概述
Logs-based metrics (紀錄指標) 是由 Stackdriver Monitoring 提供的, 基於記錄數據內容的指標。 他可以幫你發現動向, 從紀錄中取出數字數據, 還有建立一個特定的指標來完成事件觸發, 這樣當特定的記錄數據出現時, 就可以發出警告。 在 Stackdriver Monitoring 服務中, 你可以同時使用系統提供的指標, 或是使用者自定義的紀錄指標來建立圖表以及警告政策。 紀錄指標是由紀錄的資料產生的時間序列, 在本教程中你將會動手實作上面所提到的。
前言
本篇主要是利用 Google 的 Qwiklab 平台學習的同時,做的一份學習筆記
為避免翻譯誤解,專業術語在本篇將不會被翻譯,保留原文
設定及要求
在你按下 Start Lab 按鈕之前
詳讀所有的教學。Labs 是有時間限制的,而且你不可以停止時間倒數。倒數計時器在你按下 Start Lab 按鈕後開始倒數,上面顯示的時間為你還能使用 Cloud 資源的時間。
Qwiklabs 的手把手環境,讓你可以在真實環境中來操作進行 Qwiklabs 上提供的課程,而不是在一個模擬或是展示的環境。我們透過提供你一個全新的、暫時的帳號密碼,在計時器歸零之前,你可以用來登入並存取 Google Cloud Platform。
你需要什麼?
要完成這個 lab ,你需要:
- 一個一般的網路瀏覽器(推薦 Chrome)
- 完成這個 lab 的時間
備註: 如果你已經有你自己的個人 GCP 帳號或專案,請不要使用在這一個 lab
現在你已經開始你的 lab, 你將會登入 Google Cloud Shell 主控台,然後開啟命令列工具
如何開始你的 lab ,然後登入 Console?
- 按下 Start Lab 按鈕。如果你需要付費,會有一個彈出視窗來讓你選擇付費的方式。在左方你會看到一個面板,上面有暫時的帳號密碼,你必須使用這些帳號密碼在此次 lab

- 複製
username, 然後點擊Open Google Console。 Lab 會開啟另外一個視窗,顯示選擇帳號的頁面
tip: 開啟一個全新的視窗,然後跟原本的頁面並排
- 在
選擇帳號頁面, 點擊Use Another Account

- 登入頁面開啟,貼上之前複製的
username以及password,然後貼上
重要:必須使用之前於 Connection Details 面板 取得的帳號密碼,不要使用你自己的 Qwiklabs 帳號密碼。 如果你有自己的 GCP 帳號,請不要用在這裡(避免產生費用)
- 點擊並通過接下來的頁面:
- 接受
terms以及conditions - 不要增加
recovery optoins或two factor authentication(因為這只是一個臨時帳號) - 不要註冊免費體驗
- 接受
稍待一些時候, GCP 控制台將會在這個視窗開啟。
注意:按下左上方位於Google Cloud Platform 隔壁的 Navigation menu ,你可以瀏覽選單,裡面有一系列的 GCP 產品以及服務

啟動 Google Cloud Shell
Google Cloud Shell 是載有開發工具的虛擬機器。它提供了5GB的 home 資料夾,並且運行在 Google Cloud 上。 Google Cloud Shell 讓你可以利用 command-line 存取 GCP 資源
- 在
GCP 控制台,右上的工具列,點擊Open Cloud Shell按鈕

- 在打開的對話框裡,按下
START CLOUD SHELL:

你可以立即按下 START CLOUD SHELL 當對話視窗打開。
連結並提供環境會需要一點時間。當你連結成功,這代表你已成功獲得授權,且此專案已被設為你的專案ID,例如:

gcloud 是 Google Cloud Platform 的 command-line 工具,他已事先被安裝在 Cloud Shell 並且支援自動補齊
使用這個 command ,你可以列出有效帳戶名稱:
gcloud auth list |
輸出:
Credentialed accounts: |
範例輸出:
Credentialed accounts: |
你可以使用以下 command 來列出專案 ID
gcloud config list project |
輸出:
[core] |
範例輸出:
[core] |
gcloud 的完整文件可以參閱 Google Cloud gcloud Overview
建立本教程所需的資源
本教程中所需的第一個資源是一個產生紀錄的 app。 你將會部署一個 App 到 App Engine, 然後建立一些 url 的運作時間檢查讓 App 紀錄
使用以下的指令來複製 app 的範例到你的 GCP 專案中:
git clone https://github.com/GoogleCloudPlatform/appengine-guestbook-python |
cd appengine-guestbook-python/ |
gcloud app create |
輸入號碼來選擇你希望這個 app 被部署到哪一個 region 的 App Engine
接下來, 執行:
gcloud app deploy --version 1 |
輸入 Y 繼續
gcloud datastore indexes create index.yaml |
輸入 Y 繼續
監控索引 (Monitor indexes)
到主控台的 Datastore > Indexes 。 會需要幾分鐘的時間設定。 使用視窗上方的 “Refresh” 按鈕。 目前的狀態應該會是 “Serving”
準備安裝 Stackdriver Monitoring
當你開始 Qwiklab 上的教程時, 一台虛擬機會自動被建立。 如果你不是使用 Qwiklab, 可以自己建立一台虛擬機。 下一個步驟,你將會需要安裝 monitoring agent (監視代理程式)。 到 Compute Engine > VM instances 準備安裝吧!
建立一個 Stackdriver 工作區
要使用 Stackdriver, 你的專案必須有一個 Stackdriver 帳號。 以下的步驟會建立一個新的 Stackdriver 免費試用帳號
在 Google Cloud Platform 主控台, 點擊 Navigation Menu > Monitoring
當你看到 Stackdriver 的顯示面板, 這代表你的 Stackdriver 工作區已經準備好了在上層的橫幅點擊 Install Agents
從 VM Instance 使用 SSH 到虛擬機裡, 然後執行以下的指令來安裝 Stackdriver 監控代理以及 Stackdriver 紀錄代理
Stackdriver 代理程式
設定 Stackdriver 代理程式
Stackdriver 代理讓你更了解你的基礎設施以及應用。 安裝兩種代理到你想要獲取更多資訊的環境。
監控代理
Stackdriver Monitoring 代理程式是一個以 collectd 為基礎的 Daemon,可從虛擬機器執行個體收集系統與應用程式指標,並將其傳送至 Monitoring。根據預設,Monitoring 代理程式會收集磁碟、CPU、網路與處理程序指標。您可以將 Monitoring 代理程式設定為監控第三方應用程式,以取得代理程式指標的完整清單。
更多資訊
安裝監控代理
curl -sSO https://dl.google.com/cloudagents/install-monitoring-agent.sh |
Logging 代理
在預設設定中,Stackdriver Logging 代理程式會將記錄從常見第三方應用程式與系統軟體串流至 Stackdriver Logging;請參閱預設記錄的清單。您可以設定代理程式,使其串流其他記錄。如要瞭解代理程式設定與作業,請參閱設定 Stackdriver Logging 代理程式一文。
最佳做法是在所有 VM 執行個體上執行 Stackdriver Logging 代理程式。代理程式會在 Linux 與 Windows 下執行。如要安裝 Stackdriver Logging 代理程式,請參閱安裝記錄代理程式一文。
安裝 logging 代理
curl -sSO https://dl.google.com/cloudagents/install-logging-agent.sh |

點擊 Monitoring Overview 回到顯示面板
本教程額外的資源
因為本教程需要使用紀錄, 所以你需要產生一些有趣的紀錄。 本教程將會使用運作時間確認以及 VM 建立來產生紀錄
建立一些運作時間確認
現在你將針對這個目前運作在 App Engine 上的應用, 建立一些運作時間確認。 運作時間確認將會模擬應用載入。 App Engine 將會自動地從所有的請求當中捕捉紀錄, 然後會每分鐘產生紀錄, 所以等等你就會有可以分析的資料了。
回到 GCP 主控台並且點擊 Navigation menu > App Engine 。 點擊右上方的連結, 然後複製你的應用的連結。 你會需要這個來建立一個運行時間確認。

回到 Stackdriver 視窗, 在 Overview 頁面, Uptime Checks 區塊, 點擊 Create Selected Checks 按鈕並且則預設專案 (預設沒勾選), 然後點擊 Create Check
你也可以從左手邊選單的 Uptime Checks 選擇 Uptime Checks Overview , 然後在新視窗點擊 Add Uptime Check
使用以下資訊來編輯 New Uptime Check:
Title: pizza check
Check type: HTTP
Resource Type: URL
Hostname: 貼上我們應用的 URL。 從 URL 中移除掉 https:// 以及結尾的 /
Path: /?food=pizza
Check every: 1 min
點擊 Test 來核對 uptime check 有在正常運作中。 當你看到一個綠色的打勾符號, 這表示有在正確運作中。
點擊 Save
你將會看到如下:

勾選 “Don’t ask again” 方塊匡, 然後點擊 “No thanks” 來跳過 uptime check 的警告政策建立
再建立兩個 uptime check
- 點擊第一個 uptime check 的三個點的圖案, 選擇 “copy”
- 將名稱變更為 “burger check”, 然後改變 path 到 “/?food=burger”
- 再複製 uptime check 一次
- 更名為 “cake check”, 然後 path 變更為 “/?food=cake”
你可以在顯示面板上看到所有增加的 uptime check
系統定義紀錄指標以及使用者定義紀錄指標
紀錄指標又分為系統定義以及使用者自定義
系統定義紀錄指標
系統定義紀錄指標馬上就可以使用, 這些系統定義指標包含:
收到的紀錄的指標
Byte_count: 收到的記錄項目位元組總數。 被細分為監控資源類型, 紀錄串流名稱, 以及嚴重等級。
被排除的紀錄的指標
Excluded_byte_count: 排除的記錄項目位元組總數。 被細分為監控資源類型Excluded_log_entry_count: 排除的記錄項目總數。 被細分為監控資源類型。
紀錄指標的指標
Dropped_log_entry_count: 不要看這個名字這樣, 事實上這個不是被 Stackdriver 放棄的紀錄數據, 而是因為遲到了, 所以未被歸進紀錄指標的紀錄項目總數Log_entry_count: 有被歸進紀錄指標的紀錄項目總數, 所以dropped_log_entry_count+log_entry_count為 Stackdriver Logging 收到的紀錄項目總數Metric_throttled: 顯示數據點是否因為超過時間順序限制而被紀錄指標放棄Time_series_count: 在紀錄指標中, 活躍的時間序列項目總數的估計值
大部分的系統紀錄指標都是計數器指標。 Counter metrics(計數器指標) 計算符合進階紀錄篩選器的記錄數據數量。
現在, 你將更進一步的看看系統產生的紀錄指標: Log_entry_count
在 Stackdriver 主控台, 點擊 Resources > Metrics Explorer:

開始輸入 “GCE”, 然後選擇 “GCE VM Instance” 為你的資源。 指標的話則是輸入 “log” 以及選擇 “Log entries”:

呈現在你眼前的是一台機器的記錄數據圖表, 這台機器從這個教程開始時就開啟了, 是你的眾多資源之一。
使用者定義的紀錄指標
你可以使用已經存在的紀錄來建立你自己的紀錄指標。 他們被稱為使用者定義紀錄指標。 現在你將使用記錄數據來建立一個指標。
在 Stackdriver 主控台, 從左側選單點擊 Logging

現在你已經在紀錄頁面, 在這裡你可以篩選結果
在第一個下拉選單選擇 GCE VM Instance 然後在第二個下拉選單選擇 cloudaudit.googleapis.com/activity , 然後點擊 OK

在其中一筆數據點擊 “insert” 標籤, 然後選擇 Show matching entries

進階篩選器現在已經被啟動並且顯示這個指標的標準
第三行的 protoPayload.methodName 讓你可以經由很多方式來篩選, 更多資訊可以參考這裏

在螢幕上方點擊 Create Metrics
在指標編輯器將你的指標命名為 “newVM” , 然後點擊 Create Metric
你將可以看到你的使用者自定義紀錄指標被加到紀錄指標頁面

針對 VM 建立指標建立警告政策
現在你將建立一個警告, 當一個新的 VM 被加到專案時, 你會收到提醒
在 Stackdriver 主控台, 重整螢幕, 然後點擊 Alerting > Create a Policy
加入以下資訊:
Condition: 點擊 **Add Condition。 開始輸入 “logging” 以及將 Resource Type 更新為 “logging/user/newVM”, 以及 Condition 設為 “is above” 0 For 1 minute 。 現在點擊 Save
Notification: 將你的個人信箱加到 email 欄位, 你才能收到 email 通知
Name this Policy: 輸入 “New Virtual Machine”
點擊 Save
建立一台新的機器
現在讓我們來觸發剛剛建立的警告, 建立一台新的機器吧!
在 GCP 主控台的顯示面板, 到 Navigation menu > Compute Engine > VM instances , 然後在螢幕上方點擊 Create Instance
將你的虛擬機取名為 “instance2”, 然後在允許 HTTP 以及 HTTPs 流量的框框打勾。 剩下的都預設值即可。
點擊 Create
等待幾分鐘讓機器啟動。 3~5 分鐘內, 你應會在 Stackdriver 主控台看到一個事件。
繼續本教程, 我們可以在最後確認結果
標籤 (Labels) 以及使用者自定義指標 (user defined metrics)
當你建立指標時, 使用者自定義標籤可以被建立。 每一個配置的標籤都需要一個提取器表達式來告訴 Stackdriver Logging, 如何從紀錄中提取數據, 並且將他們置於標籤數據。 你無法在系統定義指標中加入標籤。
現在你將建立一個含有標籤的使用者定義指標
在 Stackdriver 視窗頁面, 點擊 Logging
篩選紀錄為 GAE Application 以及 appengine.googleapis.com/request_log > OK

在螢幕上方點擊 Create Metric
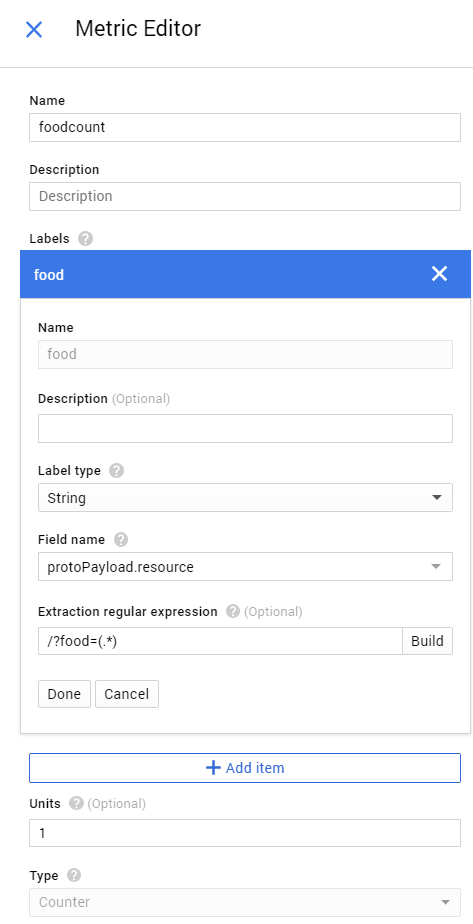
將指標命名為 “Foodcount”, 然後如果你想要的話也可以加入敘述
再來點擊 Add item 來建立一個標籤

標籤
Labels 讓紀錄指標可以含有多個時間序列 - 每一個標籤值。 所有的紀錄指標都有一些預設的標籤。
在本教程中, 你將會建立一個指標, 條件為當一個 uptime check 的紀錄產生, 且這個紀錄含有 “food” 標籤
如果你還沒完成這件事情, 點擊 Add Item
填入以下資訊:
- Name: foods
- Label Type: String
- Field Name: search for “resource” and choose “protoPayload.resource”
- 點擊 Build 按鈕, 然後輸入表達式:
/?food=(.*) - 點擊 Done
注意: 要確定你有仔細的設定好標籤值提取器。 一個錯誤可能會導致很大量的活躍時間序列。 超過時間序列限制會導致指標被限制住, 圖表表現下降, 以及額外的時間序列超時成本
點擊 Create Metric
現在你將會看到你的使用者定義指標被加到紀錄指標的畫面

建立 Foodcount 警告政策
現在你將建立一個 Foodcount 的警告政策, 就是那個你剛建立的指標
在 Stackdriver 主控台, 重整螢幕, 然後點擊 Alerting > Create a Policy

你也可以從 Google Cloud 主控台, 到 Stackdriver 區塊然後點擊 Logging , 然後一樣照著上面的動作來建立
設定以下的條件:
條件: 點擊 Add Condition 。 在 Find Resource 欄位輸入 “logging/user/“ 然後選擇 “logging/user/Foodcount” 。 門檻為 0 以及 1 分鐘, 然後 save
通知: 輸入你的個人信箱到 email 欄位來接收 email 通知
命名這個政策: 輸入 “food alert”
點擊 save
當下一輪的 uptime check 發生, 門檻一定會高於 1 分鐘, 所以警告會被觸發, 且你將會看到一個事件出現在 Monitoring Overview 頁面
分布 (Distribution) 以及延遲 (latency) 指標
分佈指標 從符合篩選的數據中累積數字資料。 指標含有一個 Distribution 物件的時間序列, 每一個都含有以下的東西:
- 在分佈中, 數值的數量累積
- 數值的平均
- 偏差值平方的總和
- 一組直方 buckets 以及 每個 bucket 中都有數值的總和。 你可以使用預設的 bucket 設計, 或是選擇你自己想要的
一個分佈指標常見的使用情境是追蹤延遲。 當接收到每一筆記錄數據, 延遲值會從記錄數據中被取出, 並且加到分佈中。 在規律的間隔下, 累積的分佈被寫到 Stackdriver Monitoring。 接下來你將建立一個追蹤延遲的指標
到 Logs-based Metric 視窗
在 Logs Viewer 控制列上, 在你的指標, 你可以建立一個只會計算你想要的記錄數據的篩選器。
在頁面上方, 點擊 Create Metric
在 Metric Editor 控制列, 填入以下欄位
- Name: AppLatency
- 將 Type 變更為 “Distribution”
- Field name 為 “latency”, 並選擇 “protoPayload.latency”
點擊 Create Metric
你的新指標出現在 Logs Viewer 指標的列表中, 並且立即出現在相關的 Stackdriver Monitoring 選單
在紀錄指標頁面, 點擊 AppLatency 指標旁的三個小點圖案, 然後選擇 **View in Metrics Explorer 來檢視分佈指標的結果。 你可能需要重整 Stackdriver 的頁面

在圖表上方的下方選單改變圖表的風格為 heatmap

Metric Explorer 的結果大概會需要 3~5 分鐘。 你可以一些時候再回到這個頁面來核對結果
你也可以從 Stackdriver 主控台, 到 Resources > Metrics Explorer 輸入你的指標名稱
heatmap 客製顯示面板
建立一個客製的面板來顯示特定的指標是一個檢視資料很好的方式。 接下來你會建立一個客製面板來顯示你方才使用的延遲指標
在 Stackdriver 主控台, 點擊 Dashboard > Create Dashboard , 然在右手邊點擊 Add Chart
Resource type: GAE Application
Metric: Response latency
圖表將會以你使用的指標自我命名, 你可以將他更名為任何你想要的 - 在這個範例中為 “Heatmap”
在螢幕下方點擊 Save
面板需要一個名字 - 點擊 Untitled 然後命名它為 “App Response”

確認警告事件
回到 Stackdriver 的 Monitoring Overview 檢視 uptime check 政策的警告。 你也可以回到 Resource 頁面的 Metrics Explorer
點擊 Alerting > Policies overview, 然後點擊政策的名字來更清楚的檢視 newVM 警告。 因為問題已經自我解決了, 點擊 Resolved 視窗, 然後你可以看到 new VM 發生的事件通知
如果你有設定任何 email 通知, 收信並確認核對收到的警告。 這個可能會花更久的時間, 但沒關係, 就算這個教程結束了, 你還是可以收到。

別忘了點擊 Metrics Explorer 視窗並重整頁面來檢視 heatmap
恭喜!
你已經完成本教程!
留言