前言
這是一份未整理過的 Linux 學習筆記
OS 系統為 GCP 上的 Linux 18.04 LTS
內容參考出處:
- 鳥哥的 Linux 的私房菜
- Internet
find
搜尋屬於特定 user 或 group 的檔案
find localtion -type f -user userName -group groupName -name fileName |
搜尋屬於特定 user 或 group 的資料夾
find localtion -type d -user userName -group groupName -name fileName |
搜尋 $分鐘內的檔案或資料夾, 只搜尋當層
find ./* -maxdepth 0 -type f -cmin -20 |
ps
- 列出系統正在執行的 process, 並且從中搜尋關鍵字
ps -ef | node
kill
語法
[root@study ~]# kill -signal %jobnumber |
代號 | 名稱 | 內容
—-|—–|
1 | SIGHUP | 啟動被終止的程序,可讓該 PID 重新讀取自己的配置文件,類似重新啟動
2 | SIGINT | 相當於用鍵盤輸入 [ctrl]-c 來中斷一個程序的進行
9 | SIGKILL | 代表強制中斷一個程序的進行,如果該程序進行到一半, 那麼尚未完成的部分可能會有“半產品”產生,類似 vim會有 .filename.swp 保留下來。
15 | SIGTERM | 以正常的結束程序來終止該程序。由於是正常的終止, 所以後續的動作會將他完成。不過,如果該程序已經發生問題,就是無法使用正常的方法終止時, 輸入這個 signal 也是沒有用的。
19 | SIGSTOP | 相當於用鍵盤輸入 [ctrl]-z 來暫停一個程序的進行
指令
- 立刻強制刪除一個工作
kill -9 processID
killall
語法
[root@study ~]# killall [-iIe] [command name] |
ln
- 建立一個捷徑
ln -s sourceAbsoluteLink targetAbsoluteLink
du
- 查檔案大小
du -sh fileOrFolder
df
- 查硬碟空間使用率
df -h
[[]]
- 回傳 true or false
[[ -f /.dockerenv ]]
[[]]會將裡頭的參數結果回傳 true or false-f表示file exists
所以意思是,如果 /.dockerenv 存在,則回傳 true
grep
- 搜尋內容並顯示附近的行數
從gcloudcommand 中取得資料,並且顯示ssh-keys後面的 5 行gcloud compute project-info describe | grep -A 5 ssh-keys
groupdel
- 刪除 group
groupdel groupName
userdel
- 刪除 user
userdel userName
useradd
useradd [-u UID] [-g 初始群組] [-G 次要群組] [-mM]\ |
完全參考默認值創建一個使用者,名稱為 Ray
useradd Ray
建立一個 user, 並加到指定 group
useradd -G groupName userName
useradd 之後,系統會幫我們做哪些事?
- 在 /etc/passwd 裡面創建一行與帳號相關的數據,包括創建 UID/GID/主文件夾等;
- 在 /etc/shadow 裡面將此帳號的密碼相關參數填入,但是尚未有密碼;
- 在 /etc/group 裡面加入一個與帳號名稱一模一樣的群組名稱;
- 在 /home 下面創建一個與帳號同名的目錄作為使用者主文件夾,且權限為 700
useradd 參考檔
- 這個數據其實是由 /etc/default/useradd 調用出來的
useradd -D |
- GROUP=100:新建帳號的初始群組使用 GID 為 100 者
系統上面 GID 為 100 者即是 users 這個群組,此設置項目指的就是讓新設使用者帳號的初始群組為 users 這一個的意思。 但是我們知道 CentOS 上面並不是這樣的,在 CentOS 上面默認的群組為與帳號名相同的群組。 舉例來說, vbird1 的初始群組為 vbird1 。怎麼會這樣啊?這是因為針對群組的角度有兩種不同的機制所致, 這兩種機制分別是:- 私有群組機制:
系統會創建一個與帳號一樣的群組給使用者作為初始群組。 這種群組的設置機制會比較有保密性,這是因為使用者都有自己的群組,而且主文件夾權限將會設置為 700 (僅有自己可進入自己的主文件夾) 之故。使用這種機制將不會參考 GROUP=100 這個設置值。代表性的 distributions 有 RHEL, Fedora, CentOS 等; - 公共群組機制:
就是以 GROUP=100 這個設置值作為新建帳號的初始群組,因此每個帳號都屬於 users 這個群組, 且默認主文件夾通常的權限會是“ drwxr-xr-x … username users … ”,由於每個帳號都屬於 users 群組,因此大家都可以互相分享主文件夾內的數據之故。代表 distributions 如 SuSE等。
由於我們的 CentOS 使用私有群組機制,因此這個設置項目是不會生效的!不要太緊張啊!
- 私有群組機制:
- HOME=/home:使用者主文件夾的基準目錄(basedir)
使用者的主文件夾通常是與帳號同名的目錄,這個目錄將會擺放在此設置值的目錄後。所以 vbird1 的主文件夾就會在 /home/vbird1/ 了!很容易理解吧! - INACTIVE=-1:密碼過期後是否會失效的設置值
我們在 shadow 文件結構當中談過,第七個字段的設置值將會影響到密碼過期後, 在多久時間內還可使用舊密碼登陸。這個項目就是在指定該日數啦!如果是 0 代表密碼過期立刻失效, 如果是 -1 則是代表密碼永遠不會失效,如果是數字,如 30 ,則代表過期 30 天后才失效。 - EXPIRE=:帳號失效的日期
就是 shadow 內的第八字段,你可以直接設置帳號在哪個日期後就直接失效,而不理會密碼的問題。 通常不會設置此項目,但如果是付費的會員制系統,或許這個字段可以設置喔! - SHELL=/bin/bash:默認使用的 shell 程序文件名
系統默認的 shell 就寫在這裡。假如你的系統為 mail server ,你希望每個帳號都只能使用 email 的收發信件功能, 而不許使用者登陸系統取得 shell ,那麼可以將這裡設置為 /sbin/nologin ,如此一來,新建的使用者默認就無法登陸! 也免去後續使用 usermod 進行修改的手續! - SKEL=/etc/skel:使用者主文件夾參考基準目錄
這個咚咚就是指定使用者主文件夾的參考基準目錄囉~舉我們的範例一為例, vbird1 主文件夾 /home/vbird1 內的各項數據,都是由 /etc/skel 所複製過去的~所以呢,未來如果我想要讓新增使用者時,該使用者的環境變量 ~/.bashrc 就設置妥當的話,您可以到 /etc/skel/.bashrc 去編輯一下,也可以創建 /etc/skel/www 這個目錄,那麼未來新增使用者後,在他的主文件夾下就會有 www 那個目錄了!這樣瞭呼? - CREATE_MAIL_SPOOL=yes:創建使用者的 mailbox
你可以使用“ ll /var/spool/mail/vbird1 ”看一下,會發現有這個文件的存在喔!這就是使用者的郵件信箱!
UID/GID 還有密碼參數
- 路徑
/etc/login.defs
MAIL_DIR /var/spool/mail <==使用者默認郵件信箱放置目錄
PASS_MAX_DAYS 99999 <==/etc/shadow 內的第 5 欄,多久需變更密碼日數 |
mailbox 所在目錄:
使用者的默認 mailbox 文件放置的目錄在 /var/spool/mail,所以 vbird1 的 mailbox 就是在 /var/spool/mail/vbird1 囉!shadow 密碼第 4, 5, 6 字段內容:
通過 PASS_MAX_DAYS 等等設置值來指定的!所以你知道為何默認的 /etc/shadow 內每一行都會有“ 0:99999:7 ”的存在了嗎?^_^!不過要注意的是,由於目前我們登陸時改用 PAM 模塊來進行密碼檢驗,所以那個 PASS_MIN_LEN 是失效的!UID/GID 指定數值:
雖然 Linux 核心支持的帳號可高達 232 這麼多個,不過一部主機要作出這麼多帳號在管理上也是很麻煩的! 所以在這裡就針對 UID/GID 的範圍進行規範就是了。上表中的 UID_MIN 指的就是可登陸系統的一般帳號的最小 UID ,至於 UID_MAX 則是最大 UID 之意。
要注意的是,系統給予一個帳號 UID 時,他是 (1)先參考 UID_MIN 設置值取得最小數值; (2)由 /etc/passwd 搜尋最大的 UID 數值, 將 (1) 與 (2) 相比,找出最大的那個再加一就是新帳號的 UID 了。我們上面已經作出 UID 為 1500 的 vbird2 , 如果再使用“ useradd vbird4 ”時,你猜 vbird4 的 UID 會是多少?答案是: 1501 。 所以中間的 1004~1499 的號碼就空下來啦!
而如果我是想要創建系統用的帳號,所以使用 useradd -r sysaccount 這個 -r 的選項時,就會找“比 201 大但比 1000 小的最大的 UID ”就是了。 ^_^
使用者主文件夾設置值:
為何我們系統默認會幫使用者創建主文件夾?就是這個“CREATE_HOME = yes”的設置值啦!這個設置值會讓你在使用 useradd 時, 主動加入“ -m ”這個產生主文件夾的選項啊!如果不想要創建使用者主文件夾,就只能強制加上“ -M ”的選項在 useradd 指令執行時啦!至於創建主文件夾的權限設置呢?就通過 umask 這個設置值啊!因為是 077 的默認設置,因此使用者主文件夾默認權限才會是“ drwx—— ”哩!使用者刪除與密碼設置值:
使用“USERGROUPS_ENAB yes”這個設置值的功能是: 如果使用 userdel 去刪除一個帳號時,且該帳號所屬的初始群組已經沒有人隸屬於該群組了, 那麼就刪除掉該群組,舉例來說,我們剛剛有創建 vbird4 這個帳號,他會主動創建 vbird4 這個群組。 若 vbird4 這個群組並沒有其他帳號將他加入支持的情況下,若使用 userdel vbird4 時,該群組也會被刪除的意思。 至於“ENCRYPT_METHOD SHA512”則表示使用 SHA512 來加密密碼明文,而不使用舊式的 MD5。
現在你知道啦,使用 useradd 這支程序在創建 Linux 上的帳號時,至少會參考:
/etc/default/useradd
/etc/login.defs
/etc/skel/*
usermod
usermod [-cdegGlsuLU] username |
- 增加指定 user 的次要群組
usermod -a -G groupName userName
chmod
- 給予一個資料夾 SGID 屬性
chmod 2777 folderName
passwd
passwd [--stdin] [帳號名稱] <==所有人均可使用來改自己的密碼 |
確認 OS 種類以及版本
使用
lsb_release, 如果沒安裝的話,安裝它sudo apt-get install lsb-release
查詢用法
lsb_release --help輸出如下:
-h, --help show this help message and exit
-v, --version show LSB modules this system supports
-i, --id show distributor ID
-d, --description show description of this distribution
-r, --release show release number of this distribution
-c, --codename show code name of this distribution
-a, --all show all of the above information
-s, --short show requested information in short format根據上面的資訊,想查詢明細的話
lsb_release -a
curl
語法
curl [options] [URL...] |
範例
假設請求如下:
curl -X POST \ |
-X代表 request 的方式ip請由此查詢-H代表 header-d代表傳送資料,等同於以Content-Type: application/x-www-form-urlencoded方式傳送-k若經由https發請求,需加上-k-v代表verbose, 若要顯示回覆訊息,需加上-v
bash 環境配置文件
bash 會根據有沒有登入來讀取相對應的環境配置文件
- login shell
/etc/profile/etc/profile.d/*.sh- 被調用的條件如下:
- 在 /etc/profile.d/ 這個目錄內
- 擴展名為 .sh
- 使用者能夠具有 r 的權限
~/.bash_profileor~/.bash_loginor~/.profile(照順序讀,只會讀其中一個)~/.bashrc(最終會讀取這一個文件)
- non-login shell
~/.bashrcetc/bashrc(會調用此文件)
流程圖

不小心刪除了 ~/.bashrc, 或是沒有這個文件,想創建怎麼辦?
複製預設文件
cp /etc/skel/.bashrc ~/視需求修改
使立即生效
source ~/.bashrc
or
. ~/.bashrc |
Base 64 decode
base64 --decode /tmp/encoded.txt > /tmp/decoded.txt |
ncftp
ncftpput -u account -p password -P port -m -R ipOrDomain remoteLocation locationFileOrDirectory |
- -u:指定登錄FTP服務器時使用的用戶名;
- -p:指定登錄FTP服務器時使用的密碼;
- -P:如果FTP服務器沒有使用默認的TCP協議的21端口,則使用此選項指定FTP服務器的端口號。
- -m:在傳之前嘗試在目錄位置創建目錄(用於傳目錄的情況)
- -R:遞規傳子目錄
ufw
啟用防火牆服務
ufw enable關閉防火牆服務
ufw disable打開指定 port
ufw allow port/tcp
install
使用 install 指令,我們可以在創立一個 folder 或 file 的同時,指定 owner, group 以及 mode
install -d -o <user> -g <group> -m <mode> <path>-d: directory-o: owner-g: group-m: mode
建立一個資料夾,並給予權限
install -d -o ray -g ray -m 2770 /tmp/ray
建立一個檔案,並給予權限
install -m 777 -o ray -g ray /dev/null filename.txt
yum
whatprovides
- 找出有提供特定 command 的 package
yum whatprovides */commandYouAreLookingFor
install
- 安裝特定的 package
yum insatll packageName
regular expression (regex) (正則表達式)
特殊符號表
| 特殊符號 | 代表意義 |
|---|---|
| [:alnum:] | 代表英文大小寫字符及數字,亦即 0-9, A-Z, a-z |
| [:alpha:] | 代表任何英文大小寫字符,亦即 A-Z, a-z |
| [:blank:] | 代表空白鍵與 [Tab] 按鍵兩者 |
| [:cntrl:] | 代表鍵盤上面的控制按鍵,亦即包括 CR, LF, Tab, Del.. 等等 |
| [:digit:] | 代表數字而已,亦即 0-9 |
| [:graph:] | 除了空白字符 (空白鍵與 [Tab] 按鍵) 外的其他所有按鍵 |
| [:lower:] | 代表小寫字符,亦即 a-z |
| [:print:] | 代表任何可以被打印出來的字符 |
| [:punct:] | 代表標點符號 (punctuation symbol),亦即:” ‘ ? ! ; : # $… |
| [:upper:] | 代表大寫字符,亦即 A-Z |
| [:space:] | 任何會產生空白的字符,包括空白鍵, [Tab], CR 等等 |
| [:xdigit:] | 代表 16 進位的數字類型,因此包括: 0-9, A-F, a-f 的數字與字符 |
表達式彙整
| 字元 | 描述 |
|---|---|
| \ | 將下一個字元標記為一個特殊字元(File Format Escape,見本表)、或一個原義字元(Identity Escape,有 ^ $ ( ) * + ? . [ \ { | 共計12個)、或一個向後參照(backreferences)、或一個八進位跳脫符。例如,「n」匹配字元「n」。「\n」匹配一個換行符。序列「\」匹配「\」而「(」則匹配「(」。 |
| ^ | 匹配輸入字串的開始位置。如果設定了RegExp物件的Multiline屬性,^也匹配「\n」或「\r」之後的位置。 |
| $ | 匹配輸入字串的結束位置。如果設定了RegExp物件的Multiline屬性,$也匹配「\n」或「\r」之前的位置。 |
| * | 匹配前面的子表達式零次或多次。例如,zo能匹配「z」、「zo」以及「zoo」。等價於{0,}。 |
| + | 匹配前面的子表達式一次或多次。例如,「zo+」能匹配「zo」以及「zoo」,但不能匹配「z」。+等價於{1,}。 |
| ? | 匹配前面的子表達式零次或一次。例如,「do(es)?」可以匹配「does」中的「do」和「does」。?等價於{0,1}。 |
| {n} | n是一個非負整數。匹配確定的n次。例如,「o{2}」不能匹配「Bob」中的「o」,但是能匹配「food」中的兩個o。 |
| {n,} | n是一個非負整數。至少匹配n次。例如,「o{2,}」不能匹配「Bob」中的「o」,但能匹配「foooood」中的所有o。「o{1,}」等價於「o+」。「o{0,}」則等價於「o*」。 |
| {n,m} | m和n均為非負整數,其中n<=m。最少匹配n次且最多匹配m次。例如,「o{1,3}」將匹配「fooooood」中的前三個o。「o{0,1}」等價於「o?」。請注意在逗號和兩個數之間不能有空格。 |
| ? | 非貪心量化(Non-greedy quantifiers):當該字元緊跟在任何一個其他重複修飾詞(*,+,?,{n},{n,},{n,m})後面時,匹配模式是非貪婪的。非貪婪模式儘可能少的匹配所搜尋的字串,而預設的貪婪模式則儘可能多的匹配所搜尋的字串。例如,對於字串「oooo」,「o+?」將匹配單個「o」,而「o+」將匹配所有「o」。 |
| . | 匹配除「\r」「\n」之外的任何單個字元。要匹配包括「\r」「\n」在內的任何字元,請使用像「(.|\r|\n)」的模式。 |
| (pattern) | 匹配pattern並取得這一匹配的子字串。該子字串用於向後參照。所取得的匹配可以從產生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中則使用$0…$9屬性。要匹配圓括號字元,請使用「(」或「)」。可帶數量字尾。 |
| (?:pattern) | 匹配pattern但不取得匹配的子字串(shy groups),也就是說這是一個非取得匹配,不儲存匹配的子字串用於向後參照。這在使用或字元「(|)」來組合一個模式的各個部分是很有用。例如「industr(?:y|ies)」就是一個比「industry|industries」更簡略的表達式。 |
| (?=pattern) | 正向肯定預查(look ahead positive assert),在任何匹配pattern的字串開始處匹配尋找字串。這是一個非取得匹配,也就是說,該匹配不需要取得供以後使用。例如,「Windows(?=95|98|NT|2000)」能匹配「Windows2000」中的「Windows」,但不能匹配「Windows3.1」中的「Windows」。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始。 |
| (?!pattern) | 正向否定預查(negative assert),在任何不匹配pattern的字串開始處匹配尋找字串。這是一個非取得匹配,也就是說,該匹配不需要取得供以後使用。例如「Windows(?!95|98|NT|2000)」能匹配「Windows3.1」中的「Windows」,但不能匹配「Windows2000」中的「Windows」。預查不消耗字元,也就是說,在一個匹配發生後,在最後一次匹配之後立即開始下一次匹配的搜尋,而不是從包含預查的字元之後開始 |
| (?<=pattern) | 反向(look behind)肯定預查,與正向肯定預查類似,只是方向相反。例如,「(?<=95|98 | NT|2000)Windows」能匹配「2000Windows」中的「Windows」,但不能匹配「3.1Windows」中的「Windows」。 |
| (?<!pattern) | 反向否定預查,與正向否定預查類似,只是方向相反。例如「(?<!95 |98|NT|2000)Windows」能匹配「3.1Windows」中的「Windows」,但不能匹配「2000Windows」中的「Windows」。x|y 沒有包圍在()里,其範圍是整個正規表示式。例如,「z|food」能匹配「z」或「food」。「(?:z|f)ood」則匹配「zood」或「food」。 |
| [xyz] | 字元集合(character class)。匹配所包含的任意一個字元。例如,「[abc]」可以匹配「plain」中的「a」。特殊字元僅有反斜線\保持特殊含義,用於跳脫字元。其它特殊字元如星號、加號、各種括號等均作為普通字元。脫字元^如果出現在首位則表示負值字元集合;如果出現在字串中間就僅作為普通字元。連字元 - 如果出現在字串中間表示字元範圍描述;如果如果出現在首位(或末尾)則僅作為普通字元。右方括號應跳脫出現,也可以作為首位字元出現。 |
| [^xyz] | 排除型字元集合(negated character classes)。匹配未列出的任意字元。例如,「[^abc]」可以匹配「plain」中的「plin」。 |
| [a-z] | 字元範圍。匹配指定範圍內的任意字元。例如,「[a-z]」可以匹配「a」到「z」範圍內的任意小寫字母字元。 |
| [^a-z] | 排除型的字元範圍。匹配任何不在指定範圍內的任意字元。例如,「[^a-z]」可以匹配任何不在「a」到「z」範圍內的任意字元。 |
| [:name:] | 增加命名字元類(named character class)[註 1]中的字元到表達式。只能用於方括號表達式。 |
| [=elt=] | 增加目前locale下排序(collate)等價於字元「elt」的元素。例如,[=a=]可能會增加ä、á、à、ă、ắ、ằ、ẵ、ẳ、â、ấ、ầ、ẫ、ẩ、ǎ、å、ǻ、ä、ǟ、ã、ȧ、ǡ、ą、ā、ả、ȁ、ȃ、ạ、ặ、ậ、ḁ、ⱥ、ᶏ、ɐ、ɑ 。只能用於方括號表達式。 |
| [.elt.] | 增加排序元素(collation element)elt到表達式中。這是因為某些排序元素由多個字元組成。例如,29個字母表的西班牙語, “CH”作為單個字母排在字母C之後,因此會產生如此排序「cinco, credo, chispa」。只能用於方括號表達式。 |
| \b | 匹配一個單詞邊界,也就是指單詞和空格間的位置。例如,「er\b」可以匹配「never」中的「er」,但不能匹配「verb」中的「er」。 |
| \B | 匹配非單詞邊界。「er\B」能匹配「verb」中的「er」,但不能匹配「never」中的「er」。 |
| \cx | 匹配由x指明的控制字元。x的值必須為A-Z或a-z之一。否則,將c視為一個原義的「c」字元。控制字元的值等於x的值最低5位元(即對3210進位的餘數)。例如,\cM匹配一個Control-M或回車字元。\ca等效於\u0001, \cb等效於\u0| 002, 等等… |
| \d | 匹配一個數字字元。等價於[0-9]。注意Unicode正規表示式會匹配全形數字字元。 |
| \D | 匹配一個非數字字元。等價於[^0-9]。 |
| \f | 匹配一個換頁符。等價於\x0c和\cL。 |
| \n | 匹配一個換行符。等價於\x0a和\cJ。 |
| \r | 匹配一個回車字元。等價於\x0d和\cM。 |
| \s | 匹配任何空白字元,包括空格、制表符、換頁符等等。等價於[ \f\n\r\t\v]。注意Unicode正規表示式會匹配全形空格符。 |
| \S | 匹配任何非空白字元。等價於[^ \f\n\r\t\v]。 |
| \t | 匹配一個制表符。等價於\x09和\cI。 |
| \v | 匹配一個垂直制表符。等價於\x0b和\cK。 |
| \w | 匹配包括底線的任何單詞字元。等價於「[A-Za-z0-9_]」。注意Unicode正規表示式會匹配中文字元。 |
| \W | 匹配任何非單詞字元。等價於「[^A-Za-z0-9_]」。 |
| \xnn | 十六進位跳脫字元序列。匹配兩個十六進位數字nn表示的字元。例如,「\x41」匹配「A」。「\x041」則等價於「\x04&1」。正規表達式中可以使用ASCII編碼。. |
| \num | 向後參照(back-reference)一個子字串(substring),該子字串與正規表示式的第num個用括號圍起來的捕捉群(capture group)子表達式(subexpression)匹配。其中num是從1開始的十進位正整數,其上限可能是9[註 2]、31[註 3]、99甚至無限[註 4]。例如:「(.)\1」匹配兩個連續的相同字元。 |
| \n | 標識一個八進位跳脫值或一個向後參照。如果\n之前至少n個取得的子表達式,則n為向後參照。否則,如果n為八進位數字(0-7),則n為一個八進位跳脫值。 |
| \nm | 3位八進位數字,標識一個八進位跳脫值或一個向後參照。如果\nm之前至少有nm個獲得子表達式,則nm為向後參照。如果\nm之前至少有n個取得,則n為一個後跟文字m的向後參照。如果前面的條件都不滿足,若n和m均為八進位數字(0-7),則\nm將匹配八進位跳脫值nm。 |
| \nml | 如果n為八進位數字(0-3),且m和l均為八進位數字(0-7),則匹配八進位跳脫值nml。 |
| \un | Unicode跳脫字元序列。其中n是一個用四個十六進位數字表示的Unicode字元。例如,\u00A9匹配著作權符號(©)。 |
基礎正規表達式字符彙整
| RE 字符 | 意義與範例 |
|---|---|
^word |
意義:待搜尋的字串(word)在行首! 範例:搜尋行首為 # 開始的那一行,並列出行號 grep -n '^#' regular_express.txt |
word$ |
意義:待搜尋的字串(word)在行尾! 範例:將行尾為 ! 的那一行打印出來,並列出行號 grep -n '!$' regular_express.txt |
| . | 意義:代表“一定有一個任意字符”的字符! 範例:搜尋的字串可以是 (eve) (eae) (eee) (e e), 但不能僅有 (ee) !亦即 e 與 e 中間“一定”僅有一個字符,而空白字符也是字符! grep -n 'e.e' regular_express.txt |
| \ | 意義:跳脫字符,將特殊符號的特殊意義去除! 範例:搜尋含有單引號 ‘ 的那一行! grep -n \' regular_express.txt |
| * | 意義:重複零個到無窮多個的前一個 RE 字符 範例:找出含有 (es) (ess) (esss) 等等的字串,注意,因為 * 可以是 0 個,所以 es 也是符合帶搜尋字串。另外,因為 * 為重複“前一個 RE 字符”的符號, 因此,在 * 之前必須要緊接著一個 RE 字符喔!例如任意字符則為 “.*” ! grep -n 'ess*' regular_express.txt |
| [list] | 意義:字符集合的 RE 字符,裡面列出想要擷取的字符! 範例:搜尋含有 (gl) 或 (gd) 的那一行,需要特別留意的是,在 [] 當中“謹代表一個待搜尋的字符”, 例如“ a[afl]y ”代表搜尋的字串可以是 aay, afy, aly 即 [afl] 代表 a 或 f 或 l 的意思! grep -n 'g[ld]' regular_express.txt |
| [n1-n2] | 意義:字符集合的 RE 字符,裡面列出想要擷取的字符範圍! 範例:搜尋含有任意數字的那一行!需特別留意,在字符集合 [] 中的減號 - 是有特殊意義的,他代表兩個字符之間的所有連續字符!但這個連續與否與 ASCII 編碼有關,因此,你的編碼需要設置正確(在 bash 當中,需要確定 LANG 與 LANGUAGE 的變量是否正確!) 例如所有大寫字符則為 [A-Z] grep -n '[A-Z]' regular_express.txt |
| [^list] | 意義:字符集合的 RE 字符,裡面列出不要的字串或範圍! 範例:搜尋的字串可以是 (oog) (ood) 但不能是 (oot) ,那個 ^ 在 [] 內時,代表的意義是“反向選擇”的意思。 例如,我不要大寫字符,則為 [^A-Z]。但是,需要特別注意的是,如果以 grep -n [^A-Z] regular_express.txt 來搜尋,卻發現該文件內的所有行都被列出,為什麼?因為這個 [^A-Z] 是“非大寫字符”的意思, 因為每一行均有非大寫字符,例如第一行的 “Open Source” 就有 p,e,n,o…. 等等的小寫字 grep -n 'oo[^t]' regular_express.txt |
| {n,m} | 意義:連續 n 到 m 個的“前一個 RE 字符” 意義:若為 {n} 則是連續 n 個的前一個 RE 字符, 意義:若是 {n,} 則是連續 n 個以上的前一個 RE 字符! 範例:在 g 與 g 之間有 2 個到 3 個的 o 存在的字串,亦即 (goog)(gooog) grep -n 'go\{2,3\}g' regular_express.txt |
範例
驗證密碼
條件如下:
- 8~16字元
- 至少一個數字
- 至少一個小寫英文字母 或 大寫英文字母
- 至少要有一個特殊符號, 特殊符號限制在 @$%^& 這些當中, 不然可能會出現 ∆©ƒ 這種符號, 使用者想像力無限
正則如下:
^(?=.*[a-z]|.*[A-Z])(?=.*[\d])(?=.*[\W])[\w@$%\^&]{8,16}$ |
- 第一個規則為 lookahead, 目標搜尋至少一個大寫字母或小寫字母, 因為前面加了
.*, 所以就算 lookahead 的前面是空的也沒關係, 從起始處開始往後搜尋, 需符合第一個 lookahead?=之後的規則, 若沒找到則停止, 找到則繼續下一個規則 - 開始第二個 lookahead 規則, 目標尋找至少一個數字, 第一個規則通過後, 才會開始第二個規則。 第二個規則從起始處開始搜尋, 若無找到則停止, 有找到則繼續
- 第三個 lookahead 規則, 目標尋找至少一個特殊字符, 行為同上
- 三個規則都通過後, 驗證最後一個規則, 字串可以是大小寫以及有列出的特殊符號, 數量為 8~16 個字元
crontab
安裝
- CentOS
yum install cronie
代表意義
| 代表意義 | 分鐘 | 小時 | 日期 | 月份 | 周 | 指令 |
|---|---|---|---|---|---|---|
| 數字範圍 | 0-59 | 0-23 | 1-31 | 1-1 | 0-7 | 呀就指令啊 |
比較有趣的是那個“周”喔!周的數字為 0 或 7 時,都代表“星期天”的意思!另外,還有一些輔助的字符,大概有下面這些:
| 特殊字符 | 代表意義 |
|---|---|
| *(星號) | 代表任何時刻都接受的意思!舉例來說,範例一內那個日、月、周都是 * , 就代表著“不論何月、何日的禮拜幾的 12:00 都執行後續指令”的意思! |
| ,(逗號) | 代表分隔時段的意思。舉例來說,如果要下達的工作是 3:00 與 6:00 時,就會是:0 3,6 * * * command 時間參數還是有五欄,不過第二欄是 3,6 ,代表 3 與 6 都適用! |
| -(減號) | 代表一段時間範圍內,舉例來說, 8 點到 12 點之間的每小時的 20 分都進行一項工作:20 8-12 * * * command仔細看到第二欄變成 8-12 喔!代表 8,9,10,11,12 都適用的意思! |
| /n(斜線) | 那個 n 代表數字,亦即是“每隔 n 單位間隔”的意思,例如每五分鐘進行一次,則: */5 * * * * command 很簡單吧!用 * 與 /5 來搭配,也可以寫成 0-59/5 ,相同意思! |
/etc/crontab
[root@study ~]# cat /etc/crontab |
MAILTO=root:
- 當 /etc/crontab 這個文件中的例行性工作的指令發生錯誤時,或者是該工作的執行結果有 STDOUT/STDERR 時,會將錯誤訊息或者是屏幕顯示的訊息送的對象
- 默認是由系統直接寄發一封 mail 給 root
- 例如:MAILTO=dmtsai@my.host.name
PATH=….:
輸入可執行文件的搜尋路徑,使用默認的路徑設置就已經很足夠了!“分 時 日 月 周 身份 指令”七個字段的設置
- 這個 /etc/crontab 可以設置的基本語法與 crontab -e 不太相同
- 前面同樣是分、時、日、月、週五個字段, 但是在五個字段後面接的並不是指令,就是“執行後面那串指令的身份”
- 這與使用者的 crontab -e 不相同。由於使用者自己的 crontab 並不需要指定身份
crond 服務讀取配置文件
/etc/crontab |
- 跟系統的運行比較有關係的兩個配置文件是放在 /etc/crontab 文件內以及 /etc/cron.d/* 目錄內的文件
- 跟用戶自己的工作比較有關的配置文件放在 /var/spool/cron/
其他
輸入 crontab job
crontab -e
確認 crontab 狀態
/etc/init.d/cron status
停止 crontab
/etc/init.d/cron stop
啟動 crontab
/etc/init.d/cron start
anacron
語法
[root@study ~]# anacron [-sfn] [job].. |
配置檔
[root@study ~]# cat /etc/anacrontab |
拿 /etc/cron.daily/ 那一行的設置來說明,那四個字段的意義分別是:
- 天數:anacron 執行當下與時間戳記 (/var/spool/anacron/ 內的時間紀錄檔) 相差的天數,若超過此天數,就準備開始執行,若沒有超過此天數,則不予執行後續的指令。
- 延遲時間:若確定超過天數導致要執行調度工作了,那麼請延遲執行的時間,因為擔心立即啟動會有其他資源衝突的問題吧!
- 工作名稱定義:這個沒啥意義,就只是會在 /var/log/cron 裡頭記載該項任務的名稱這樣!通常與後續的目錄資源名稱相同即可。
- 實際要進行的指令串:有沒有跟 0hourly 很像啊!沒錯!相同的作法啊!通過 run-parts 來處理的!
anacron 的執行流程(以 cron.daily 為例)
- 由 /etc/anacrontab 分析到 cron.daily 這項工作名稱的天數為 1 天;
- 由 /var/spool/anacron/cron.daily 取出最近一次執行 anacron 的時間戳記;
- 由上個步驟與目前的時間比較,若差異天數為 1 天以上 (含 1 天),就準備進行指令;
- 若準備進行指令,根據 /etc/anacrontab 的設置,將延遲 5 分鐘 + 3 小時 (看 START_HOURS_RANGE 的設置);
- 延遲時間過後,開始執行後續指令,亦即“ run-parts /etc/cron.daily ”這串指令;
執行完畢後, anacron 程序結束。
如此一來,放置在 /etc/cron.daily/ 內的任務就會在一天後一定會被執行的!
因為 anacron 是每個小時被執行一次嘛! 所以如果隔了一陣子將 CentOS 開機,開機過後約 1 小時左右系統會有一小段時間的忙碌!硬盤會跑個不停!那就是因為 anacron 正在執行過去 /etc/cron.daily/, /etc/cron.weekly/, /etc/cron.monthly/ 裡頭的未進行的各項工作調度
cron 與 anacron 與目錄之間的關係
- crond 會主動去讀取 /etc/crontab, /var/spool/cron/, /etc/cron.d/ 等配置文件,並依據“分、時、日、月、周”的時間設置去各項工作調度;
- 根據 /etc/cron.d/0hourly 的設置,主動去 /etc/cron.hourly/ 目錄下,執行所有在該目錄下的可執行文件;
- 因為 /etc/cron.hourly/0anacron 這個指令檔的緣故,主動的每小時執行 anacron ,並調用 /etc/anacrontab 的配置文件;
- 根據 /etc/anacrontab 的設置,依據每天、每週、每月去分析 /etc/cron.daily/, /etc/cron.weekly/, /etc/cron.monthly/ 內的可執行文件,以進行固定週期需要執行的指令。
- 如果你每個週日的需要執行的動作是放置於 /etc/crontab 的話,那麼該動作只要過期了就過期了,並不會被抓回來重新執行。
- 如果是放置在 /etc/cron.weekly/ 目錄下,那麼該工作就會定期,幾乎一定會在一週內執行一次
test
測試的標誌|代表意義
——–|
|1. 關於某個文件名的“文件類型”判斷,如 test -e filename 表示存在否
-e|該“文件名”是否存在?(常用)
-f|該“文件名”是否存在且為文件(file)?(常用)
-d|該“文件名”是否存在且為目錄(directory)?(常用)
-b|該“文件名”是否存在且為一個 block device 設備?
-c|該“文件名”是否存在且為一個 character device 設備?
-S|該“文件名”是否存在且為一個 Socket 文件?
-p|該“文件名”是否存在且為一個 FIFO (pipe) 文件?
-L|該“文件名”是否存在且為一個鏈接文件?
|2. 關於文件的權限偵測,如 test -r filename 表示可讀否 (但 root 權限常有例外)
-r|偵測該文件名是否存在且具有“可讀”的權限?
-w|偵測該文件名是否存在且具有“可寫”的權限?
-x|偵測該文件名是否存在且具有“可執行”的權限?
-u|偵測該文件名是否存在且具有“SUID”的屬性?
-g|偵測該文件名是否存在且具有“SGID”的屬性?
-k|偵測該文件名是否存在且具有“Sticky bit”的屬性?
-s|偵測該文件名是否存在且為“非空白文件”?
|3. 兩個文件之間的比較,如: test file1 -nt file2
-nt|(newer than)判斷 file1 是否比 file2 新
-ot|(older than)判斷 file1 是否比 file2 舊
-ef|判斷 file1 與 file2 是否為同一文件,可用在判斷 hard link 的判定上。 主要意義在判定,兩個文件是否均指向同一個 inode 哩!
|4. 關於兩個整數之間的判定,例如 test n1 -eq n2
-eq|兩數值相等 (equal)
-ne|兩數值不等 (not equal)
-gt|n1 大於 n2 (greater than)
-lt|n1 小於 n2 (less than)
-ge|n1 大於等於 n2 (greater than or equal)
-le|n1 小於等於 n2 (less than or equal)
|5. 判定字串的數據
test -z|string 判定字串是否為 0 ?若 string 為空字串,則為 true
test -n|string 判定字串是否非為 0 ?若 string 為空字串,則為 false。 -n 亦可省略
test str1 == str2|判定 str1 是否等於 str2 ,若相等,則回傳 true
test str1 != str2|判定 str1 是否不等於 str2 ,若相等,則回傳 false
|6. 多重條件判定,例如: test -r filename -a -x filename
-a|(and)兩狀況同時成立!例如 test -r file -a -x file,則 file 同時具有 r 與 x 權限時,才回傳 true。
-o|(or)兩狀況任何一個成立!例如 test -r file -o -x file,則 file 具有 r 或 x 權限時,就可回傳 true。
!|反相狀態,如 test ! -x file ,當 file 不具有 x 時,回傳 true
變量
變量的設置
| 變量設置方式 | str 沒有設置 | str 為空字串 | str 已設置非為空字串 |
|---|---|---|---|
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| var=${str+expr} | var= | var=expr | var=expr |
| var=${str:+expr} | var= | var= | var=expr |
| var=${str=expr} | str=expr var=expr |
var=expr var= |
str 不變 var=$str |
| var=${str:=expr} | str=expr var=expr |
str=expr var=expr |
str 不變 var=$str |
| var=${str?expr} | expr 輸出至 stderr | var= | var=$str |
| var=${str:?expr} | expr 輸出至 stderr | expr 輸出至 stderr | var=$str |
Script 變量帶入規則:
script 名稱,如 /path/to/scriptname | opt1 | opt2 | opt3 | opt4
—— | —— | —— | —— |
$0 | $1 | $2 | $3 | $4
可以在 script 裡面使用的特殊變量
$# :代表後接的參數“個數”,以上表為例這裡顯示為“ 4 ”;$@ :代表“ “$1” “$2” “$3” “$4” ”之意,每個變量是獨立的(用雙引號括起來);$* :代表“ “$1c$2c$3c$4” ”,其中 c 為分隔字符,默認為空白鍵, 所以本例中代表“ “$1 $2 $3 $4” ”之意。
條件判斷
單一判斷式
if [ 條件判斷式 ]; then |
- 以下 test 的方式可改編成
條件判斷式
test 方式
read -p "Please input (Y/N): " yn |
條件判斷式
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin |
多重、複雜條件判斷式
一個條件判斷,分成功進行與失敗進行 (else)
if [ 條件判斷式 ]; then |
多個條件判斷 (if … elif … elif … else) 分多種不同情況執行
if [ 條件判斷式一 ]; then |
- 將以下的 test 方式改成條件判斷式
改前:
read -p "Please input (Y/N): " yn |
改後:
#!/bin/bash |
利用 case ….. esac 判斷
- 語法:
case $變量名稱 in <==關鍵字為 case ,還有變量前有錢字號 |
- 範例:
#!/bin/bash |
練習題
使用判斷式寫一個 script, 要可以做到以下幾件事:
- 先讓使用者輸入他們的退伍日期;
- 驗證輸入格式;
- 由兩個日期的比較來顯示“還需要幾天”才能夠退伍的字樣。
解答如下:
#!/bin/bash |
netstat
這個指令可以看到目前有哪些 port 是對外開放的, 有哪些是 Listen 的
語法
netstat -[atunlp] |
範例
列出目前的路由表狀態,且以 IP 及 port number 顯示:
[root@www ~]# netstat -rn |
列出目前的所有網路連線狀態,使用 IP 與 port number
[root@www ~]# netstat -an |
function
語法:
function fname() { |
注意:
- 因為 shell script 的執行方式是由上而下,由左而右, 因此在 shell script 當中的 function 的設置一定要在程序的最前面
- function 內也可置變量,但跟 shell script 的內置變量方式不同
範例:
- 一般
#!/bin/bash |
- 內置變量
#!/bin/bash
# Program:
# Use function to repeat information.
# History:
# 2015/07/17 VBird First release
PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin:~/bin
export PATH
function printit(){
echo "Your choice is ${1}" # 這個 $1 必須要參考下面指令的下達
}
echo "This program will print your selection !"
case ${1} in
"one")
printit 1 # 請注意, printit 指令後面還有接參數!
;;
"two")
printit 2
;;
"three")
printit 3
;;
*)
echo "Usage ${0} {one|two|three}"
;;
esac
loop
while do done, until do done (不定循環)
while do done
語法
while [ condition ] <==中括號內的狀態就是判斷式 |
範例
#!/bin/bash |
#!/bin/bash |
until do done
語法
until [ condition ] |
範例
#!/bin/bash |
for…do…done (固定循環)
語法
for var in con1 con2 con3 ... |
範例
- 假設我有三種動物,分別是 dog, cat, elephant 三種, 我想每一行都輸出這樣:“There are dogs…”之類的字樣,則可以:
#!/bin/bash |
- 系統上面的各種帳號都是寫在 /etc/passwd 內的第一個字段,所以請通過管線命令的 cut 捉出單純的帳號名稱後,以 id 分別檢查使用者的識別碼與特殊參數
#!/bin/bash |
- 讓使用者輸入某個目錄文件名, 然後我找出某目錄內的文件名的權限
#!/bin/bash |
for…do…done 的數值處理
語法
- 初始值:某個變量在循環當中的起始值,直接以類似 i=1 設置好;
- 限制值:當變量的值在這個限制值的範圍內,就繼續進行循環。例如 i<=100;
- 執行步階:每作一次循環時,變量的變化量。例如 i=i+1。
for (( 初始值; 限制值; 執行步階 )) |
- 範例
#!/bin/bash |
搭配亂數與陣列的實驗
範例
#!/bin/bash |
#!/bin/bash |
loop array
for i in "${array[@]}" |
shell script 的追蹤與 debug
語法
sh [-nvx] scripts.sh |
範例
- 測試 dir_perm.sh 有無語法的問題?
sh -n dir_perm.sh |
- 將 show_animal.sh 的執行過程全部列出來~
sh -x show_animal.sh |
練習題
- 請創建一支 script ,當你執行該 script 的時候,該 script 可以顯示: 1. 你目前的身份 (用 whoami ) 2. 你目前所在的目錄 (用 pwd)
#!/bin/bash |
- 請自行創建一支程序,該程序可以用來計算“你還有幾天可以過生日”啊?
#!/bin/bash |
- 讓使用者輸入一個數字,程序可以由 1+2+3… 一直累加到使用者輸入的數字為止。
#!/bin/bash |
- 撰寫一支程序,他的作用是: 1.) 先查看一下 /root/test/logical 這個名稱是否存在; 2.) 若不存在,則創建一個文件,使用 touch 來創建,創建完成後離開; 3.) 如果存在的話,判斷該名稱是否為文件,若為文件則將之刪除後創建一個目錄,文件名為 logical ,之後離開; 4.) 如果存在的話,而且該名稱為目錄,則移除此目錄!
#!/bin/bash |
- 我們知道 /etc/passwd 裡面以 : 來分隔,第一欄為帳號名稱。請寫一隻程序,可以將 /etc/passwd 的第一欄取出,而且每一欄都以一行字串“The 1 account is “root” ”來顯示,那個 1 表示行數。
#!/bin/bash |
/etc/passwd 文件架構
帳號名稱: 需要用來對應 UID, 例如 root 的 UID 對應就是 0 (第三字段)
密碼: 早期 Unix 系統的密碼就是放在這字段上!但是因為這個文件的特性是所有的程序都能夠讀取,這樣一來很容易造成密碼數據被竊取, 因此後來就將這個字段的密碼數據給他改放到 /etc/shadow 中了。所以這裡你會看到一個“ x ”
UID: 使用者識別碼! Linux 對於 UID 有幾個限制:
id 範圍 | 該 ID 使用者特性
——-|
0(系統管理員)| 當 UID 是 0 時,代表這個帳號是“系統管理員”! 所以當你要讓其他的帳號名稱也具有 root 的權限時,將該帳號的 UID 改為 0 即可。 這也就是說,一部系統上面的系統管理員不見得只有 root 喔! 不過,很不建議有多個帳號的 UID 是 0 啦~容易讓系統管理員混亂!
1999(系統帳號)| 保留給系統使用的 ID,其實除了 0 之外,其他的 UID 權限與特性並沒有不一樣。默認 1000 以下的數字讓給系統作為保留帳號只是一個習慣。 200:由 distributions 自行創建的系統帳號;
由於系統上面啟動的網絡服務或背景服務希望使用較小的權限去運行,因此不希望使用 root 的身份去執行這些服務, 所以我們就得要提供這些運行中程序的擁有者帳號才行。這些系統帳號通常是不可登陸的, 所以才會有我們在第十章提到的 /sbin/nologin 這個特殊的 shell 存在。
根據系統帳號的由來,通常這類帳號又約略被區分為兩種:
1
201999:若使用者有系統帳號需求時,可以使用的帳號 UID。60000(可登陸帳號)| 給一般使用者用的。事實上,目前的 linux 核心 (3.10.x 版)已經可以支持到 4294967295 (2^32-1) 這麼大的 UID 號碼喔!
1000
GID: 這個與 /etc/group 有關!其實 /etc/group 的觀念與 /etc/passwd 差不多,只是他是用來規範群組名稱與 GID 的對應而已!
使用者信息說明欄: 這個字段基本上並沒有什麼重要用途,只是用來解釋這個帳號的意義而已!不過,如果您提供使用 finger 的功能時, 這個字段可以提供很多的訊息呢!本章後面的 chfn 指令會來解釋這裡的說明。
主文件夾: 這是使用者的主文件夾,以上面為例, root 的主文件夾在 /root ,所以當 root 登陸之後,就會立刻跑到 /root 目錄裡頭啦!呵呵! 如果你有個帳號的使用空間特別的大,你想要將該帳號的主文件夾移動到其他的硬盤去該怎麼作? 沒有錯!可以在這個字段進行修改呦!默認的使用者主文件夾在 /home/yourIDname
Shell: 我們在第十章 BASH 提到很多次,當使用者登陸系統後就會取得一個 Shell 來與系統的核心溝通以進行使用者的操作任務。那為何默認 shell 會使用 bash 呢?就是在這個字段指定的囉! 這裡比較需要注意的是,有一個 shell 可以用來替代成讓帳號無法取得 shell 環境的登陸動作!那就是 /sbin/nologin 這個東西!這也可以用來製作純 pop 郵件帳號者的數據呢!
/etc/shadow 文件結構
帳號名稱:
由於密碼也需要與帳號對應啊~因此,這個文件的第一欄就是帳號,必須要與 /etc/passwd 相同才行!密碼:
這個字段內的數據才是真正的密碼,而且是經過編碼的密碼 (加密) 啦! 你只會看到有一些特殊符號的字母就是了!需要特別留意的是,雖然這些加密過的密碼很難被解出來, 但是“很難”不等於“不會”,所以,這個文件的默認權限是“-rw——-”或者是“———-”,亦即只有 root 才可以讀寫就是了!你得隨時注意,不要不小心更動了這個文件的權限呢!
另外,由於各種密碼編碼的技術不一樣,因此不同的編碼系統會造成這個字段的長度不相同。 舉例來說,舊式的 DES, MD5 編碼系統產生的密碼長度就與目前慣用的 SHA 不同[2]!SHA 的密碼長度明顯的比較長些。由於固定的編碼系統產生的密碼長度必須一致,因此“當你讓這個字段的長度改變後,該密碼就會失效(算不出來)”。 很多軟件通過這個功能,在此字段前加上 ! 或 * 改變密碼字段長度,就會讓密碼“暫時失效”了。最近更動密碼的日期:
這個字段記錄了“更動密碼那一天”的日期,不過,很奇怪呀!在我的例子中怎麼會是 16559 呢?呵呵,這個是因為計算 Linux 日期的時間是以 1970 年 1 月 1 日作為 1 而累加的日期,1971 年 1 月 1 日則為 366 啦! 得注意一下這個數據呦!上述的 16559 指的就是 2015-05-04 那一天啦!瞭解乎? 而想要了解該日期可以使用本章後面 chage 指令的幫忙!至於想要知道某個日期的累積日數, 可使用如下的程序計算:
echo $(($(date --date="2015/05/04" +%s)/86400+1)) |
上述指令中,2015/05/04 為你想要計算的日期,86400 為每一天的秒數, %s 為 1970/01/01 以來的累積總秒數。 由於 bash 僅支持整數,因此最終需要加上 1 補齊 1970/01/01 當天。
密碼不可被更動的天數:(與第 3 字段相比)
第四個字段記錄了:這個帳號的密碼在最近一次被更改後需要經過幾天才可以再被變更!如果是 0 的話, 表示密碼隨時可以更動的意思。這的限制是為了怕密碼被某些人一改再改而設計的!如果設置為 20 天的話,那麼當你設置了密碼之後, 20 天之內都無法改變這個密碼呦!密碼需要重新變更的天數:(與第 3 字段相比)
經常變更密碼是個好習慣!為了強制要求使用者變更密碼,這個字段可以指定在最近一次更改密碼後, 在多少天數內需要再次的變更密碼才行。你必須要在這個天數內重新設置你的密碼,否則這個帳號的密碼將會“變為過期特性”。 而如果像上面的 99999 (計算為 273 年) 的話,那就表示,呵呵,密碼的變更沒有強制性之意。密碼需要變更期限前的警告天數:(與第 5 字段相比)
當帳號的密碼有效期限快要到的時候 (第 5 字段),系統會依據這個字段的設置,發出“警告”言論給這個帳號,提醒他“再過 n 天你的密碼就要過期了,請儘快重新設置你的密碼呦!”,如上面的例子,則是密碼到期之前的 7 天之內,系統會警告該用戶。密碼過期後的帳號寬限時間(密碼失效日):(與第 5 字段相比)
密碼有效日期為“更新日期(第3字段)”+“重新變更日期(第5字段)”,過了該期限後使用者依舊沒有更新密碼,那該密碼就算過期了。 雖然密碼過期但是該帳號還是可以用來進行其他工作的,包括登陸系統取得 bash 。不過如果密碼過期了, 那當你登陸系統時,系統會強制要求你必須要重新設置密碼才能登陸繼續使用喔,這就是密碼過期特性。帳號失效日期:
這個日期跟第三個字段一樣,都是使用 1970 年以來的總日數設置。這個字段表示: 這個帳號在此字段規定的日期之後,將無法再使用。 就是所謂的“帳號失效”,此時不論你的密碼是否有過期,這個“帳號”都不能再被使用! 這個字段會被使用通常應該是在“收費服務”的系統中,你可以規定一個日期讓該帳號不能再使用啦!保留:
最後一個字段是保留的,看以後有沒有新功能加入。
範例
假如我的使用者的密碼欄如下所示:
dmtsai:$6$M4IphgNP2TmlXaSS$B418YFroYxxmm....:16559:5:60:7:5:16679: |
由於密碼幾乎僅能單向運算(由明碼計算成為密碼,無法由密碼反推回明碼),因此由上表的數據我們無法得知 dmstai 的實際密碼明文 (第二個字段);
此帳號最近一次更動密碼的日期是 2015/05/04 (16559);
能夠再次修改密碼的時間是 5 天以後,也就是 2015/05/09 以前 dmtsai 不能修改自己的密碼;如果使用者還是嘗試要更動自己的密碼,系統就會出現這樣的訊息:
You must wait longer to change your password |
由於密碼過期日期定義為 60 天后,亦即累積日數為: 16559+60=16619,經過計算得到此日數代表日期為 2015/07/03。 這表示:“使用者必須要在 2015/05/09 (前 5 天不能改) 到 2015/07/03 之間的 60 天限制內去修改自己的密碼,若 2015/07/03 之後還是沒有變更密碼時,該密碼就宣告為過期”了!
警告日期設為 7 天,亦即是密碼過期日前的 7 天,在本例中則代表 2015/06/26 ~ 2015/07/03 這七天。 如果使用者一直沒有更改密碼,那麼在這 7 天中,只要 dmtsai 登陸系統就會發現如下的訊息:
Warning: your password will expire in 5 days如果該帳號一直到 2015/07/03 都沒有更改密碼,那麼密碼就過期了。但是由於有 5 天的寬限天數, 因此 dmtsai 在 2015/07/08 前都還可以使用舊密碼登陸主機。 不過登陸時會出現強制更改密碼的情況,畫面有點像下面這樣:
You are required to change your password immediately (password aged) |
你必須要輸入一次舊密碼以及兩次新密碼後,才能夠開始使用系統的各項資源。如果你是在 2015/07/08 以後嘗試以 dmtsai 登陸的話,那麼就會出現如下的錯誤訊息且無法登陸,因為此時你的密碼就失效去啦!
Your account has expired; please contact your system administrator
如果使用者在 2015/07/03 以前變更過密碼,那麼第 3 個字段的那個 16559 的天數就會跟著改變,因此, 所有的限制日期也會跟著相對變動喔!^_^
無論使用者如何動作,到了 16679 (大約是 2015/09/01 左右) 該帳號就失效了~
獲取 shadow 的加密機制
- 安裝 authconfig, 如果沒有裝的話
yum install authconfig-gtk* |
- 查詢
authconfig --test | grep hashing |
關於群組: 有效與初始群組、groups, newgrp
/etc/group 文件結構
如下:
root:x:0: |
群組名稱:
就是群組名稱啦!同樣用來給人類使用的,基本上需要與第三字段的 GID 對應。群組密碼:
通常不需要設置,這個設置通常是給“群組管理員”使用的,目前很少有這個機會設置群組管理員啦! 同樣的,密碼已經移動到 /etc/gshadow 去,因此這個字段只會存在一個“x”而已;GID:
就是群組的 ID 啊。我們 /etc/passwd 第四個字段使用的 GID 對應的群組名,就是由這裡對應出來的!此群組支持的帳號名稱:
我們知道一個帳號可以加入多個群組,那某個帳號想要加入此群組時,將該帳號填入這個字段即可。 舉例來說,如果我想要讓 dmtsai 與 alex 也加入 root 這個群組,那麼在第一行的最後面加上“dmtsai,alex”,注意不要有空格, 使成為“ root:x:0:dmtsai,alex ”就可以囉~
/etc/gshadow 文件結構
- 群組名稱
- 密碼欄,同樣的,開頭為 ! 表示無合法密碼,所以無群組管理員
- 群組管理員的帳號 (相關信息在 gpasswd 中介紹)
- 有加入該群組支持的所屬帳號 (與 /etc/group 內容相同!)
/etc/passwd 與 /etc/group 與 /etc/shadow 示意圖
談完了 /etc/passwd, /etc/shadow, /etc/group 之後,我們可以使用一個簡單的圖示來了解一下 UID / GID 與密碼之間的關係, 圖示如下。其實重點是 /etc/passwd 啦,其他相關的數據都是根據這個文件的字段去找尋出來的。 下圖中, root 的 UID 是 0 ,而 GID 也是 0 ,去找 /etc/group 可以知道 GID 為 0 時的群組名稱就是 root 哩。 至於密碼的尋找中,會找到 /etc/shadow 與 /etc/passwd 內同帳號名稱的那一行,就是密碼相關數據囉。

finger
- Login:為使用者帳號,亦即 /etc/passwd 內的第一字段;
- Name:為全名,亦即 /etc/passwd 內的第五字段(或稱為註解);
- Directory:就是主文件夾了;
- Shell:就是使用的 Shell 文件所在;
- Never logged in.:figner 還會調查使用者登陸主機的情況喔!
- No mail.:調查 /var/spool/mail 當中的信箱數據;
- No Plan.:調查 ~vbird1/.plan 文件,並將該文件取出來說明!
chfn
chfn [-foph] [帳號名] |
chage
- 更詳細的密碼參數顯示功能
- 可讓使用者在第一次登陸時, 強制她們一定要更改密碼後才能夠使用系統資源
語法
chage [-ldEImMW] 帳號名 |
範例
範例一:列出 vbird2 的詳細密碼參數 |
chsh
語法:
chsh [-ls] |
範例
範例一:用 vbird1 的身份列出系統上所有合法的 shell,並且指定 csh 為自己的 shell |
groupadd
語法
groupadd [-g gid] [-r] 群組名稱 |
範例
範例一:新建一個群組,名稱為 group1 |
groupmod
語法
groupmod [-g gid] [-n group_name] 群組名 |
範例
範例一:將剛剛上個指令創建的 group1 名稱改為 mygroup , GID 為 201 |
groupdel
語法
groupdel [groupname] |
gpasswd
語法
系統管理員 (root)
gpasswd groupname |
群組管理員 (Group administrator)
gpasswd [-ad] user groupname |
範例
範例一:創建一個新群組,名稱為 testgroup 且群組交由 vbird1 管理: |
範例二:以 vbird1 登陸系統,並且讓他加入 vbird1, vbird3 成為 testgroup 成員 |
ACL
setfacl
setfacl :設置某個目錄/文件的 ACL 規範。
語法
setfacl [-bkRd] [{-m|-x} acl參數] 目標文件名 |
getfacl
語法
getfacl filename |
顯示的數據前面加上 # 的,代表這個文件的默認屬性,包括文件名、文件擁有者與文件所屬群組。user, group, mask, other 則是屬於不同使用者、群組與有效權限(mask)的設置值。
su
語法
su [-lm] [-c 指令] [username] |
sudo
語法
sudo [-b] [-u 新使用者帳號] |
sudoers
更改設置
visodu |
root ALL=(ALL) ALL <==找到這一行,大約在 98 行左右 |
使用者帳號 登陸者的來源主機名稱=(可切換的身份) 可下達的指令 |
- “使用者帳號”:系統的哪個帳號可以使用 sudo 這個指令的意思;
- “登陸者的來源主機名稱”:當這個帳號由哪部主機連線到本 Linux 主機,意思是這個帳號可能是由哪一部網絡主機連線過來的, 這個設置值可以指定用戶端計算機(信任的來源的意思)。默認值 root 可來自任何一部網絡主機
- “(可切換的身份)”:這個帳號可以切換成什麼身份來下達後續的指令,默認 root 可以切換成任何人;
- “可下達的指令”:可用該身份下達什麼指令?這個指令請務必使用絕對路徑撰寫。 默認 root 可以切換任何身份且進行任何指令之意。
那個 ALL 是特殊的關鍵字,代表任何身份、主機或指令的意思。所以,我想讓 vbird1 可以進行任何身份的任何指令, 就如同上表特殊字體寫的那樣,其實就是複製上述默認值那一行,再將 root 改成 vbird1 即可啊! 此時“vbird1 不論來自哪部主機登陸,他可以變換身份成為任何人,且可以進行系統上面的任何指令”之意。 修改完請儲存後離開 vi,並以 vbird1 登陸系統後,進行如下的測試看看:
visudo
更改默認編輯器
update-alternatives --config editor |
PAM 模塊設置語法
程序與 PAM 的關係圖
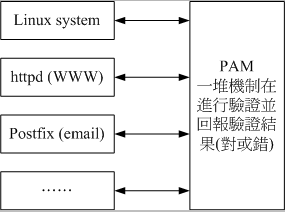
程序調用 PAM 的流程
- 使用者開始執行 /usr/bin/passwd 這支程序,並輸入密碼;
- passwd 調用 PAM 模塊進行驗證;
- PAM 模塊會到 /etc/pam.d/ 找尋與程序 (passwd) 同名的配置文件;
- 依據 /etc/pam.d/passwd 內的設置,引用相關的 PAM 模塊逐步進行驗證分析;
- 將驗證結果 (成功、失敗以及其他訊息) 回傳給 passwd 這支程序;
- passwd 這支程序會根據 PAM 回傳的結果決定下一個動作 (重新輸入新密碼或者通過驗證!)
配置文件內容
cat /etc/pam.d/passwd |
驗證類別 (type)
驗證類別主要分為四種,分別說明如下:
auth
是 authentication (認證) 的縮寫,所以這種類別主要用來檢驗使用者的身份驗證,這種類別通常是需要密碼來檢驗的, 所以後續接的模塊是用來檢驗使用者的身份。
account
account (帳號) 則大部分是在進行 authorization (授權),這種類別則主要在檢驗使用者是否具有正確的使用權限, 舉例來說,當你使用一個過期的密碼來登陸時,當然就無法正確的登陸了。
session
session 是會議期間的意思,所以 session 管理的就是使用者在這次登陸 (或使用這個指令) 期間,PAM 所給予的環境設置。 這個類別通常用在記錄使用者登陸與登出時的信息!例如,如果你常常使用 su 或者是 sudo 指令的話, 那麼應該可以在 /var/log/secure 裡面發現很多關於 pam 的說明,而且記載的數據是“session open, session close”的信息!
password
password 就是密碼嘛!所以這種類別主要在提供驗證的修訂工作,舉例來說,就是修改/變更密碼啦!
這四個驗證的類型通常是有順序的,不過也有例外就是了。 會有順序的原因是,(1)我們總是得要先驗證身份 (auth) 後, (2)系統才能夠藉由使用者的身份給予適當的授權與權限設置 (account),而且(3)登陸與登出期間的環境才需要設置, 也才需要記錄登陸與登出的信息 (session)。如果在運行期間需要密碼修訂時,(4)才給予 password 的類別。這樣說起來, 自然是需要有點順序吧!
驗證的控制旗標 (control flag)
那麼“驗證的控制旗標(control flag)”又是什麼?簡單的說,他就是“驗證通過的標準”啦! 這個字段在管控該驗證的放行方式,主要也分為四種控制方式:
required
此驗證若成功則帶有 success (成功) 的標誌,若失敗則帶有 failure 的標誌,但不論成功或失敗都會繼續後續的驗證流程。 由於後續的驗證流程可以繼續進行,因此相當有利於數據的登錄 (log) ,這也是 PAM 最常使用 required 的原因。
requisite
若驗證失敗則立刻回報原程序 failure 的標誌,並終止後續的驗證流程。若驗證成功則帶有 success 的標誌並繼續後續的驗證流程。 這個項目與 required 最大的差異,就在於失敗的時候還要不要繼續驗證下去?由於 requisite 是失敗就終止, 因此失敗時所產生的 PAM 信息就無法通過後續的模塊來記錄了。
sufficient
若驗證成功則立刻回傳 success 給原程序,並終止後續的驗證流程;若驗證失敗則帶有 failure 標誌並繼續後續的驗證流程。 這玩意兒與 requisits 剛好相反!
optional
這個模塊控制項目大多是在顯示訊息而已,並不是用在驗證方面的。
如果將這些控制旗標以圖示的方式配合成功與否的條件繪圖,會有點像下面這樣:

程序運行過程中遇到驗證時才會去調用 PAM ,而 PAM 驗證又分很多類型與控制,不同的控制旗標所回報的訊息並不相同。 如上圖所示, requisite 失敗就回報了並不會繼續,而 sufficient 則是成功就回報了也不會繼續。 至於驗證結束後所回報的信息通常是“succes 或 failure ”而已,後續的流程還需要該程序的判斷來繼續執行才行。
jobs
語法
[root@study ~]# jobs [-lrs] |
fg
語法
[root@study ~]# fg %jobnumber |
ps
語法
[root@study ~]# ps aux <==觀察系統所有的程序數據 |
觀察自己的 bash 相關程序
ps -l |
輸出如下:
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD |
詳解:
系統整體的程序運行是非常多的,但如果使用 ps -l 則僅列出與你的操作環境 (bash) 有關的程序而已, 亦即最上層的父程序會是你自己的 bash 而沒有延伸到 systemd (後續會交待!) 這支程序去!那麼 ps -l 秀出來的數據有哪些呢? 我們就來觀察看看:
F:代表這個程序旗標 (process flags),說明這個程序的總結權限,常見號碼有:
- 若為 4 表示此程序的權限為 root ;
- 若為 1 則表示此子程序僅進行複製(fork)而沒有實際執行(exec)。
S:代表這個程序的狀態 (STAT),主要的狀態有:
- R (Running):該程序正在運行中;
- S (Sleep):該程序目前正在睡眠狀態(idle),但可以被喚醒(signal)。
- D :不可被喚醒的睡眠狀態,通常這支程序可能在等待 I/O 的情況(ex>打印)
- T :停止狀態(stop),可能是在工作控制(背景暫停)或除錯 (traced) 狀態;
- Z (Zombie):殭屍狀態,程序已經終止但卻無法被移除至內存外。
UID/PID/PPID:代表“此程序被該 UID 所擁有/程序的 PID 號碼/此程序的父程序 PID 號碼”
C:代表 CPU 使用率,單位為百分比;
PRI/NI:Priority/Nice 的縮寫,代表此程序被 CPU 所執行的優先順序,數值越小代表該程序越快被 CPU 執行。詳細的 PRI 與 NI 將在下一小節說明。
ADDR/SZ/WCHAN:都與內存有關,ADDR 是 kernel function,指出該程序在內存的哪個部分,如果是個 running 的程序,一般就會顯示“ - ” / SZ 代表此程序用掉多少內存 / WCHAN 表示目前程序是否運行中,同樣的, 若為 - 表示正在運行中。
TTY:登陸者的終端機位置,若為遠端登陸則使用動態終端接口 (pts/n);
TIME:使用掉的 CPU 時間,注意,是此程序實際花費 CPU 運行的時間,而不是系統時間;
CMD:就是 command 的縮寫,造成此程序的觸發程序之指令為何。
所以你看到的 ps -l 輸出訊息中,他說明的是:“bash 的程序屬於 UID 為 0 的使用者,狀態為睡眠 (sleep), 之所以為睡眠因為他觸發了 ps (狀態為 run) 之故。此程序的 PID 為 14836,優先執行順序為 80 , 下達 bash 所取得的終端接口為 pts/0 ,運行狀態為等待 (wait) 。”這樣已經夠清楚了吧? 您自己嘗試解析一下那麼 ps 那一行代表的意義為何呢? ^_^
接下來讓我們使用 ps 來觀察一下系統內所有的程序狀態吧!
觀察系統所有程序
ps aux |
輸出:
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND |
詳解:
你會發現 ps -l 與 ps aux 顯示的項目並不相同!在 ps aux 顯示的項目中,各字段的意義為:
- USER:該 process 屬於那個使用者帳號的?
- PID :該 process 的程序識別碼。
- %CPU:該 process 使用掉的 CPU 資源百分比;
- %MEM:該 process 所佔用的實體內存百分比;
- VSZ :該 process 使用掉的虛擬內存量 (KBytes)
- RSS :該 process 佔用的固定的內存量 (KBytes)
- TTY :該 process 是在那個終端機上面運行,若與終端機無關則顯示 ?,另外, tty1-tty6 是本機上面的登陸者程序,若為 pts/0 等等的,則表示為由網絡連接進主機的程序。
- STAT:該程序目前的狀態,狀態顯示與 ps -l 的 S 旗標相同 (R/S/T/Z)
- START:該 process 被觸發啟動的時間;
- TIME :該 process 實際使用 CPU 運行的時間。
- COMMAND:該程序的實際指令為何?
一般來說,ps aux 會依照 PID 的順序來排序顯示,我們還是以 14836 那個 PID 那行來說明!該行的意義為“ root 執行的 bash PID 為 14836,佔用了 0.1% 的內存容量百分比,狀態為休眠 (S),該程序啟動的時間為 8 月 4 號,因此啟動太久了, 所以沒有列出實際的時間點。且取得的終端機環境為 pts/0 。”與 ps aux 看到的其實是同一個程序啦!這樣可以理解嗎? 讓我們繼續使用 ps 來觀察一下其他的信息吧!
top
相對於 ps 是擷取一個時間點的程序狀態, top 則可以持續偵測程序運行的狀態!使用方式如下:
語法
[root@study ~]# top [-d 數字] | top [-bnp] |
pstree
語法
[root@study ~]# pstree [-A|U] [-up] |
nice
語法
[root@study ~]# nice [-n 數字] command |
renice
語法
[root@study ~]# renice [number] PID |
free
觀察內存使用情況
語法
[root@study ~]# free [-b|-k|-m|-g|-h] [-t] [-s N -c N] |
備註
[root@study ~]# free -m |
名稱 | 意義
—-|
swap | 內存交換空間的量
total | 總量
used | 已被使用的量
free | 剩餘可用的量
shared/buffers/cached | 已被使用的量中,用來作為緩衝及高速緩存的量。
這些用量中,在系統比較忙碌時,可以被釋出而繼續利用
uname
查閱系統與核心相關信息
語法
[root@study ~]# uname [-asrmpi] |
uptime
觀察系統啟動時間與工作負載
這個指令很單純:
- 顯示出目前系統已經開機多久的時間
- 1, 5, 15 分鐘的平均負載
這個 uptime 可以顯示出 top 畫面的最上面一行
netstat
追蹤網絡或插槽檔
語法
[root@study ~]# uname [-asrmpi] |
備註
[root@study ~]# netstat |
在上面的結果當中,顯示了兩個部分:
- 網絡的連線
- linux 上面的 socket 程序相關性部分
我們先來看看網際網絡連線情況的部分:
- Proto :網絡的封包協定,主要分為 TCP 與 UDP 封包,相關數據請參考服務器篇;
- Recv-Q:非由使用者程序鏈接到此 socket 的複製的總 Bytes 數;
- Send-Q:非由遠端主機傳送過來的 acknowledged 總 Bytes 數;
- Local Address :本地端的 IP:port 情況
- Foreign Address:遠端主機的 IP:port 情況
- State :連線狀態,主要有創建(ESTABLISED)及監聽(LISTEN);
我們看上面僅有一條連線的數據,他的意義是:“通過 TCP 封包的連線,遠端的 172.16.220.234:48300 連線到本地端的 172.16.15.100:ssh ,這條連線狀態是創建 (ESTABLISHED) 的狀態!”至於更多的網絡環境說明, 就得到鳥哥的另一本服務器篇查閱囉!
socket file:
- 插槽檔
- 溝通兩個程序之間的信息
上表中 socket file 的輸出字段:
- Proto :一般就是 unix 啦;
- RefCnt:連接到此 socket 的程序數量;
- Flags :連線的旗標;
- Type :socket 存取的類型。主要有確認連線的 STREAM 與不需確認的 DGRAM 兩種;
- State :若為 CONNECTED 表示多個程序之間已經連線創建。
- Path :連接到此 socket 的相關程序的路徑!或者是相關數據輸出的路徑。
dmesg
分析核心產生的訊息
系統在開機的時候,核心會去偵測系統的硬件,你的某些硬件到底有沒有被捉到,那就與這個時候的偵測有關。 dmesg 可以顯示這些偵測的過程
範例
範例一:輸出所有的核心開機時的信息
dmesg | less |
範例二:搜尋開機的時候,硬盤的相關信息為何?
dmesg | grep -i vda |
輸出:
[ 0.758551] vda: vda1 vda2 vda3 vda4 vda5 vda6 vda7 vda8 vda9 |
vmstat
偵測系統資源變化
vmstat 可以偵測“ CPU / 內存 / 磁盤輸入輸出狀態 ”等等
語法
[root@study ~]# vmstat [-a] [延遲 [總計偵測次數]] <==CPU/內存等信息 |
範例
範例一:統計目前主機 CPU 狀態,每秒一次,共計三次!
vmstat 1 3 |
範例輸出:

範例二:系統上面所有的磁盤的讀寫狀態
vmstat -d |
範例輸出:

利用 vmstat 甚至可以進行追蹤喔!你可以使用類似“ vmstat 5 ”代表每五秒鐘更新一次,且無窮的更新!直到你按下 [ctrl]-c 為止。如果你想要實時的知道系統資源的運行狀態,這個指令就不能不知道!那麼上面的表格各項字段的意義為何? 基本說明如下:
程序字段 (procs) 的項目分別為:
- r :等待運行中的程序數量;
- b:不可被喚醒的程序數量。這兩個項目越多,代表系統越忙碌 (因為系統太忙,所以很多程序就無法被執行或一直在等待而無法被喚醒之故)。
內存字段 (memory) 項目分別為:
- swpd:虛擬內存被使用的容量;
- free:未被使用的內存容量;
- buff:用於緩衝內存;
- cache:用於高速緩存內存。 這部份則與 free 是相同的。
內存交換空間 (swap) 的項目分別為:
- si:由磁盤中將程序取出的量;
- so:由於內存不足而將沒用到的程序寫入到磁盤的 swap 的容量。 如果 si/so 的數值太大,表示內存內的數據常常得在磁盤與內存之間傳來傳去,系統性能會很差!
磁盤讀寫 (io) 的項目分別為:
- bi:由磁盤讀入的區塊數量;
- bo:寫入到磁盤去的區塊數量。如果這部份的值越高,代表系統的 I/O 非常忙碌!
系統 (system) 的項目分別為:
- in:每秒被中斷的程序次數;
- cs:每秒鐘進行的事件切換次數;這兩個數值越大,代表系統與周邊設備的溝通非常頻繁! 這些周邊設備當然包括磁盤、網卡、時間鍾等。
CPU 的項目分別為:
- us:非核心層的 CPU 使用狀態;
- sy:核心層所使用的 CPU 狀態;
- id:閒置的狀態;
- wa:等待 I/O 所耗費的 CPU 狀態;
- st:被虛擬機 (virtual machine) 所盜用的 CPU 使用狀態 (2.6.11 以後才支持)。
/proc
基本上,目前主機上面的各個程序的 PID 都是以目錄的型態存在於 /proc 當中。 舉例來說,我們開機所執行的第一支程序 systemd 他的 PID 是 1 , 這個 PID 的所有相關信息都寫入在 /proc/1/* 當中!若我們直接觀察 PID 為 1 的數據好了,他有點像這樣:
文件內容
文件名 | 文件內容
——|
/proc/cmdline | 載入 kernel 時所下達的相關指令與參數!查閱此文件,可瞭解指令是如何啟動的!
/proc/cpuinfo | 本機的 CPU 的相關信息,包含頻率、類型與運算功能等
/proc/devices | 這個文件記錄了系統各個主要設備的主要設備代號,與 mknod 有關呢!
/proc/filesystems | 目前系統已經載入的文件系統囉!
/proc/interrupts | 目前系統上面的 IRQ 分配狀態。
/proc/ioports | 目前系統上面各個設備所配置的 I/O 位址。
/proc/kcore | 這個就是內存的大小啦!好大對吧!但是不要讀他啦!
/proc/loadavg | 還記得 top 以及 uptime 吧?沒錯!上頭的三個平均數值就是記錄在此!
/proc/meminfo | 使用 free 列出的內存信息,嘿嘿!在這裡也能夠查閱到!
/proc/modules | 目前我們的 Linux 已經載入的模塊列表,也可以想成是驅動程序啦!
/proc/mounts | 系統已經掛載的數據,就是用 mount 這個指令調用出來的數據啦!
/proc/swaps | 到底系統掛載入的內存在哪裡?呵呵!使用掉的 partition 就記錄在此啦!
/proc/partitions | 使用 fdisk -l 會出現目前所有的 partition 吧?在這個文件當中也有紀錄喔!
/proc/uptime | 就是用 uptime 的時候,會出現的信息啦!
/proc/version | 核心的版本,就是用 uname -a 顯示的內容啦!
/proc/bus/* | 一些總線的設備,還有 USB 的設備也記錄在此喔!
fuser
藉由文件(或文件系統)找出正在使用該文件的程序
語法
[root@study ~]# fuser [-umv] [-k [i] [-signal]] file/dir |
範例
範例一:找出目前所在目錄的使用 PID/所屬帳號/權限 為何? |
範例二:找到所有使用到 /proc 這個文件系統的程序吧!
[root@study ~]# fuser -uv /proc
/proc: root kernel mount (root)/proc
rtkit 768 .rc.. (rtkit)rtkit-daemon
數據量還不會很多,雖然這個目錄很繁忙~沒關係!我們可以繼續這樣作,看看其他的程序!
[root@study ~]# fuser -mvu /proc
USER PID ACCESS COMMAND
/proc: root kernel mount (root)/proc
root 1 f…. (root)systemd
root 2 …e. (root)kthreadd
…..(下面省略)…..
有這幾支程序在進行 /proc 文件系統的存取喔!這樣清楚了嗎?
範例三:找到所有使用到 /home 這個文件系統的程序吧!
[root@study ~]# echo $$
31743 # 先確認一下,自己的 bash PID 號碼吧!
[root@study ~]# cd /home
[root@study home]# fuser -muv .
USER PID ACCESS COMMAND
/home: root kernel mount (root)/home
dmtsai 31535 ..c.. (dmtsai)bash
root 31571 ..c.. (root)passwd
root 31737 ..c.. (root)sudo
root 31743 ..c.. (root)bash # 果然,自己的 PID 在啊!
[root@study home]# cd ~
[root@study ~]# umount /home
umount: /home: target is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))
從 fuser 的結果可以知道,總共有五隻 process 在該目錄下運行,那即使 root 離開了 /home,
當然還是無法 umount 的!那要怎辦?哈哈!可以通過如下方法一個一個刪除~
[root@study ~]# fuser -mki /home
/home: 31535c 31571c 31737c # 你會發現, PID 跟上面查到的相同!
Kill process 31535 ? (y/N) # 這裡會問你要不要刪除!當然不要亂刪除啦!通通取消!
|
lsof [-aUu] [+d]
選項與參數:
-t :terse, 簡短輸出, 可以輸出符合 kill 的參數
-a :多項數據需要“同時成立”才顯示出結果時!
-U :僅列出 Unix like 系統的 socket 文件類型;
-u :後面接 username,列出該使用者相關程序所打開的文件;
+d :後面接目錄,亦即找出某個目錄下面已經被打開的文件!
|
pidof [-sx] program_name
選項與參數:
-s :僅列出一個 PID 而不列出所有的 PID
-x :同時列出該 program name 可能的 PPID 那個程序的 PID
|
systemctl [command] [unit]
command 主要有:
start :立刻啟動後面接的 unit
stop :立刻關閉後面接的 unit
restart :立刻關閉後啟動後面接的 unit,亦即執行 stop 再 start 的意思
reload :不關閉後面接的 unit 的情況下,重新載入配置文件,讓設置生效
enable :設置下次開機時,後面接的 unit 會被啟動
disable :設置下次開機時,後面接的 unit 不會被啟動
status :目前後面接的這個 unit 的狀態,會列出有沒有正在執行、開機默認執行否、登錄等信息等!
is-active :目前有沒有正在運行中
is-enable :開機時有沒有默認要啟用這個 unit
is-enable :開機時有沒有默認要啟用這個 unit
systemctl [command] [–type=TYPE] [–all]
command:
list-units :依據 unit 列出目前有啟動的 unit。若加上 –all 才會列出沒啟動的。
list-unit-files :依據 /usr/lib/systemd/system/ 內的文件,將所有文件列表說明。
–type=TYPE:就是之前提到的 unit type,主要有 service, socket, target 等
|
systemctl list-units
UNIT | LOAD | ACTIVE | SUB | DESCRIPTION |
UNIT LOAD ACTIVE SUB DESCRIPTION |
- graphical.target:就是文字加上圖形界面,這個項目已經包含了下面的 multi-user.target 項目!
- multi-user.target:純文本模式!
- rescue.target:在無法使用 root 登陸的情況下,systemd 在開機時會多加一個額外的暫時系統,與你原本的 系統無關。這時你可以取得 root 的權限來維護你的系統。 但是這是額外系統,因此可能需要動到 chroot 的方式來取得你原有的系統喔!
- emergency.target:緊急處理系統的錯誤,還是需要使用 root 登陸的情況,在無法使用 rescue.target 時,可以嘗試使用這種模式!
- shutdown.target:就是關機的流程。
- getty.target:可以設置你需要幾個 tty 之類的,如果想要降低 tty 的項目,可以修改這個東西的配置文件!
取得目前的操作環境以及修改
systemctl [command] [unit.target] |
範例
範例一:我們的測試機器默認是圖形界面,先觀察是否真為圖形模式,再將默認模式轉為文字界面
[root@study ~]# systemctl get-default |
範例二:在不重新開機的情況下,將目前的操作環境改為純文本模式,關掉圖形界面
[root@study ~]# systemctl isolate multi-user.target |
範例三:若需要重新取得圖形界面呢?
[root@study ~]# systemctl isolate graphical.target |
要注意,改變 graphical.target 以及 multi-user.target 是通過 isolate 來處理的。
在正常的切換情況下,使用上述 isolate 的方式即可。不過為了方便起見, systemd 也提供了數個簡單的指令給我們切換操作模式之用喔! 大致上如下所示:
systemctl 針對機器操作的幾個簡單指令
[root@study ~]# systemctl poweroff 系統關機 |
- suspend:暫停模式會將系統的狀態數據保存到內存中,然後關閉掉大部分的系統硬件,當然,並沒有實際關機喔! 當使用者按下喚醒機器的按鈕,系統數據會重內存中回覆,然後重新驅動被大部分關閉的硬件,就開始正常運行!喚醒的速度較快。
- hibernate:休眠模式則是將系統狀態保存到硬盤當中,保存完畢後,將計算機關機。當使用者嘗試喚醒系統時,系統會開始正常運行, 然後將保存在硬盤中的系統狀態恢復回來。因為數據是由硬盤讀出,因此喚醒的性能與你的硬盤速度有關。
通過 systemctl 分析各服務之間的相依性
[root@study ~]# systemctl list-dependencies [unit] [--reverse] |
範例
範例一:列出目前的 target 環境下,用到什麼特別的 unit |
如果要查出誰會用到 multi-user.target 呢?
systemctl list-dependencies --reverse |
graphical.target 又使用了多少的服務呢?
systemctl list-dependencies graphical.target |
process substitution <( command ) or >( command )
如果使用 >(list), 那帶入的值將會作為 list 的輸入。 若使用 <(list), 那將會是 list 的輸出
語法
<(list) |
或是
>(list) |
logrotate
那個 logrotate.conf 才是主要的參數文件,至於 logrotate.d 是一個目錄, 該目錄裡面的所有文件都會被主動的讀入 /etc/logrotate.conf 當中來進行!另外,在 /etc/logrotate.d/ 裡面的文件中,如果沒有規定到的一些細部設置,則以 /etc/logrotate.conf 這個文件的規定來指定為默認值!
logrotate 這個程序的參數配置文件位置
/etc/logrotate.conf |
語法
logrotate [-vf] logfile |
[root@study ~]# vim /etc/logrotate.conf |
範例
範例 1
/root/.pm2/logs/run-checkEdgeAlive.log { |
範例 2
以 /etc/logrotate.d/syslog 這個輪替 rsyslog.service 服務的文件
vim /etc/logrotate.d/syslog |
- 文件名:被處理的登錄文件絕對路徑文件名寫在前面,可以使用空白字符分隔多個登錄文件;
- 參數:上述文件名進行輪替的參數使用 { } 包括起來;
- 執行腳本:可調用外部指令來進行額外的命令下達,這個設置需與 sharedscripts …. endscript 設置合用才行。至於可用的環境為:
- prerotate:在啟動 logrotate 之前進行的指令,例如修改登錄文件的屬性等動作;
- postrotate:在做完 logrotate 之後啟動的指令,例如重新啟動 (kill -HUP) 某個服務!
- Prerotate 與 postrotate 對於已加上特殊屬性的文件處理上面,是相當重要的執行程序!
那麼 /etc/logrotate.d/syslog 內設置的 5 個文件的輪替功能就變成了:
- 該設置只對 /var/log/ 內的 cron, maillog, messages, secure, spooler 有效;
- 登錄文件輪替每週一次、保留四個、且輪替下來的登錄文件不進行壓縮(未更改默認值);
- 輪替完畢後 (postrotate) 取得 syslog 的 PID 後,以 kill -HUP 重新啟動 syslogd
假設我們有針對 /var/log/messages 這個文件增加 chattr +a 的屬性時, 依據 logrotate 的工作原理,我們知道,這個 /var/log/messages 將會被更名成為 /var/log/messages.1 才是。但是由於加上這個 +a 的參數啊,所以更名是不可能成功的! 那怎麼辦呢?呵呵!就利用 prerotate 與 postrotate 來進行登錄文件輪替前、後所需要作的動作啊! 果真如此時,那麼你可以這樣修改一下這個文件喔!
vim /etc/logrotate.d/syslog |
- 先給他去掉 a 這個屬性,讓登錄文件 /var/log/messages 可以進行輪替的動作
- 然後執行了輪替之後,再給他加入這個屬性
- /bin/kill -HUP … 的意義,這一行的目的在於將系統的 rsyslogd 重新以其參數文件 (rsyslog.conf) 的數據讀入一次!也可以想成是 reload 的意思! 由於我們創建了一個新的空的記錄文件,如果不執行此一行來重新啟動服務的話, 那麼記錄的時候將會發生錯誤呦!
- kill -HUP: 等同 kill -1, 重啟的意思
範例 3
假設你已經創建了 /var/log/admin.log 這個文件, 現在,你想要將該文件加上 +a 這個隱藏標籤,而且設置下面的相關信息:
- 登錄文件輪替一個月進行一次;
- 該登錄文件若大於 10MB 時,則主動進行輪替,不需要考慮一個月的期限;
- 保存五個備份文件;
- 備份文件需要壓縮
先創建 +a 這個屬性
[root@study ~]# chattr +a /var/log/admin.log |
開始創建 logrotate 的配置文件,增加一個文件在 /etc/logrotate.d 內
[root@study ~]# vim /etc/logrotate.d/admin |
測試一下 logrotate 相關功能的信息顯示:
[root@study ~]# logrotate -v /etc/logrotate.conf |
測試一下強制 logrotate 與相關功能的信息顯示:
[root@study ~]# logrotate -vf /etc/logrotate.d/admin |
command || true patten
目前大部分的系統遵循 set -e (Exit immediately if a command exits with a non-zero status.) 規則,所以為了避免一些小錯誤中斷了 command 的執行,所以使用 command || true patten
例如 rmdir ... || true, 這樣就算 remove directory 失敗了, command 也不會中斷執行。
timedatectl
語法
timedatectl [commamd] |
範例
顯示目前的時區與時間等信息
指令
timedatectl
輸出
Local time: Tue 2015-09-01 19:50:09 CST # 本地時間
Universal time: Tue 2015-09-01 11:50:09 UTC # UTC 時間,可稱為格林威治標準時間
RTC time: Tue 2015-09-01 11:50:12
Timezone: Asia/Taipei (CST, +0800) # 就是時區囉!
NTP enabled: no
NTP synchronized: no
RTC in local TZ: no
DST active: n/a
顯示出是否有 New_York 時區?若有,則請將目前的時區更新一下
- 查詢是否有 New York 時區
timedatectl list-timezones | grep -i new
輸出:
America/New_York |
設定時區
timedatectl set-timezone "America/New_York"確認結果
timedatectl
範例輸出:
Local time: Tue 2015-09-01 07:53:24 EDT |
時間點調整
指令
timedatectl set-time "2019-09-30 09:00"時間格式:
yyyy-mm-dd HH:MM
ntpdate
ntpdate tock.stdtime.gov.tw |
hwclock -w |
上述的 tock.stdtime.gov.tw 指的是臺灣地區國家標準實驗室提供的時間服務器,如果你在臺灣本島上,建議使用臺灣提供的時間服務器來更新你的服務器時間, 速度會比較快些~至於 hwclock 則是將正確的時間寫入你的 BIOS 時間記錄內!如果確認可以執行,未來應該可以使用 crontab 來更新系統時間吧!
locale on MacOS
打開 .zshrc, 並貼上以下代碼
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8保存離開
重開一個 terminal 視窗
localectl
語法
localectl |
範例
如何改成英文語系的登陸界面?
localectl set-locale LANG=en_US.utf8 |
dpkg
列出所有 dpkg 安裝的套件
dpkg -l | less |
tee
tee 可以讓 standard output 轉存一份到文件內並將同樣的數據繼續送到屏幕去處理! 這樣除了可以讓我們同時分析一份數據並記錄下來之外,還可以作為處理一份數據的中間暫存盤記錄之用! tee 這傢伙在很多選擇/填充的認證考試中很容易考呢!

語法
[dmtsai@study ~]$ tee [-a] file |
sed
語法
[dmtsai@study ~]$ sed [-nefr] [動作] |
範例
範例一
將 /etc/passwd 的內容列出並且打印行號,同時,請將第 2~5 行刪除!
nl /etc/passwd | sed '2,5d' |
輸出:
1 root:x:0:0:root:/root:/bin/bash |
- 原本應要下達 sed -e ,沒有 -e 也行
- sed 後面接的動作,請務必以 ‘’ 兩個單引號括住
- 如果只要刪除第 2 行,可以使用
nl /etc/passwd | sed '2d' - 若是要刪除第 3 到最後一行,則是
nl /etc/passwd | sed '3,$d'
範例二
承上題,在第二行後(亦即是加在第三行)加上“drink tea?”字樣!
nl /etc/passwd | sed '2a drink tea' |
輸出:
1 root:x:0:0:root:/root:/bin/bash |
- 如果是要在第二行前呢?
nl /etc/passwd | sed '2i drink tea'
範例三
在第二行後面加入兩行字,例如“Drink tea or …..”與“drink beer?”
nl /etc/passwd | sed '2a Drink tea or ......\ |
輸出:
1 root:x:0:0:root:/root:/bin/bash |
- 可以新增好幾行”但是每一行之間都必須要以反斜線
\
範例四
搜尋檔案中有 gzip_ 的每一行, 將該行中的 # 取代為空白, 簡單來說, 就是 uncomment 啦
sed -i '/gzip_/ s/#\ //g' /etc/nginx/nginx.conf |
結果前後比較:

替換變量的值
將變量中的 sbin 替換成 SBIN
echo ${PATH//sbin/SBIN} |
route
[root@www ~]# route [-n]
選項與參數:
-n : 將主機名稱以 IP 的方式顯示
[root@www ~]# route |
[root@www ~]# route -n |
jq
- 取得來源 object 裡的一個 property, 並轉為 raw 輸出
node test.js | jq -r '.propertyName'
arp
語法
[root@www ~]# arp -[nd] hostname |
範例
- 列出目前主機上記載的 IP/MAC 對應的 ARP 表格
arp -n
Address HWtype HWaddress Flags Mask Iface |
- 將 192.168.1.100 那部主機的網卡卡號直接寫入 ARP 表格中
arp -s 192.168.1.100 01:00:2D:23:A1:0E
SBIT
語法
chmod 1xxx directoryName |
或是建立時給予權限
insatll -d -o ownerName -g groupName -m 1xxx directoryName |
- 只對目錄有效
- 一般來說, 任意的使用者, 只要對該目錄有 wx 的權限, 都可以
進去該資料夾以及刪除該資料夾內的檔案(資料夾) - 加上 SBIT 的屬性之後, 只有
該目錄的擁有者,root,檔案的建立者才可以刪除該目錄內的檔案(或資料夾)
ifconfig
語法
ifconfig {interface} {up|down} <== 觀察與啟動介面 |
範例
- 範例一:觀察所有的網路介面(直接輸入 ifconfig)
[root@www ~]# ifconfig
eth0 Link encap:Ethernet HWaddr 08:00:27:71:85:BD
inet addr:192.168.1.100 Bcast:192.168.1.255 Mask:255.255.255.0
inet6 addr: fe80::a00:27ff:fe71:85bd/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:2555 errors:0 dropped:0 overruns:0 frame:0
TX packets:70 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:239892 (234.2 KiB) TX bytes:11153 (10.8 KiB)
eth0: 就是網路卡的代號,也有 lo 這個 loopback ;
HWaddr: 就是網路卡的硬體位址,俗稱的 MAC 是也;
inet addr: IPv4 的 IP 位址,後續的 Bcast, Mask 分別代表的是 Broadcast 與 netmask 喔!
inet6 addr: 是 IPv6 的版本的 IP ,我們沒有使用,所以略過;
MTU: 就是第二章談到的 MTU 啊!
RX: 那一行代表的是網路由啟動到目前為止的封包接收情況, packets 代表封包數、errors 代表封包發生錯誤的數量、 dropped 代表封包由於有問題而遭丟棄的數量等等
TX: 與 RX 相反,為網路由啟動到目前為止的傳送情況;
collisions: 代表封包碰撞的情況,如果發生太多次, 表示你的網路狀況不太好;
txqueuelen: 代表用來傳輸資料的緩衝區的儲存長度;
RX bytes, TX bytes: 總接收、傳送的位元組總量
- 範例二:暫時修改網路介面,給予 eth0 一個 192.168.100.100/24 的參數
[root@www ~]# ifconfig eth0 192.168.100.100 |
- 範例三:將手動的處理全部取消,使用原有的設定值重建網路參數:
[root@www ~]# /etc/init.d/network restart
# 剛剛設定的資料全部失效,會以 ifcfg-ethX 的設定為主!
apt
route
語法
[root@www ~]# route [-nee] |
範例
單純的觀察路由狀態
指令1
route -n
範例輸出1
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
192.168.1.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
169.254.0.0 0.0.0.0 255.255.0.0 U 1002 0 0 eth0
0.0.0.0 192.168.1.254 0.0.0.0 UG 0 0 0 eth0指令2
route
範例輸出2
Kernel IP routing table |
路由的增加與刪除
[root@www ~]# route del -net 169.254.0.0 netmask 255.255.0.0 dev eth0 |
輸出資訊意義
Destination, Genmask:這兩個玩意兒就是分別是 network 與 netmask 啦!所以這兩個咚咚就組合成為一個完整的網域囉!
Gateway:該網域是通過哪個 gateway 連接出去的?如果顯示 0.0.0.0 表示該路由是直接由本機傳送,亦即可以透過區域網路的 MAC 直接傳訊;如果有顯示 IP 的話,表示該路由需要經過路由器 (通訊閘) 的幫忙才能夠傳送出去。
Flags:總共有多個旗標,代表的意義如下:
- U (route is up):該路由是啟動的;
- H (target is a host):目標是一部主機 (IP) 而非網域;
- G (use gateway):需要透過外部的主機 (gateway) 來轉遞封包;
- R (reinstate route for dynamic routing):使用動態路由時,恢復路由資訊的旗標;
- D (dynamically installed by daemon or redirect):已經由服務或轉 port 功能設定為動態路由
- M (modified from routing daemon or redirect):路由已經被修改了;
- ! (reject route):這個路由將不會被接受(用來抵擋不安全的網域!)
Iface:這個路由傳遞封包的介面。
ip
語法
[root@www ~]# ip [option] [動作] [指令] |
traceroute
語法
[root@www ~]# traceroute [選項與參數] IP |
範例
偵測本機到 yahoo 去的各節點連線狀態
[root@www ~]# traceroute -n tw.yahoo.com |
tcpdump
語法
[root@www ~]# tcpdump [-AennqX] [-i 介面] [-w 儲存檔名] [-c 次數] \ |
範例
以 IP 與 port number 捉下 eth0 這個網路卡上的封包,持續 3 秒
[root@www ~]# tcpdump -i eth0 -nn |
- 17:01:47.362139:此封包被擷取的時間,『時:分:秒』的單位;
- IP:透過的通訊協定是 IP ;
- 192.168.1.100.22 > :傳送端是 192.168.1.100 這個 IP,而傳送的 port number 為 22,大於 (>) 的符號指的是封包的傳輸方向
- 192.168.1.101.1937:接收端的 IP 是 192.168.1.101, 主機開啟 port 1937 來接收;
- [P.], seq 196:472:這個封包帶有 PUSH 的資料傳輸標誌, 且傳輸的資料為整體資料的 196~472 byte;
- ack 1:ACK 的相關資料。
- 簡單來說, 該封包是由 192.168.1.100 傳到 192.168.1.101,透過的 port 是由 22 到 1937 , 使用的是 PUSH 的旗標,而不是 SYN 之類的主動連線標誌
只取 port 21
[root@www ~]# tcpdump -i eth0 -nn port 21 |
- 封包的傳遞都是雙向的, client 端發出『要求』而 server 端則予以『回應』
監聽本地 localhost 試驗
我們先在一個終端機視窗輸入『 tcpdump -i lo -nn 』 的監聽,
再另開一個終端機視窗來對本機 (127.0.0.1) 登入『ssh localhost』
[root@www ~]# tcpdump -i lo -nn |
- 第 3 行顯示的是『來自 client 端,帶有 SYN 主動連線的封包』,
- 第 4 行顯示的是『來自 server 端,除了回應 client 端之外(ACK),還帶有 SYN 主動連線的標誌;
- 第 5 行則顯示 client 端回應 server 確定連線建立 (ACK)
- 第 6 行以後則開始進入資料傳輸的步驟。
nmap
語法
[root@www ~]# nmap [掃瞄類型] [掃瞄參數] [hosts 位址與範圍] |
範例
使用預設參數掃瞄本機所啟用的 port (只會掃瞄 TCP)
[root@www ~]# yum install nmap |
同時掃瞄本機的 TCP/UDP 埠口
[root@www ~]# nmap -sTU localhost |
透過 ICMP 封包的檢測,分析區網內有幾部主機是啟動的
[root@www ~]# nmap -sP 192.168.1.0/24 |
dig
語法
[root@www ~]# dig [options] FQDN [@server] |
範例
使用預設值查詢 linux.vbird.org
[root@www ~]# dig linux.vbird.org |
查詢 linux.vbird.org 的 SOA 相關資訊
[root@www ~]# dig -t soa linux.vbird.org |
rsync
範例:
- 同步 A 資料夾的內容到 B 資料夾, 不要同步
.git資料夾rsync -avz --exclude .git sourceDirectory/ targetDirectory
- -a: 同步權限
- -v: 顯示過程詳細訊息
- -z: 過程中壓縮
Q&A
- apt 底層包的是? dpkg
- dpkg 安裝 package 時, 會將 *.deb 放在? /var/cache/apt/archives/
- 路由的排列有順序之分嗎? 有哦
- 路由排列的規則? 由小網域到大網域
修改 default system editor
到 ~/.bashrc
export SYSTEMD_EDITOR=vim |
然後到 visudo 中
sudo visudo |
加入以下
Defaults env_keep += "SYSTEMD_EDITOR" |
大功告成
留言