據庫總是從一個一致性的狀態轉換到另外一個一致性的狀態。在前面的例子中,一致性確保了,即使在執行第三、四條語句之間時系統崩潰,支票賬戶中也不會損失200美元,因為事務最終沒有提交,所以事務中所做的修改也不會保存到數據庫中。 - Answer:
consistency (一致性)
以下的 MySQL 形容, 屬於 ACID 中的哪一種?
- Example:
一個事務必須被視為一個不可分割的最小工作單元,整個事務中的所有操作要麼全部提交成功,要麼全部失敗回滾,對於一個事務來說,不可能只執行其中的一部分操作 - Answer:
atomicity (原子性)
MySQL 中的 ACID, 分別是哪四種特性?
atomicity (原子性)
consistency (一致性)
isolation (隔離性)
durability (持久性)
以下的 MySQL Image 是??
- Example:
- Answer:
MySQL 邏輯架構圖
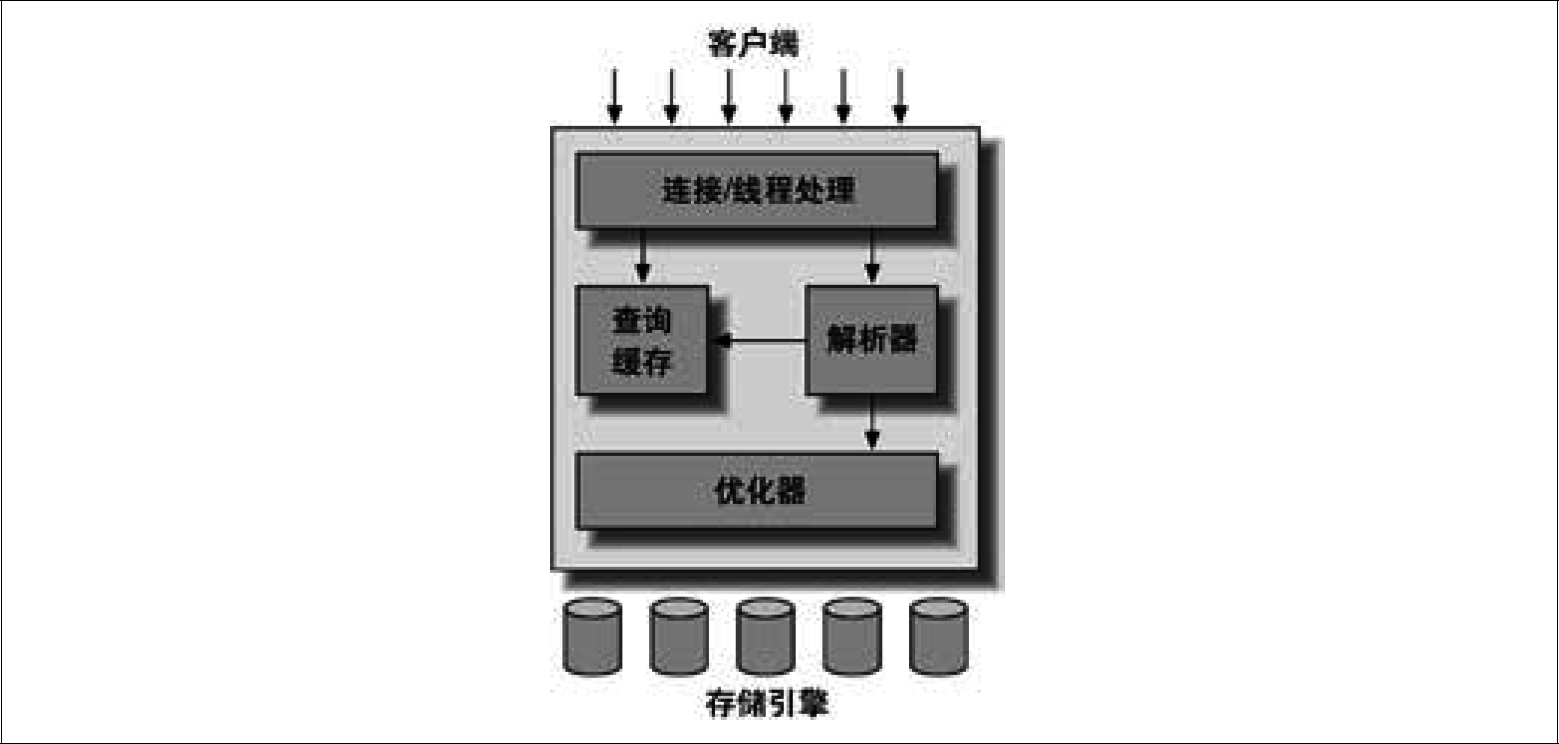
以下的 MySQL example code 的意思是?
- Example:
mysqlbinlog --database=rookery --start-position="1284889" --to-last-log \
binaryLogAbsoluteLocation |
mysql --user=userName --password - Answer:
從 binary log 備份中, 從 position 1284889 開始復原, 直到最後一個 log, 復原範圍有包含 1284889
以下的 MySQL example code 的意思是?
- Example:
mysqlbinlog --database=databaseName--stop-position="1258707" \
binaryLogAbsoluteLocation |
mysql --user=userName --password - Answer:
從 binary log 備份中, 復原到 position 1258707, 復原範圍不包含 1258707
以下的 MySQL example code 的意思是?
- Example:
# at 1258707
#140916 13:10:24 server id 1 end_log_pos 1258778
Query thread_id=382 exec_time=0 error_code=0
SET TIMESTAMP=1410887424/*!*/;
SET @@session.sql_mode=0/*!*/;
BEGIN
/*!*/;
# at 1258778
#140916 13:10:24 server id 1 end_log_pos 1258900
Query thread_id=382 exec_time=0 error_code=0
use `rookery`/*!*/;
SET TIMESTAMP=1410887424/*!*/;
DELETE FROM birds_simple WHERE common_name LIKE '%Blue%'
/*!*/;
# at 1258900
#140916 13:10:24 server id 1 end_log_pos 1258927 Xid = 45248
COMMIT/*!*/; - Answer:
binary log 中的一次 transaction 的紀錄, 1258707 為起點, 1258900 為終點, 1258927 為下一個起點
以下的 MySQL example code 的意思是?
- Example:
mysqlbinlog --database=databaseName \
/binaryLogAbsoluteLocation > whateverNameYouLike.txt - Answer:
將 binary log 匯出成 txt 檔, 方便手動尋找 position
以下的 MySQL example code 的意思是?
- Example:
SHOW VARIABLES WHERE Variable_Name LIKE 'datadir';
- Answer:
取得實際檔案存放位置
以下的 MySQL example code 的意思是?
- Example:
SHOW MASTER STATUS;
- Answer:
顯示當前的 binary log
Binlog_Do_DB: 指定哪些資料庫才要記錄到 binary log
Binlog_Ignore_DB: 指定哪些資料庫不要記錄到 binary log
Executed_Gtid_Set: 已經執行的 transaction 編號
MySQL 中, 何謂 DDL?
Data Definition Language, 例如 CREATE, DROP, ALTER
以下的 MySQL example code 的意思是?
- Example:
SHOW BINARY LOGS
- Answer:
顯示 binary log 是否有啟動
若有則顯示 log
若無則返回錯誤ERROR 1381 (HY000): You are not using binary logging
以下的 MySQL example code 的意思是?
- Example:
log-bin
binlog-ignore-db=mysql - Answer:
啟動 binary log 功能
不 log mysql 這個 table, 安全考量
MySQL 中, 如果我想要從一個 dump file 中只復原一部分的 table, 該怎麼做?
修改 dump file, 只留下開頭, 結尾變數, 以及需要的 table 段落
或是修改 create database, 改成一個臨時的 database name, 匯出後在從該臨時 database 中取出資料, 完成後再刪掉該 temporary database
或是賦予一個臨時使用者該 table 的權限, 讓這個使用者去執行 restore
以下的 MySQL example code 的意思是?
- Example:
mysqldump --user=admin_backup --password --lock-tables \
--databases rookery --tables birds > birds-humans.sql
mysqldump --user=admin_backup --password --lock-tables \
--databases birdwatchers --tables humans >> birds-humans.sql - Answer:
備份兩個資料庫的不同資料表, 但只產生一個 dump file
以下的 shell script 的意思是?
- Example:
#!/bin/sh
my_user='admin_back'
my_pwd='my_silly_password'
db1='rookery'
db2='birdwatchers'
date_today=$(date +%Y-%m-%d)
backup_dir='/data/backup/'
dump_file=$db1-$db2-$date_today'.sql'
/usr/bin/mysqldump --user=$my_usr --password=$my_pwd --lock-tables \
--databases $db1 $db2 > $backup_dir$dump_file
exit - Answer:
備份 MySQL Database 的 script
以下的 MySQL example code 的意思是?
- Example:
LOCK TABLES `bird_families` WRITE;
/*!40000 ALTER TABLE `bird_families` DISABLE KEYS */;
INSERT INTO `bird_families` VALUES
...
/*!40000 ALTER TABLE `bird_families` ENABLE KEYS */;
UNLOCK TABLES; - Answer:
通常還原資料, 在執行 INSERT 敘述時, 會先 DISABLE KEYS, 等到 INSERT 都完成後, 再 ENABLE KEYS, 這樣的效率會比 INSERT 時一筆筆的 INSERT INDEX 來得好
MySQL dump 復原資料時, 預設會覆蓋掉原本存在的資料嗎?
會哦, 因為會先 drop 現存的同名 table, 再 insert
以下的 MySQL example code 的意思是?
- Example:
mysqldump --user=specifiedUserAndHostName \
--password --lock-all-tables
--all-databases > /preferredLocationAndFileName.sql - Answer:
–user: 要求 mysqlsump 使用admin_backup這個帳號與 MySQL Server 互動
–password: 指定使用帳號的密碼
–lock-all-tables: 在開始備份前, 先把所有資料表鎖定
–all-databases: 指定匯出所有資料庫
以下位於 dump 檔的 MySQL example code 的意思是?
- Example:
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
- Answer:
*!40101: 當 MySQL 版本在 4.01.01 以上時, 該行指令才會執行
設定一個變數 @OLD_CHARACTER_SET_CLIENT, 並將目前的通用變數CHARACTER_SET_CLIENT儲存起來
以下的 MySQL example code 的意思是?
- Example:
GRANT 'roleName' TO 'userName'@'hostName';
- Answer:
賦予使用者 Role 權限
以下的 MySQL example code 的意思是?
- Example:
CREATE ROLE 'roleName';
- Answer:
建立 Role, 可賦予 Role 權限, 在賦予使用者 Role
以下的 MySQL example code 的意思是?
- Example:
SET ROLE 'admin_import_role';
LOAD DATA INFILE
...
SET ROLE NONE; - Answer:
當該使用者有被賦予該 Role 時, 可切換該 Role
執行完權限後, 登出 Role
以下的 MySQL example code 的意思是?
- Example:
RENAME USER 'lena_stankoska'@'lena_stankoska_home'
TO 'lena'@'stankoskahouse.com'; - Answer:
重新命名使用者帳號
以下的 MySQL example code 的意思是?
- Example:
SHOW PROCESSLIST;
- Answer:
當我們刪除一個使用者後, 如果該使用者在當下仍與 Server 處於一個連線狀態中, 那該使用者依然可以對資料庫進行操作, 這時可以透過 SHOW PROCESSLIST 列出連線, 並使用kill processId刪除該連線

MySQL 中, 當我刪除一個使用者後, 如果該使用者在當下仍跟 Server 處於連線狀態, 該使用者還能操作資料庫嗎?
可以
以下的 MySQL example code 的意思是?
- Example:
REVOKE ALL PRIVILEGES
ON rookery.*
FROM 'michael_stone'@'localhost' - Answer:
使用 REVOKE 語法, 從'michael_stone@localhost'user 身上收回 rookery 資料庫的所有的權限
以下的 MySQL example code 的意思是?
- Example:
GRANT ALL PRIVILEGES ON rookery.*
TO 'admin_granter'@'localhost'
IDENTIFIED BY 'avocet_123'
WITH GRANT OPTION;
GRANT ALL PRIVILEGES ON birdwatchers.*
TO 'admin_granter'@'localhost'
IDENTIFIED BY 'avocet_123'
WITH GRANT OPTION; - Answer:
透過 WITH GRANT OPTION 語法, 可以將自身擁有的權限賦予給其他帳號
以下的 MySQL example code 的意思是?
- Example:
CREATE USER 'admin_import'@'localhost'
IDENTIFIED BY 'another_pwd_789';
GRANT FILE ON *.*
TO 'admin_import'@'localhost'; - Answer:
建立一個可從檔案匯入資料的帳號, 擁有權限的帳號相當於可以讀取 MySQL 在主機上有權觸及的任何檔案, 並且可以把資料匯入到任何一個資料庫, 反之, 也可從資料庫會出資料, 甚至是含有密碼的資料庫
以下的 MySQL example code 的意思是?
- Example:
CREATE USER 'admin_restore'@'localhost'
IDENTIFIED BY 'different_pwd_456';
GRANT INSERT, LOCK TABLES, CREATE,
CREATE TEMPORARY TABLES, INDEX, ALTER
ON rookery.*
TO 'admin_restore'@'localhost';
GRANT INSERT, LOCK TABLES, CREATE,
CREATE TEMPORARY TABLES, INDEX, ALTER
ON birdwatchers.*
TO 'admin_restore'@'localhost'; - Answer:
建立一個專門還原備份資料的使用者
要從 dump file 復原, 所以必須要具有 INSERT 權限
復原時為了能鎖定資料表, 因此需要 LOCK TABLES 權限
要重建資料表, 因此需要 CREATE 權限
要重建 index, 因此需要 INDEX 權限
dump 內的 SQL 敘述可能會修改資料表, 因此需要 ALTER 權限
如果想把資料還原至臨時資料表, 那就需要 CREATE TEMPORARY TABLES 權限
如果還有包含 TRIGGER 或 VIEW, 那就要加上 CREATE VIEW 和 TRIGGER 權限
以下的 MySQL example code 的意思是?
- Example:
CREATE USER 'admin_backup'@'localhost'
IDENTIFIED BY 'its_password_123';
GRANT SELECT, LOCK TABLES
ON rookery.*
TO 'admin_backup'@'localhost';
GRANT SELECT, LOCK TABLES
ON birdwatchers.*
TO 'admin_backup'@'localhost'; - Answer:
建立一個管理備份用的帳號, 賦予 SELECT 權限, 所以可讀取資料庫, 因為在備份的過程中必須 lock table, 所以賦予 LOCK TABLES 權限, 只限定特定資料庫
以下的 Shell script example code 的意思是?
- Example:
#!/bin/sh
mysql_connect="mysql --user root -pmy_pwd"
results=`$mysql_connect --skip-column-names \
--execute 'SHOW TABLES FROM birdwatchers;'`
items=$(echo $results | tr " " "\n")
for item in $items
do
if [ $item = 'humans' ] ||
[ $item = 'birder_families' ] ||
[ $item = 'birding_events_children' ]
then
continue
fi
`$mysql_connect --execute "GRANT SELECT ON birdwatchers.$item \
TO 'lena_stankoska'@'lena_stankoska_home'"`
done
exit - Answer:
由於 MySQL 中, 如果要 GRANT 特定權限給特定 table 必須要一個一個指定, 所以使用 shell script 來批量 GRANT
以下的 MySQL example code 的意思是?
- Example:
SELECT COLUMN_GET(choices, answer AS CHAR)
AS 'Birding Site',
COUNT(*) AS 'Votes',
CONCAT( TRUNCATE( (COUNT(*) / @fav_site_total) * 100, 1), '%')
AS 'Percent'
FROM survey_answers
JOIN survey_questions USING(question_id)
WHERE survey_id = 1
AND question_id = 1
GROUP BY answer; - Answer:
TRUNCATE() 的 arg1 表示要處理的 input, arg2 表示小數位 1 位之後都要拿掉
以下的 MySQL function 的差異是?
- Example:
ROUND()
FLOOR()
CEILING() - Answer:
四捨五入, 無條件捨去, 無條件進位
以下的 MySQL example code 的意思是?
- Example:
SELECT COLUMN_GET(choices, answer AS CHAR)
AS 'Birding Site',
COUNT(*) AS 'Votes',
(COUNT(*) / @fav_site_total) AS 'Percent'
FROM survey_answers
JOIN survey_questions USING(question_id)
WHERE survey_id = 1
AND question_id = 1
GROUP BY answer; - Answer:
@fav_site_total 為 variable, 需事先定義
以下的 MySQL example code 的意思是?
- Example:
SET @fav_site_total =
(SELECT COUNT(*)
FROM survey_answers
JOIN survey_questions USING(question_id)
WHERE survey_id = 1
AND question_id = 1);
SELECT @fav_site_total; - Answer:
@fav_site_total 為變數, assign 一段 SQL query
以下的 MySQL example code 的意思是?
- Example:
SELECT IFNULL(COLUMN_GET(choices, answer AS CHAR), 'total')
AS 'Birding Site', COUNT(*) AS 'Votes'
FROM survey_answers
JOIN survey_questions USING(question_id)
WHERE survey_id = 1
AND question_id = 1
GROUP BY answer WITH ROLLUP; - Answer:
使用 COLUMN_GET(), 從 choices column 取值。 其為 MariaDB 的 blob data type, 可以存多組 key/value, 並且取值時要指定型別
以下的 MySQL example code 的意思是?
- Example:
SELECT NOW(), event_date, start_time,
CONCAT(
DATEDIFF(event_date, DATE(NOW())), ' Days, ',
DATE_FORMAT(TIMEDIFF(start_time, TIME(NOW())), '%k hours, %i minutes'))
AS 'Time to Event'
FROM birding_events; - Answer:
使用 DATEDIFF() 取得 event_date 以及 NOW() 的差異天數
使用 TIMEDIFF() 將 start_time 以及現在的時間的差異 小時, 分鐘 取出
再使用 CONCAT 串起來

以下的 MySQL example code 的意思是?
- Example:
SELECT CURDATE() AS 'Today',
DATE_FORMAT(membership_expiration, '%M %e, %Y')
AS 'Date Membership Expires',
DATEDIFF(membership_expiration, CURDATE())
AS 'Days Until Expiration'
FROM humans
WHERE human_id = 4; - Answer:
使用 DATEDIFF() 來比較兩個日期時間的差異天數

以下的 MySQL example code 的意思是?
- Example:
SELECT CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
COUNT(time_seen) AS 'Sightings Recorded'
FROM bird_sightings
JOIN humans USING(human_id)
WHERE CONCAT(QUARTER(time_seen), YEAR(time_seen)) =
CONCAT(
QUARTER(
STR_TO_DATE(
PERIOD_ADD( EXTRACT(YEAR_MONTH FROM CURDATE()), -3),
'%Y%m') ),
YEAR(
STR_TO_DATE(
PERIOD_ADD( EXTRACT(YEAR_MONTH FROM CURDATE()), -3),
'%Y%m') ) )
GROUP BY human_id LIMIT 5; - Answer:
先用 EXTRACT() 將 YEAR_MONTH 從目前時間取出, 接著使用 PERIOD_ADD() 減掉 3 個月, 再用 STR_TO_DATE 設定成 ‘%Y%m’ 格式, 最後再用 QUARTER() 以及 YEAR 算出第幾季以及第幾年

以下的 MySQL example code 的意思是?
- Example:
SELECT TIME(NOW()),
TIME_TO_SEC(NOW()),
TIME_TO_SEC(NOW()) / 60 /60 AS 'Hours'; - Answer:
僅將 時間 部分轉換成秒數, 即今天至今已過了幾秒

以下的 MySQL example code 的意思是?
- Example:
UPDATE bird_sightings
SET time_seen = DATE_ADD(time_seen, INTERVAL '1 2' DAY_HOUR)
WHERE sighting_id = 16; - Answer:
使用 DATE_ADD(), 增加 1 天 2 小時
以下的 MySQL example code 的意思是?
- Example:
UPDATE humans
SET membership_expiration = DATE_ADD(membership_expiration, INTERVAL -1 YEAR)
WHERE CONCAT(name_first, SPACE(1), name_last) = 'Melissa Lee'; - Answer:
當使用負號, DATE_ADD() 也有 DATE_SUB() 的效果
以下的 MySQL example code 的意思是?
- Example:
UPDATE humans
SET membership_expiration = DATE_SUB(membership_expiration, INTERVAL 1 YEAR)
WHERE CONCAT(name_first, SPACE(1), name_last) = 'Melissa Lee'; - Answer:
更新 membership_expiration, 使用 DATE_SUB 扣掉一年
以下的 MySQL example code 的意思是?
- Example:
UPDATE humans
SET membership_expiration = DATE_ADD(membership_expiration, INTERVAL 3 MONTH)
WHERE country_id = 'uk'
AND membership_expiration > CURDATE( ); - Answer:
更新 membership_expiration, 使用 DATE_ADD 將日期往後增加三個月
以下的 MySQL my.cnf example code 的意思是?
- Example:
default-time-zone='GMT'
- Answer:
將 server 的預設時區改為 GMT
以下的 MySQL example code 的意思是?
- Example:
SELECT common_name AS 'Bird',
CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
DATE_FORMAT(time_seen, '%r') AS 'System Time Spotted',
DATE_FORMAT(CONVERT_TZ(time_seen, 'US/Eastern', 'Europe/Rome'), '%r')
AS 'Birder Time Spotted'
FROM bird_sightings
JOIN humans USING(human_id)
JOIN rookery.birds USING(bird_id)
JOIN rookery.conservation_status USING(conservation_status_id) LIMIT 3; - Answer:
使用 CONVERT_TZ, arg1 為時間, arg2 為來源時區, arg3 為欲轉換成的時區, 再將結果作為 parameter 帶入 DATE_FORMAT()

以下的 MySQL example code 的意思是?
- Example:
SHOW VARIABLES LIKE 'time_zone';
- Answer:
取得 MySQL 系統時區

以下的 MySQL example code 的意思是?
- Example:
SELECT DATE_FORMAT(CURDATE(), GET_FORMAT(DATE,'EUR'))
AS 'Date in Europe',
DATE_FORMAT(CURDATE(), GET_FORMAT(DATE,'USA'))
AS 'Date in U.S.',
REPLACE(DATE_FORMAT(CURDATE(), GET_FORMAT(DATE,'USA')), '.', '-')
AS 'Another Date in U.S.'; - Answer:
使用 GET_FORMAT 取得特定地區的時間格式, 再將結果帶入 DATE_FORMAT 完成格式設定
使用 REPLACE 將不喜歡的格式做客製化替換

以下的 MySQL example code 的意思是?
- Example:
SELECT common_name AS 'Endangered Bird',
CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
DATE_FORMAT(time_seen, '%W, %M %e, %Y') AS 'Date Spotted',
TIME_FORMAT(time_seen, '%l:%i %p') AS 'Time Spotted'
FROM bird_sightings
JOIN humans USING(human_id)
JOIN rookery.birds USING(bird_id)
JOIN rookery.conservation_status USING(conservation_status_id)
WHERE conservation_category = 'Threatened' LIMIT 3; - Answer:
使用 DATE_FORMAT, TIME_FORMAT 從指定時間擷取並輸入定義的格式, 格式碼可參考

以下的 MySQL example code 的意思是?
- Example:
SELECT time_seen,
EXTRACT(YEAR_MONTH FROM time_seen) AS 'Year & Month',
EXTRACT(MONTH FROM time_seen) AS 'Month Only',
EXTRACT(HOUR_MINUTE FROM time_seen) AS 'Hour & Minute',
EXTRACT(HOUR FROM time_seen) AS 'Hour Only'
FROM bird_sightings JOIN humans USING(human_id)
LIMIT 3; - Answer:
使用 EXTRACT() 從指定時間中擷取特定格式, EXTRACT() 支援格式可參考

以下的 MySQL example code 的意思是?
- Example:
SELECT time_seen,
EXTRACT(YEAR_MONTH FROM time_seen) AS 'Year & Month',
EXTRACT(MONTH FROM time_seen) AS 'Month Only',
EXTRACT(HOUR_MINUTE FROM time_seen) AS 'Hour & Minute',
EXTRACT(HOUR FROM time_seen) AS 'Hour Only'
FROM bird_sightings JOIN humans USING(human_id)
LIMIT 3; - Answer:
使用 EXTRACT() 從指定時間中擷取特定格式, EXTRACT() 支援格式可參考
以下的 MySQL example code 的意思是?
- Example:
SELECT common_name AS 'Endangered Bird',
CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
CONCAT(DAYNAME(time_seen), ', ', MONTHNAME(time_seen), SPACE(1),
DAY(time_seen), ', ', YEAR(time_seen)) AS 'Date Spotted',
CONCAT(HOUR(time_seen), ':', MINUTE(time_seen),
IF(HOUR(time_seen) < 12, ' a.m.', ' p.m.')) AS 'Time Spotted'
FROM bird_sightings
JOIN humans USING(human_id)
JOIN rookery.birds USING(bird_id)
JOIN rookery.conservation_status USING(conservation_status_id)
WHERE conservation_category = 'Threatened' LIMIT 3; - Answer:
使用 DAYNAME(), MONTHNAME, 分別擷取帶入時間, 並輸出成 Day 的英文單字, 月份英文單字
使用 DAY(), YEAR(), HOUR(), MINUTE(), 分別擷取帶入時間的 天, 年, 時, 分
最後判斷, 如果 HOUR 小於 12, 即為上午 a.m., 大於 12, 即下午 p.m.

以下的 MySQL example code 的意思是?
- Example:
SELECT CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
time_seen, YEAR(time_seen), MONTH(time_seen), DAY(time_seen),
MONTHNAME(time_seen), DAYNAME(time_seen)
FROM bird_sightings JOIN humans USING(human_id)
WHERE bird_id = 309 \G - Answer:
使用 YEAR(), MONTH(), DAY(), 分別擷取帶入時間的 年, 月, 日
使用 MONTHNAME(), DAYNAME(), 分別擷取並輸出成帶入時間的 月份英文單字, day 的英文單字

以下的 MySQL example code 的意思是?
- Example:
SELECT CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
time_seen, HOUR(time_seen), MINUTE(time_seen), SECOND(time_seen)
FROM bird_sightings JOIN humans USING(human_id)
WHERE bird_id = 309 \G - Answer:
使用 HOUR(), MINUTE(), SECOND(), 分別擷取帶入時間的 小時, 分, 秒

以下的 MySQL example code 的意思是?
- Example:
SELECT CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
time_seen, DATE(time_seen), TIME(time_seen)
FROM bird_sightings
JOIN humans USING(human_id)
WHERE bird_id = 309; - Answer:
使用 DATE(), TIME() 分別擷取帶入時間的 年月日 以及 時間 部分

以下的 MySQL example code 的意思是?
- Example:
SELECT CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
ROUND((UNIX_TIMESTAMP( ) - UNIX_TIMESTAMP(time_seen)) / 60 / 60 / 24)
AS 'Days Since Spotted'
FROM bird_sightings JOIN humans USING(human_id)
WHERE bird_id = 309; - Answer:
SELECT CONCAT(name_first, SPACE(1), name_last) AS 'Birdwatcher',
# UNIX_TIMESTAMP() 為取得 1970 年 1 月 1 號至今所經過的秒數
# 帶入特定時間點並經過計算後, 可取得特定時間點至今所經過的天數
ROUND((UNIX_TIMESTAMP() - UNIX_TIMESTAMP(time_seen)) / 60 / 60 / 24)
AS 'Days Since Spotted'
FROM bird_sightings JOIN humans USING(human_id)
WHERE bird_id = 309;

以下的 MySQL example code 的意思是?
- Example:
SELECT NOW(), CURDATE(), CURTIME();
- Answer:
分別是取得當前日期時間, 當前日期, 當前時間

以下的 MySQL example code 的意思是?
- Example:
SELECT NOW(), SLEEP(4) AS 'Zzz', SYSDATE(), SLEEP(2) AS 'Zzz', SYSDATE();
- Answer:
NOW() 是取得 SQL Query 執行當下的時間, 而 SYSDATE() 是取得該函式執行當下的時間, 如果要在複雜的 SQL Query 當中取得某段函式的執行時間時, 便可使用 SYSDATE()

MySQL 中, 以下幾個函式的功能都一樣, 為什麼需要這麼多不同名稱卻同功能的函示?
- Example:
NOW(), CURRENT_TIMESTAMP(), LOCALTIME(), LOCALTIMESTAMP() - Answer:
因為為了配合其他種類的資料庫, 像是 PostgreSQL, Oracle, Sybase 等等…
這樣原本使用其他資料庫的應用程式就可以在不更動程式碼下直接更換資料庫
以下的 MySQL example code 的意思是?
- Example:
SELECT UNCOMPRESS(birding_background) AS Background
FROM humans
WHERE name_first = 'Melissa' AND name_last = 'Lee' \G - Answer:
UNCOMPRESS function 可以解壓縮 COMPRESS function 壓縮過的欄位資料
以下的 MySQL example code 的意思是?
- Example:
INSERT INTO humans
(formal_title, name_first, name_last, join_date, birding_background)
VALUES('Ms', 'Melissa', 'Lee', CURDATE(), COMPRESS("lengthy background...")); - Answer:
COMPRESS function 可以壓縮字串, 適用於大量的 text, 效能有待研究
以下的 MySQL example code 的意思是?
- Example:
SELECT bird_name, gender_age, bird_image
FROM bird_images
WHERE bird_name LIKE '%Plover%'
ORDER BY CONVERT(gender_age USING utf8)
LIMIT 5; - Answer:
將 gender_age 的 character set 暫時轉為 utf8
以下的 MySQL example code 的意思是?
- Example:
SELECT bird_name, gender_age, bird_image
FROM bird_images
WHERE bird_name LIKE '%Plover%'
ORDER BY CONVERT(gender_age, CHAR)
LIMIT 5; - Answer:
將 gender_age 的 column type 暫時轉換為 CHAR, 只反映在結果上, 並不會真正更動資料庫
MySQL 中, 如果 column type 是 enum, 那排序上會依照 enum 的排序還是 collation 的排序?
enum 的排序
以下的 MySQL example code 的意思是?
- Example:
SELECT sorting_id, bird_name, bird_image
FROM bird_images ORDER BY CAST(sorting_id AS INT) LIMIT 5; - Answer:
將 sorting_id column type 暫時轉換為 INT, 只作用到結果, 不會變動 column type
以下的 MySQL example 為什麼 sorting_id 的排列方式是如此?
- Example:
SELECT sorting_id, bird_name, bird_image
FROM bird_images
ORDER BY sorting_id
LIMIT 5; - Answer:
因為 sorting_id column 的 column type 被設為 char, 而非 int

以下的 MySQL example code 的意思是?

- Example:
SELECT common_name AS Original,
REPLACE(common_name, 'Gt.', 'Great') AS Replaced
FROM birds
WHERE common_name REGEXP 'Gt.' LIMIT 1; - Answer:
REPLACE() 跟 REPLACE 不同
直接尋找 ‘Gt.’ 並將之替換為 ‘Great’, 只改變顯示結果, 並不會真正的更動資料庫
以下的 MySQL example code 的意思是?

- Example:
SELECT common_name AS Original,
INSERT(common_name, LOCATE('Gt.', common_name), 3, 'Great') AS Adjusted
FROM birds
WHERE common_name REGEXP 'Gt.' LIMIT 1; - Answer:
INSERT() 跟 INSERT 不同, INSERT() 只會將結果替換掉指定的字串, 不會真正的更動資料庫
arg1 為要作用的欄位, arg2 為替換起始位置, arg3 為總共要覆蓋原本字串多少個字, arg4 為要用來替換的字串
如上 example, LOCATE 會回傳 1, 所以從 1 開始替換 ‘Gt.’ 共三個字, 所以會全部覆蓋掉
若不希望覆蓋掉任何字, arg3 可指定 0
以下的 MySQL example code 的意思是?
- Example:
SELECT CONCAT(name_first, SPACE(1), name_last) AS Name,
common_name AS Bird,
SUBSTRING(comments, 1, 25) AS Comments
FROM birdwatchers.bird_sightings
JOIN birdwatchers.humans USING(human_id)
JOIN rookery.birds USING(bird_id)
WHERE MATCH (comments) AGAINST ('beautiful'); - Answer:
SELECT CONCAT(name_first, SPACE(1), name_last) AS Name,
common_name AS Bird,
# 從第 1 個位置開始取, 取 25 個字
SUBSTRING(comments, 1, 25) AS Comments
FROM birdwatchers.bird_sightings
JOIN birdwatchers.humans USING(human_id)
JOIN rookery.birds USING(bird_id)
# 唯有先行建立 FULLTEXT INDEX, 方可使用 MATCH ... AGAINST 函數
# 從 'comments' column 尋找 'beautiful' 字串
WHERE MATCH (comments) AGAINST ('beautiful');
以下的 MySQL example code 的意思是?
- Example:
CREATE FULLTEXT INDEX comment_index
ON bird_sightings (comments); - Answer:
建立 FULLTEXT index 名為 comment_index, 唯有建立 FULLTEXT index 方可使用 match … against 函數
以下的 MySQL example code 的意思是?
- Example:
INSERT IGNORE INTO possible_duplicate_email
(human_id, email_address_1, email_address_2, entry_date)
VALUES(LAST_INSERT_ID(), 'bobyfischer@mymail.com', 'bobbyfischer@mymail.com')
WHERE ABS( STRCMP('bobbyrobin@mymail.com', 'bobyrobin@mymail.com') ) = 1 ; - Answer:
INSERT IGNORE INTO possible_duplicate_email
(human_id, email_address_1, email_address_2, entry_date)
VALUES(LAST_INSERT_ID(), 'bobyfischer@mymail.com', 'bobbyfischer@mymail.com')
## ABS 會將 value 轉為絕對值, 即 -1 變成 1, 1 還是 1
## STRCMP 會比較兩個數, 相等則為 0, 否則則為 1 或 -1
WHERE ABS( STRCMP('bobbyrobin@mymail.com', 'bobyrobin@mymail.com') ) = 1 ;
以下的 MySQL example code 的意思是?
- Example:
SELECT IF(CHAR_LENGTH(comments) > 100), 'long', 'short')
FROM bird_sightings
WHERE sighting_id = 2; - Answer:
select'comments'欄位, 如果長度大於 100, 則回傳'long', 反之則回傳'short'
以下的 MySQL example code 的意思是?
- Example:
SELECT FIND_IN_SET('Anahit Vanetsyan', Names) AS Position
FROM
(SELECT GROUP_CONCAT(Name ORDER BY join_date) AS Names
FROM
( SELECT CONCAT(name_first, SPACE(1), name_last) AS Name,
join_date
FROM humans
WHERE country_id = 'ru')
AS derived_1 )
AS derived_2; - Answer:
GROUP_CONCAT 會將 Name column 的所有姓名連接起來, 並 ORDER BY join_date, 然後 FIND_IN_SET() 從 Name column 中找到 ‘Anahit Vanetsyan’ 的位置


以下的 MySQL example code 的意思是?
- Example:
SELECT
SUBSTRING(common_name, 1, LOCATE(' Avocet', common_name) ) AS 'Avocet'
FROM birds
JOIN bird_families USING(family_id)
WHERE bird_families.scientific_name = 'Recurvirostridae'
AND birds.common_name LIKE '%Avocet%'; - Answer:
LOCATE 會取得 ‘ Avocet’ 前面那一個空格的位置, 而 SUBSTRING 從第 1 個位置開始取, 取 LOCATE 得到的結果, 正好把 ‘Avocet’ 濾掉


以下的 MySQL query 的意思是?
- Example:
# +--------------------------------------------------------+
# | prospect_name |
# +--------------------------------------------------------+
# | Ms.| Caryn-Amy | Rose |
# | Mr.| Colin | Charles |
# | Mr.| Kenneth | Dyer |
# | Ms.| Sveta | Smirnova |
# +--------------------------------------------------------+
SELECT SUBSTRING_INDEX(prospect_name, '|', 1) AS title,
SUBSTRING_INDEX( SUBSTRING_INDEX(prospect_name, '|', 2), '|', -1) AS first_name,
SUBSTRING_INDEX(prospect_name, '|', -1) AS last_name
FROM prospects WHERE prospect_id = 7; - Answer:
// 取到第一個 '|' 之前的所有字串
SELECT SUBSTRING_INDEX(prospect_name, '|', 1) AS title,
// 內函數取得第兩個 '|' 之前的所有字串, 外函數則是從尾端往前找, 直到找到 '|', 取這之間的字串
SUBSTRING_INDEX( SUBSTRING_INDEX(prospect_name, '|', 2), '|', -1) AS first_name,
// 從尾端往前找, 直到找到 '|', 取這之間的字串
SUBSTRING_INDEX(prospect_name, '|', -1) AS last_name
FROM prospects WHERE prospect_id = 7;
以下的 MySQL query 的意思是?
- Example:
# +--------------------------------------------------------+
# | prospect_name |
# +--------------------------------------------------------+
# | Ms. Caryn-Amy Rose |
# | Mr. Colin Charles |
# | Mr. Kenneth Dyer |
# | Ms. Sveta Smirnova |
# +--------------------------------------------------------+
SELECT SUBSTRING(prospect_name, 1, 2) AS title,
SUBSTRING(prospect_name FROM 5 FOR 25) AS first_name,
SUBSTRING(prospect_name, -25) AS last_name
FROM prospects LIMIT 3; - Answer:
// 從第 1 個開始取, 取 2 個
SELECT SUBSTRING(prospect_name, 1, 2) AS title,
// 從第 5 個開始取, 取 25 個
SUBSTRING(prospect_name FROM 5 FOR 25) AS first_name,
// 取後面算來 25 個
SUBSTRING(prospect_name, -25) AS last_name
FROM prospects LIMIT 3;
以下的 MySQL query 的意思是?
- Example:
# +--------------------------------------------------------+
# | prospect_name |
# +--------------------------------------------------------+
# | Ms. Caryn-Amy Rose |
# | Mr. Colin Charles |
# | Mr. Kenneth Dyer |
# | Ms. Sveta Smirnova |
# +--------------------------------------------------------+
SELECT LEFT(prospect_name, 2) AS title,
MID(prospect_name, 5, 25) AS first_name,
RIGHT(prospect_name, 25) AS last_name
FROM prospects LIMIT 4; - Answer:
LEFT: 從左邊開始取, 取 2 個
MID: 從第 5 個開始取, 取 25 個
RIGHT: 從後面往前取, 取 25 個
以下的 MySQL query 的意思是?
- Example:
SELECT CONCAT(RPAD(common_name, 20, '.' ),
RPAD(Families.scientific_name, 15, '.'),
Orders.scientific_name) AS Birds
FROM birds
JOIN bird_families AS Families USING(family_id)
JOIN bird_orders AS Orders
WHERE common_name != ''
AND Orders.scientific_name = 'Ciconiiformes'
ORDER BY common_name LIMIT 3;
# +--------------------------------------------------+
# | Birds |
# +--------------------------------------------------+
# | Abbott's Babbler....Pellorneidae...Ciconiiformes |
# | Abbott's Booby......Sulidae........Ciconiiformes |
# | Abbott's Starling...Sturnidae......Ciconiiformes |
# +--------------------------------------------------+ - Answer:
利用 RPAD 將空格填滿, arg1 為作用的 column, arg2 為該 column 預期的字串長度, arg3 為不足字串長度時, 要使用什麼字符將之補滿
以下的 MySQL query 的意思是?
- Example:
SELECT QUOTE(common_name)
FROM birds
WHERE common_name LIKE "%Prince%"
ORDER BY common_name; - Answer:
# 將資料夾上 quote 輸出, 並 escape 特殊符號
SELECT QUOTE(common_name)
FROM birds
WHERE common_name LIKE "%Prince%"
ORDER BY common_name;
# +----------------------------------+
# | QUOTE(common_name) |
# +----------------------------------+
# | 'Prince Henry\'s Laughingthrush' |
# | 'Prince Ruspoli\'s Turaco' |
# | 'Princess Parrot' |
# +----------------------------------+
以下的 MySQL query 的意思是?
- Example:
SELECT LCASE(common_name) AS Species,
UCASE(bird_families.scientific_name) AS Family
FROM birds
JOIN bird_families USING(family_id)
WHERE common_name LIKE '%Wren%'
ORDER BY Species
LIMIT 5; - Answer:
## 將 common_name column 的值轉為小寫
SELECT LCASE(common_name) AS Species,
## 將 scientific_name column 的值轉為大寫
UCASE(bird_families.scientific_name) AS Family
FROM birds
## 經由 family_id JOIN 兩張表
JOIN bird_families USING(family_id)
WHERE common_name LIKE '%Wren%'
ORDER BY Species
LIMIT 5;
# +-------------------------+---------------+
# | Species | Family |
# +-------------------------+---------------+
# | apolinar's wren | TROGLODYTIDAE |
# | band-backed wren | TROGLODYTIDAE |
# | banded wren | TROGLODYTIDAE |
# | bar-winged wood-wren | TROGLODYTIDAE |
# | bar-winged wren-babbler | TIMALIIDAE |
# +-------------------------+---------------+
以下的 MySQL query 的意思是?
- Example:
mysql -p --skip-column-names -e \
"SELECT CONCAT_WS('|', IFNULL(formal_title, ' '), IFNULL(name_first, ' '),
IFNULL(name_last, ' '), IFNULL(street_address, ' '),
IFNULL(city, ' '), IFNULL(state_province, ' '),
IFNULL(postal_code, ' '), IFNULL(country_id, ' '))
FROM birdwatchers.humans WHERE membership_type = 'premium'
AND membership_expiration > CURDATE();" > rookery_patch_mailinglist.txt - Answer:
mysql -p --skip-column-names -e \
# 跳過欄位那一欄不做處理, -p 代表 password, -e 代表執行 "" 內的程式碼
# 使用 '|' 來連接並隔開每個 column 的value
# CONCAT_WS, WS 為 with seprarator 的意思
"SELECT CONCAT_WS('|', IFNULL(formal_title, ' '), IFNULL(name_first, ' '),
# 加上 IFNULL, 若 NULL 的話也會輸出空字串, 否則 CONCAT_WS 會不處理直接跳過
# 造成 select 8 個欄位, 但卻只輸出 4 個欄位的值, 也不知道哪個欄位沒值
IFNULL(name_last, ' '), IFNULL(street_address, ' '),
IFNULL(city, ' '), IFNULL(state_province, ' '),
IFNULL(postal_code, ' '), IFNULL(country_id, ' '))
FROM birdwatchers.humans WHERE membership_type = 'premium'
# 將結果輸出到 txt 檔
AND membership_expiration > CURDATE();" > rookery_patch_mailinglist.txt
以下的 MySQL query 的意思是?
- Example:
SELECT common_name AS 'Bird',
conservation_state AS 'Status'
FROM birds
LEFT JOIN conservation_status USING(conservation_status_id)
WHERE common_name LIKE '%Egret%'
ORDER BY Status, Bird; - Answer:
從 birds table select common_name column (命名呈現的 column name 為 Bird), conservation_state column (命名呈現的 column name 為 Status)
left join conservation_status table, 透過 conservation_status_id
left join 會先取出 birds table, 所以如果並沒有對應的 conservation_status_id 的話, 就會顯示 null
像是+--------------------+-----------------+
| Bird | Status |
+--------------------+-----------------+
| Great Egret | NULL |
| Cattle Egret | Least Concern |
| Intermediate Egret | Least Concern |
| Little Egret | Least Concern |
| Snowy Egret | Least Concern |
| Reddish Egret | Near Threatened |
| Chinese Egret | Vulnerable |
| Slaty Egret | Vulnerable |
+--------------------+-----------------+
以下的 MySQL query 的意思是?
- Example:
SELECT book_id, title, status_name
FROM books
JOIN status_names USING(status_id); - Answer:
JOIN books 跟 status_names 兩張 table, 因為要用來 connect 兩張 table 的 key 都一樣, 因此使用 USING
以下的 MySQL query 的意思是?
- Example:
SELECT book_id, title, status_name
FROM books
JOIN status_names ON(status = status_id); - Answer:
JOIN books 跟 status_names 兩張 table, 用 ON 連結 status 以及 status_id 欄位
以下的 MySQL query 的意思是?
- Example:
SELECT 'Pelecanidae' AS 'Family',
COUNT(*) AS 'Species'
FROM birds, bird_families AS families
WHERE birds.family_id = families.family_id
AND families.scientific_name = 'Pelecanidae'
UNION
SELECT 'Ardeidae',
COUNT(*)
FROM birds, bird_families AS families
WHERE birds.family_id = families.family_id
AND families.scientific_name = 'Ardeidae'; - Answer:
## 'Pelacanidae' 為不存在的欄位, 以純文字賦予欄位值, 結果如下
SELECT 'Pelecanidae' AS 'Family',
## Species 為另一個 column
COUNT(*) AS 'Species'
FROM birds, bird_families AS families
WHERE birds.family_id = families.family_id
AND families.scientific_name = 'Pelecanidae'
UNION
## 因為使用 Union, 這邊不須再加 alias, 會自動歸類到 'Family' column
SELECT 'Ardeidae',
COUNT(*)
FROM birds, bird_families AS families
WHERE birds.family_id = families.family_id
AND families.scientific_name = 'Ardeidae';
## +-------------+---------+
## | Family | Species |
## +-------------+---------+
## | Pelecanidae | 10 |
## | Ardeidae | 157 |
## +-------------+---------+
以下的 MySQL query 的意思是?
- Example:
DELETE FROM humans, prize_winners
USING humans JOIN prize_winners
WHERE name_first = 'Elena'
AND name_last = 'Bokova'
AND email_address LIKE '%yahoo.com'
AND humans.human_id = prize_winners.human_id; - Answer:
// 同時 delete humans 以及 prize_winners 的資料
// 如果不加 prize_winners, 那該 table 上的資料就
// 不會被刪除
DELETE FROM humans, prize_winners
// JOIN prize_winners table
USING humans JOIN prize_winners
WHERE name_first = 'Elena'
AND name_last = 'Bokova'
AND email_address LIKE '%yahoo.com'
AND humans.human_id = prize_winners.human_id;
以下的 MySQL query 的意思是?
- Example:
CREATE TEMPORARY TABLE possible_duplicates
(name_1 varchar(25), name_2 varchar(25)); - Answer:
建立一個臨時的 table, 當退出 MySQL client 時, 該 table 會自動銷毀
以下的 MySQL query 的意思是?
- Example:
INSERT INTO humans
(formal_title, name_first, name_last, email_address, better_birders_site)
VALUES('Mr','Barry','Pilson', 'barry@gomail.com', 1),
('Ms','Lexi','Hollar', 'alexandra@mysqlresources.com', 1),
('Mr','Ricky','Adams', 'ricky@gomail.com', 1)
ON DUPLICATE KEY
UPDATE better_birders_site = 2; - Answer:
因為 email_address 有 unique 特性, 所以當 insert 過程中發現有 duplicate 的 row 時, 會 update 該 row 的 better_birders_site column 為 2
以下的 MySQL query 錯誤的原因是?
- Example:
UPDATE prize_winners, humans
SET winner_date = CURDATE()
WHERE winner_date IS NULL
AND country_id = 'uk'
AND prize_winners.human_id = humans.human_id
ORDER BY RAND()
LIMIT 2; - Answer:
order by 及 limit 只適用於單一 table, 當 update 複數的 table 時就會出錯
以下的 MySQL query 的意思是?
- Example:
UPDATE prize_winners, humans
SET winner_date = NULL,
prize_chosen = NULL,
prize_sent = NULL
WHERE country_id = 'uk'
AND prize_winners.human_id = humans.human_id; - Answer:
從 human table 中取得 ‘country_id = uk’ 的 row, 再經此找到符合 ‘prize_winners.human_id = humans.human_id’ 的 prize_winners
最後 update 這些 prize_winners 的 winner_date, prize_chosen, prize_sent columns
以下的 MySQL query 的意思是?
- Example:
ALTER TABLE humans
CHANGE COLUMN formal_title formal_title ENUM('Mr.','Ms.','Mr','Ms');
UPDATE humans
SET formal_title = SUBSTRING(formal_title, 1, 2);
ALTER TABLE humans
CHANGE COLUMN formal_title formal_title ENUM('Mr','Ms'); - Answer:
## 修改 humans table
ALTER TABLE humans
## 將 column formal_title 改成 formal_title, type 為 ENUM('Mr.', 'Ms.', 'Mr', 'Ms');
CHANGE COLUMN formal_title formal_title ENUM('Mr.','Ms.','Mr','Ms');
## 更新 humans table
UPDATE humans
## 更新 formal_title column, 取 formal_title 的值, 從第一個字開始取, 共取兩個字
## 因此 "Mr." 會變成 "Mr"
SET formal_title = SUBSTRING(formal_title, 1, 2);
## 同上, 修改 formal_title colum 的 type
ALTER TABLE humans
CHANGE COLUMN formal_title formal_title ENUM('Mr','Ms');
以下的 MySQL query 的意思是?
- Example:
select common_name as 'hawks'
from birds
where common_name regexp '[[:space:]]hawk|[[.hyphen.]]hawk'
and common_name not regexp 'hawk-owl|hawk owl'
order by family_id; - Answer:
## select common_name column, 並定義新欄位名稱為 Hawks
select common_name as 'hawks'
## 從 birds table
from birds
## common_name 的值必須是 " hawk", 或是 "-hawk"
where common_name regexp '[[:space:]]hawk|[[.hyphen.]]hawk'
## common_name 的值必須不是 "hawk_owl" 或 "hawk owl"
and common_name not regexp 'hawk-owl|hawk owl'
## 經由 family_id column 排序
order by family_id;
以下的 MySQL column information 中, latin1_bin 的 bin 是什麼意思?
- Example:
SHOW FULL COLUMNS
FROM birds LIKE 'common_name' \G
*************************** 1. row ***************************
Field: common_name
Type: varchar(255)
Collation: latin1_bin
Null: YES
Key:
Default: NULL
Extra:
Privileges: select,insert,update,references
Comment: - Answer:
binary 的意思, 表示儲存在該欄位的資料都會以 binary 定序
以下的 MySQL example code 是什麼意思?
- Example:
SELECT common_name AS 'Hawks'
FROM birds
WHERE common_name REGEXP BINARY 'Hawk'
AND common_name NOT REGEXP 'Hawk-Owl'
ORDER BY family_id LIMIT 10; - Answer:
一般來說, REGEXP 不會區分大小寫, 若要區分, 可加上 BINARY, 會以二進制定序, h 跟 H 的二進制碼不同, 所以可以區分大小寫
以下的 MySQL example code 是什麼意思?
- Example:
SELECT common_name, scientific_name, family_id
FROM birds
WHERE family_id IN(103, 160, 162, 164)
AND common_name != ''
ORDER BY common_name
LIMIT 3, 2; - Answer:
從第三筆之後開始查詢, 取得兩筆資料, 相當於 offset 3, limit 2
以下的 MySQL example code 是什麼意思?
- Example:
INSERT HIGH_PRIORITY INTO bird_sightings
- Answer:
MySQL 預設 insert 的 priority 就大於 select, 但如果預設值被改掉, 就可以使用上面的語法
以下的 MySQL example code 有個與 MySQL Client 不方便的地方, 是什麼?
- Example:
INSERT LOW_PRIORITY INTO bird_sightings
- Answer:
在 low priority instruction 被執行之前, client 會一直卡住
以下的 MySQL example code 是什麼意思?
- Example:
INSERT LOW_PRIORITY INTO bird_sightings
- Answer:
先完成手邊的工作, 再處理 low priority 的工作
以下的 MySQL example code 是什麼意思?
- Example:
REPLACE INTO bird_families
(scientific_name, brief_description, order_id)
VALUES('Viduidae', 'Indigobirds & Whydahs', 128),
('Estrildidae', 'Waxbills, Weaver Finches, & Allies', 128),
('Ploceidae', 'Weavers, Malimbe, & Bishops', 128); - Answer:
將指定的 value insert 到指定的欄位, 如果遇到重複的, 則覆寫, 相當於 Laravel 中的 insertOrUpdate
以下的 MySQL example code 是什麼意思?
- Example:
UPDATE bird_families, bird_orders
SET bird_families.order_id = bird_orders.order_id
WHERE bird_families.order_id IS NULL
AND cornell_bird_order = bird_orders.scientific_name; - Answer:
將 bird_families table 中的 order_id update 為 bird_orders table 中的 order_id
只更新 where clause 中限制的 record
以下的 MySQL example code 是什麼意思?
- Example:
INSERT IGNORE INTO bird_families
(scientific_name, brief_description, cornell_bird_order)
SELECT bird_family, examples, bird_order
FROM cornell_birds_families_orders; - Answer:
從 cornell_birds_families_orders table, select bird_family, examples, bird_order 三個欄位, 並將 select 的結果 insert 到 bird_families table 的 scientific_name, brief_description, cornell_bird_order 欄位, 同時, 若過程中出現錯誤, ignore 錯誤繼續執行
以下的 MySQL example code 中, 為什麼會失敗?
- Example:
ALTER TABLE conservation_status
CHANGE status_id conservation_status_id INT AUTO_INCREMENT PRIMARY KEY;
ERROR 1068: Multiple primary key defined - Answer:
status_id 欄位原本已經有 primary_key, 這是一個 index
上面的語法在原本已經有一個 index 的同時, 又要增加一個 index, 所以報錯
應該要先把原本的 index 拿掉
以下的 MySQL example code 中, 為什麼最後一行的 common_name 要重複兩次?
- Example:
ALTER TABLE birds_new
ADD COLUMN body_id CHAR(2) AFTER wing_id,
ADD COLUMN bill_id CHAR(2) AFTER body_id,
ADD COLUMN endangered BIT DEFAULT b'1' AFTER bill_id,
CHANGE COLUMN common_name common_name VARCHAR(255); - Answer:
第一次是指要變更的 column 名稱
第二次是指要變更成哪個名稱
以下的 MySQL example code 中, 在建立 bill_id column 時, 理論上 body_id column 應該還沒創建出來, 那為什麼可以指定 bill_id after body_id 呢?
- Example:
ALTER TABLE birds_new
ADD COLUMN body_id CHAR(2) AFTER wing_id,
ADD COLUMN bill_id CHAR(2) AFTER body_id,
ADD COLUMN endangered BIT DEFAULT b'1' AFTER bill_id,
CHANGE COLUMN common_name common_name VARCHAR(255); - Answer:
在 MySQL ALTER 的過程中, 會先建立一張虛擬的表格, 如果語法執行上都沒有問題, 會用這張虛擬表格取代原本的
如果語法有錯, 則會刪除這張虛擬表格
MySQL 的 column property character set 以及 collation, 分別代表的意思是?
character set: 該欄位會儲存的語言屬於哪一種編碼
collation: 該欄位該以什麼樣的語種排序
以下的 MySQL command 的意思是?
- Example:
SHOW CREATE TABLE birds \G
- Answer:
顯示建立該 table 的語法
MySQL 中, CHAR 跟 VARCHAR, 使用的大原則是?
如果確切知道有幾個 character, 就使用 CHAR, 否則則使用 VARCHAR
MySQL 中, CHAR 跟 VARCHAR, 哪個較不會產生 fragmentation?
VARCHAR
MySQL 中, CHAR 跟 VARCHAR, 哪個使用 index 的 performance 較佳?
CHAR
MySQL 中, 當我使用 mysql client select, 有時會因為資料太多而資料欄位沒有排列好, 像下圖一樣, 這時候可以使用哪個 command 來顯示正確的格式?
- Example:
- Answer:
可在最後用\G取代;

MySQL 中, virtualAs column type 的作用是?
虛擬 column, 內容來自於其他 column 的計算結果(自定義), 比如說, 新增一個 virtualAs column 叫做 full_name, 自定義內容來自於 first_name + last_name
command line 中, 如果 filesystem 的目前登入者跟 MySQL 的 user 是同一個, 那在登入時我還需要使用 mysql -u username -p password 嗎?
不需要, 直接使用 mysql -p 即可
以下的 mysql command 的意思是?
- Example:
mysql -u root -p -e "GRANT ALL ON *.* TO 'russell'@'localhost';"
- Answer:
賦予 russell, host 為 localhost, 所有資料庫以及 table 的操作權限
第一個 * 的位置代表資料庫, * 表示全部資料庫
第二個 * 的位置代表 table, * 表示全部 table
以下的 mysql command 的意思是?
- Example:
mysql -u root -p -e "SHOW GRANTS FOR 'russell'@'localhost' \G"
- Answer:
顯示 russell 的所有權限
以下的 mysql command 的意思是?
- Example:
mysql -u root -p -e "GRANT SELECT ON *.* TO 'russell'@'localhost';"
- Answer:
給予 russell user, host 為 localhost, select 所有資料庫所有 table 的權限
以下的 mysql command 的意思是?
- Example:
mysql -u root -p -e "GRANT USAGE ON *.*
TO 'russell'@'localhost'
IDENTIFIED BY 'Rover#My_1st_Dog&Not_Yours!';" - Answer:
## 給予存取所有資料庫所有 table 的權限, 這裡是指可存取的 database 以及 table
## 但並沒有給予任何實際上的權限, 如 select, update, insert
mysql -u root -p -e "GRANT USAGE ON *.*
## 賦予上面的權限給 user russell, host 為 localhost
TO 'russell'@'localhost'
## 密碼為 Rover#My_1st_Dog&Not_Yours!
IDENTIFIED BY 'Rover#My_1st_Dog&Not_Yours!';"
以下的 mysql command 的意思是?
- Example:
mysqladmin -u root -p flush-privileges
- Answer:
當完成一些設定更新後, 下達上面的指令讓設定生效
以下的 mysql command 的意思是?
- Example:
mysql -u root -p -e "SELECT User,Host FROM mysql.user;"
- Answer:
列出所有的 user 以及 host
以下的 mysql command 的意思是?
- Example:
mysql -u root -p -e "SET PASSWORD FOR 'root'@'127.0.0.1' PASSWORD('new_pwd');"
mysql -u root -p -e "SET PASSWORD FOR 'root'@'localhost' PASSWORD('new_pwd');"
mysql -u root -p -e "DROP USER 'root'@'%';"
mysql -u root -p -e "DROP USER ''@'localhost';" - Answer:
1, 2 行給 root 的不同 host 設定新密碼, 儘管 127.0.0.1 等於 localhost, 但也必須分別設定密碼
3,'root'@'%'表示不管從任何 host 都可以 claim 自己是 root, 這樣的設定並不安全, 必須刪除
4,''@'localhost'表示只要是來自 localhost, 任何 username 都被接受, 這樣的設定也不安全, 應該要刪除這樣的 anonymous user
Mysql 中, 如果搜尋的字串是 % 開頭, 那可以用 index 嗎?
不行
Mysql 中, set column type 的特性是?
可指定一個允許輸入值列表, 所有 insert 的值都必須在這列表內才允許輸入, 與 enum 不同之處在於, enum 只允許 insert 一個值, set 允許 insert 零個或多個
如何在已知 root 現有密碼的情況下重新設定 root 密碼?
mysqladmin -u root -p flush-privileges password |
Mysql 中, enum column type 的特性是?
可指定一個允許輸入值列表, 所有 insert 的值都必須在這列表內才允許輸入, 與 enum 不同之處在於, enum 只允許 insert 一個值, set 允許 insert 零個或多個
Mysql 中, date, datetime, timestamp, 三種 data type 差異分別是?
date: yyyy-mm-dd
datetime: yyyy-mm-dd hh:mm:ss
timestamp: yyyy-mm-dd hh:mm:ss 除此之外, timestamp 會將收到的時間轉成 UTC, 當 query 此欄位時, 會再從 UTC 轉成目前時區
Mysql 中, float, double, decimal, 由小至大的排列順序為?
float, double, decimal
Mysql 中, 若要精準的儲存一個數字(含小數點), 建議使用哪個 type?
decimal
Mysql 中, double type 有效位數約為?
17 位
Mysql 中, float type 有效位數約為?
7 位數
Mysqld 通常代表什麼?
MySQL Daemon, 通常代表 MySQL Server
以下的 SQL 語法中的意思是?
- Example:
CREATE INDEX prod_name_ind
ON PRODUCTS (prod_name); - Answer:
建立一個 index, 名為prod_name_ind, table 為 PRODUCTS, 欄位為PROD_NAME
以下的 SQL 語法中的意思是?
Example:
BEGIN TRANSACTION
INSERT INTO Customers(cust_id, cust_name)
VALUES('1000000010', 'Toys Emporium');
SAVE TRANSACTION StartOrder;
INSERT INTO Orders(order_num, order_date, cust_id)
VALUES(20100,'2001/12/1','1000000010');
IF @@ERROR <> 0 ROLLBACK TRANSACTION StartOrder;
INSERT INTO OrderItems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20100, 1, 'BR01', 100, 5.49);
IF @@ERROR <> 0 ROLLBACK TRANSACTION StartOrder;
INSERT INTO OrderItems(order_num, order_item, prod_id, quantity, item_price)
VALUES(20100, 2, 'BR03', 100, 10.99);
IF @@ERROR <> 0 ROLLBACK TRANSACTION StartOrder;
COMMIT TRANSACTIONAnswer:
在第一個 insert 建立一個 savepoint StartOrder, 如果之後的語法失敗, 回到 savepoint
以下的 SQL 語法中的意思是?
- Example:
CREATE VIEW ProductCustomers AS
SELECT cust_name, cust_contact, prod_id
FROM Customers, Orders, OrderItems
WHERE Customers.cust_id = Orders.cust_id
AND OrderItems.order_num = Orders.order_num; - Answer:
建立一個 VIEW, 為一張虛擬的 table, 可藉此簡單化省略重複複雜 SQL 語法
以下的 SQL 語法中的意思是?
- Example:
SELECT *
INTO CustCopy
FROM Customers; - Answer:
從 Customers table 撈出所有 record, 再 insert 到 CustCopy table
以下的 SQL 語法中的意思是?
- Example:
INSERT INTO Customers(cust_id,
cust_contact,
cust_email,
cust_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country)
SELECT cust_id,
cust_contact,
cust_email,
cust_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country
FROM CustNew; - Answer:
從 CustNew table 中 select 出 record, 在 insert 進 Customers table
以下的 SQL 語法中的意思是?
- Example:
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All'
ORDER BY cust_name, cust_contact; - Answer:
只在最後一個 SELECT 使用 ORDER BY, 因為 UNION 會將它用來排序所有 SELECT 語句返回的結果
以下的 SQL 語法中的意思是?
- Example:
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION ALL
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_name = 'Fun4All'; - Answer:
使用 UNION 語法同時執行兩個 query, UNION 默認取消重複的 record, ALL 表示不默認取消
以下的 SQL 語法中的意思是?
- Example:
SELECT cust_name, cust_contact
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id
AND OI.order_num = O.order_num
AND prod_id = 'RGAN01'; - Answer:
使用 AS 來縮短 SQL 語法
以下的 SQL 語法中的意思是?
- Example:
SELECT prod_name, vend_name, prod_price, quantity
FROM OrderItems, Products, Vendors
WHERE Products.vend_id = Vendors.vend_id
AND OrderItems.prod_id = Products.prod_id
AND order_num = 20007; - Answer:
從三個 table 中取出指定的 column, 並指定連結
以下的 SQL 語法會取出多少行的 record?
- Example:
SELECT vend_name, prod_name, prod_price
FROM Vendors, Products; - Answer:
因為沒有指定關聯, 所以共會取出 Vendors 與 Products 行數的相乘
以下的 SQL 語法中的意思是?
- Example:
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM Orders
WHERE Orders.cust_id = Customers.cust_id) AS orders
FROM Customers
ORDER BY cust_name; - Answer:
利用子查詢取得 orders 欄位, 即在 orders table 中, cust_id 跟 Customers table 中的 cust_id 相同
以下的 SQL 語法中, 作為子查詢, 可以 select 多個 column 嗎?
- Example:
SELECT cust_id
FROM Orders
WHERE order_num IN (SELECT order_num
FROM OrderItems
WHERE prod_id = 'RGAN01'); - Answer:
不行
以下的 SQL 語法的意思是?
- Example:
SELECT cust_id
FROM Orders
WHERE order_num IN (SELECT order_num
FROM OrderItems
WHERE prod_id = 'RGAN01'); - Answer:
從子查詢得到的結果來 filter
下面的 select 子句的排列順序是?
- Example
SELECT, FROM, WHERE, GROUP BY, HAVING, ORDER BY - Answer:

SQL 語法中, WHERE 跟 HAVING 差別是?
where 過濾行
having 過濾分組
SQL 語法中, count(*) 會否忽略 NULL 值?
不會
SQL 語法中, 當使用 + 把不同 column 的值串在一起, 卻發現有多餘的空白如下 example, 在 example 2 當中, 該怎麼去掉這些空白呢?
- Example output
-----------------------------------------------------------
Bear Emporium (USA )
Bears R Us (USA )
Doll House Inc. (USA )
Fun and Games (England )
Furball Inc. (USA )
Jouets et ours (France ) - Example 2
SELECT RTRIM(vend_name) + ' (' + 這裡是?(vend_country) + ')'
FROM Vendors
ORDER BY vend_name; - Answer
SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')'
FROM Vendors
ORDER BY vend_name;
SQL 語法中, 如果要把兩個不同 column 的 value 串在一起成一個字串輸出, 如下 example, 該使用什麼符號??
- Example
SELECT vend_name 這裡是? ' (' 這裡是? vend_country 這裡是? ')'
FROM Vendors
ORDER BY vend_name; - Answer
SELECT vend_name + ' (' + vend_country + ')'
FROM Vendors
ORDER BY vend_name;
SQL 語法中, wildcard 是否會耗費比較多的時間?
會的
SQL 語法中, 當使用 wildcard 時, 最好將語法置於開頭處或結尾處?
結尾處
SQL 語法中, 假如我要找出所有名字以 J 或 M 起頭的聯絡人, 在以下的 example 中, 該使用哪個 wildcard?
- Example
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '這裡是?%'
ORDER BY cust_contact; - Answer
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '[JM]%'
ORDER BY cust_contact;
SQL 語法中, % 代表多字 wildcard, 如果我要單個字的 wildcard, 要使用哪個符號?
_, 是一個 word, 不是 character
SQL 語法中, 以下 example 中的語法會撈出 value 為 null 的 row 嗎?
- Example:
SELECT prod_name
FROM Products
WHERE prod_name LIKE '%'; - Answer:
不會
以下的 SQL 語法是什麼意思?
- Example:
SELECT prod_name
FROM Products
LIMIT 5 OFFSET 5; - Answer:
抵銷 5 行, 也就是從第 6 行開始撈
撈 5 行資料
SQL 語法中, 有區分大小寫嗎?
無
SQL 語法中, inner join 跟 join 差在哪?
一樣
SQL 語法中, left outer join 跟 left join 差在哪?
一樣
SQL 語法中, right outer join 跟 right join 差在哪?
一樣
SQL 語法中, join 語法的用途是?
同時撈出兩張表的資料
SQL 語法中, left join 跟 right join 語法的差別是?
left join 除了 join 兩張表有相關的資料外, 還會把左邊表的所有不相關資料也撈出來, right join 則是會把右邊表的所有不相關資料取出
以下的 MySQL example command 的意思是?
- Example:
show variables like 'validate_password%';
- Answer:
顯示密碼驗證相關訊息, 如下# validate_password.check_user_name ON
# validate_password.dictionary_file
# validate_password.length 8
# validate_password.mixed_case_count 1
# validate_password.number_count 1
# validate_password.policy MEDIUM
# validate_password.special_char_count 1
以下的 MySQL example command 的意思是?
- Example:
SELECT user,authentication_string,plugin,host FROM mysql.user;
- Answer:
user: username
authentication_string: 就是 password
plugin: 這邊是 authentication plugin, caching_sha2_password 可在 memory cache 之前使用過的 user, 增進效能
host: 該 user 的 host, username + host 才是一個完整的 user

以下的 MySQL example command 的意思是?
- Example:
ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'password';
FLUSH PRIVILEGES; - Answer:
更改 root 密碼
以下的 MySQL example command 的意思是?
- Example:
set global validate_password_length=3; - Answer:
修改密碼長度規則
以下的 MySQL example command 的意思是?
- Example:
set global validate_password_policy=0; - Answer:
修改密碼驗證原則
以下的 MySQL example command 的意思是?
- Example:
CREATE DATABASE mydatabase CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
- Answer:
建立資料庫 mydatabase, 設定 character set 為 utf8mb4, collate 為 utf8mb4_unicode_ci
以下的 MySQL example command 的意思是?
- Example:
mysql -uroot -pYourPassword -Bse "use test; delete from testTable;" - Answer:
從 shell 不進入 MySQL client 直接下達 command
以下的 MySQL example command 的意思是? - Example: ```
set global log_timestamps = ‘system’;
- **Answer**: |
DROP DATABASE databaseName;
- **Answer**:
刪除資料庫
<br>
## # 參考書目
- [SQL 必知必會](https://www.tenlong.com.tw/products/9787115313980)
- [MySQL 與 MariaDB 學習手冊 (Learning MySQL and MariaDB: Heading in the Right Direction with MySQL and MariaDB)](https://www.tenlong.com.tw/products/9789864763832)
留言